defget_query(filters, starttime=None, endtime=None, sort=True, timestamp_field='@timestamp', to_ts_func=dt_to_ts, desc=False, five=False): """ Returns a query dict that will apply a list of filters, filter by start and end time, and sort results by timestamp. :param filters: A list of Elasticsearch filters to use. :param starttime: A timestamp to use as the start time of the query. :param endtime: A timestamp to use as the end time of the query. :param sort: If true, sort results by timestamp. (Default True) :return: A query dictionary to pass to Elasticsearch. """ starttime = to_ts_func(starttime) endtime = to_ts_func(endtime) filters = copy.copy(filters) es_filters = {'filter': {'bool': {'must': filters}}} if starttime and endtime: es_filters['filter']['bool']['must'].insert(0, {'range': {timestamp_field: {'gt': starttime, 'lte': endtime}}}) if five: query = {'query': {'bool': es_filters}} else: query = {'query': {'filtered': es_filters}} if sort: query['sort'] = [{timestamp_field: {'order': 'desc'if desc else'asc'}}] return quer
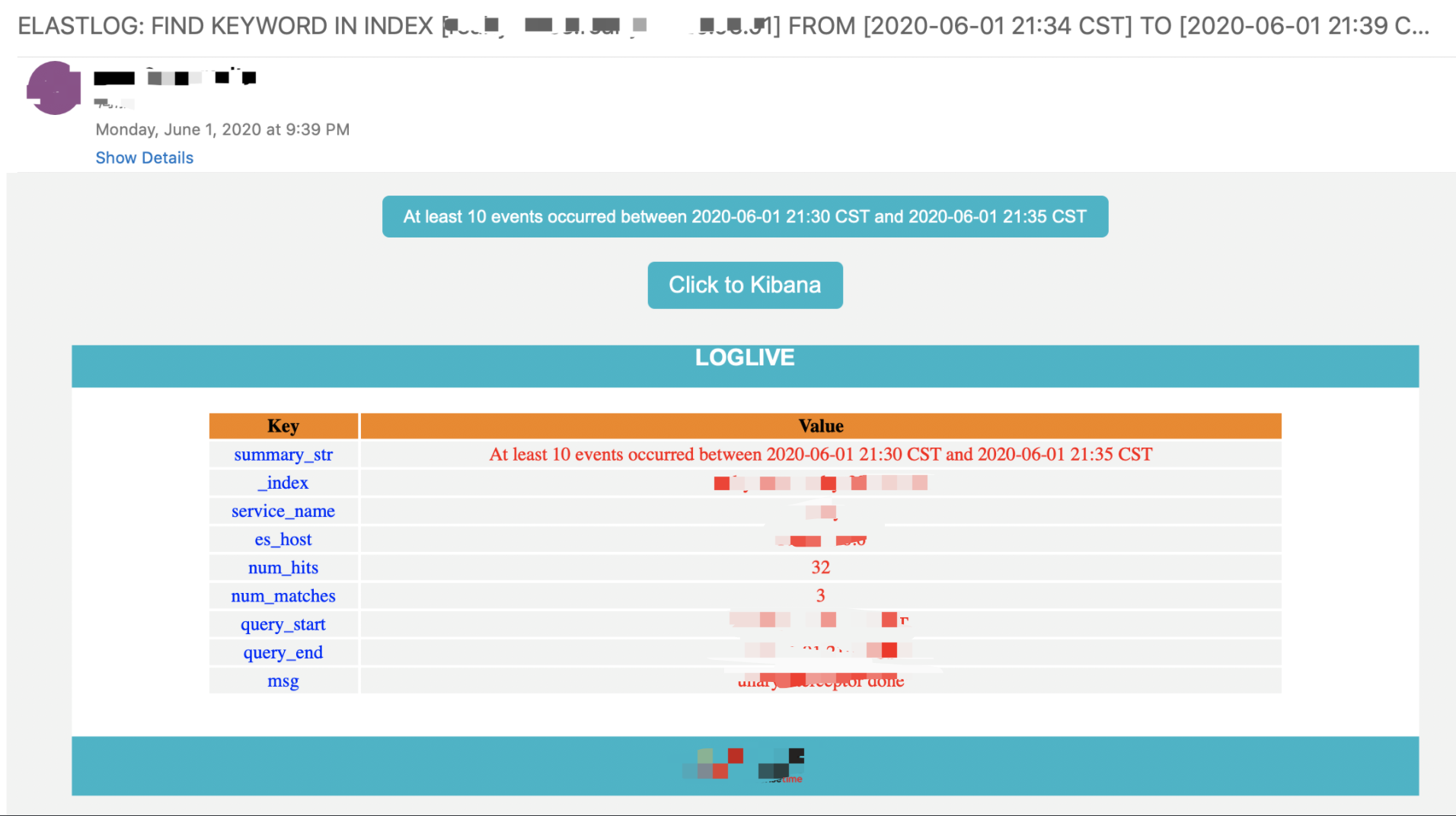
num_hits is the number of documents returned by elasticsearch for a given query. num_matches is how many times that data matched your rule, each one potentially generating an alert.
If it makes a query over a 10 minute range and gets 10 hits, and you have
type: frequency num_events: 10 timeframe: minutes: 10 then you'll get 1 match. 总结: num_hits表示的是根据filter条件及查询时间段从es返回的记录,而num_matches表示的是预计会产生多少条报警 因此 num_matches = num_hits / num_events, 会四舍五入,所以在告警内容中会发现两者都是这样的关系
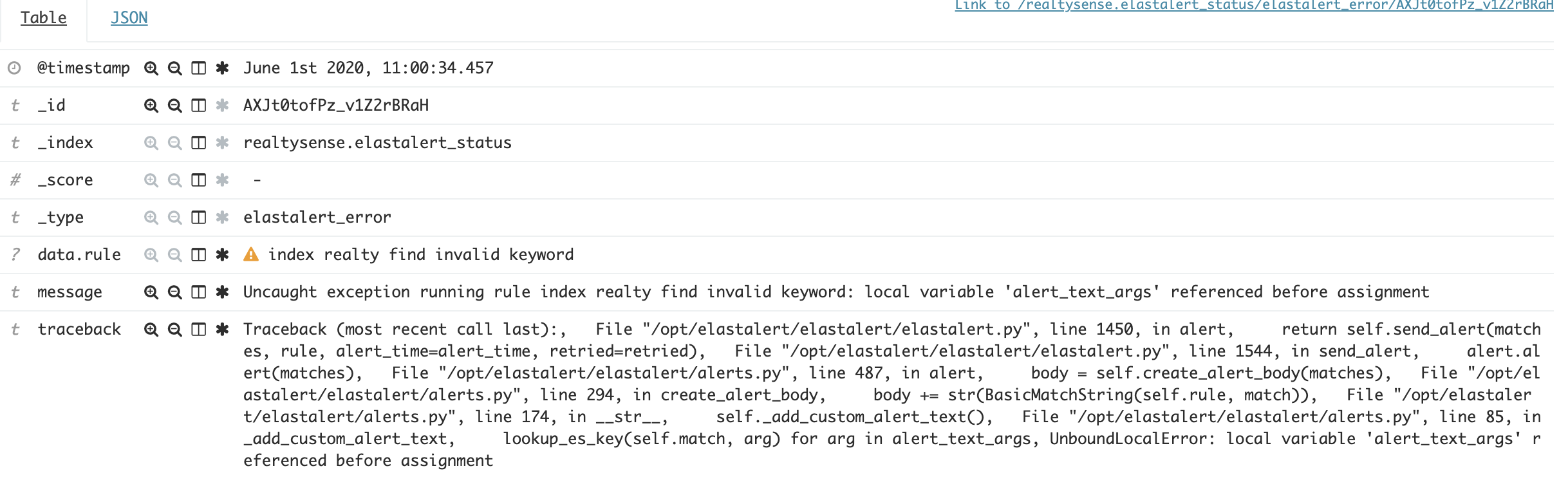
classBasicMatchString(object): """ Creates a string containing fields in match for the given rule. """ def__init__(self, rule, match, alert_type): # 新增一个alert_type,为告警类型 self.rule = rule self.match = match self.alert_type = alert_type @staticmethod defrender_html(summary_str, data): env = Environment(loader=FileSystemLoader( os.path.join(os.path.dirname(__file__), "templates"))) template = env.get_template('mail.html.tpl') out = template.render(summary_str=summary_str, data=data) #with open('mail.html', 'w', encoding='utf-8') as f: # f.write(out) return out def_add_custom_alert_text(self): missing = self.rule.get('alert_missing_value', '<MISSING VALUE>') if'alert_text_args'in self.rule: alert_text_args = self.rule.get('alert_text_args') # 判断告警的类型 if'email' == self.alert_type: summary_str = self.rule['type'].get_match_str(self.match) alert_text = str(self.render_html(summary_str, alert_text_args)) # 如果不是email则保存跟源码一致 else: alert_text = str(self.rule.get('alert_text', '')) # ...
由于所有的告警类型的基类都是Alerter,因此通过这个来传递告警类型.
1 2 3 4 5 6 7 8 9 10 11 12
classAlerter(object): #... defcreate_alert_body(self, matches): alert_type = self.get_info()['type'] # 通过get_info 获取alerter实例的type body = self.get_aggregation_summary_text(matches) if self.rule.get('alert_text_type') != 'aggregation_summary_only': formatchin matches: body += str(BasicMatchString(self.rule, match, alert_type)) # 传入BasicMatchString # Separate text of aggregated alerts with dashes iflen(matches) > 1: body += '\n----------------------------------------\n' return body
这样就完成自定义邮件格式了,模板如下:
字段直接在rule文件中alert_text_args中传入即可.
微信报警
elastalert本身支持自定义的告警接入,只需要实现 body = self.create_alert_body(matches)方法即可.不难,难点在于企业微信api如何使用, 代码参考elastalert-wechat-plugin, 亲测可用.