Kubernetes学习(关于CoreDNS的5s超时问题)
今天同事反映了一个很奇怪的问题: 在k8s环境里的容器中curl另一个服务时会出现断断续续的超时, 问题现象很简单, 但问题根源很复杂
环境说明
1 | Kubernetes-1.15.1 |
问题现象
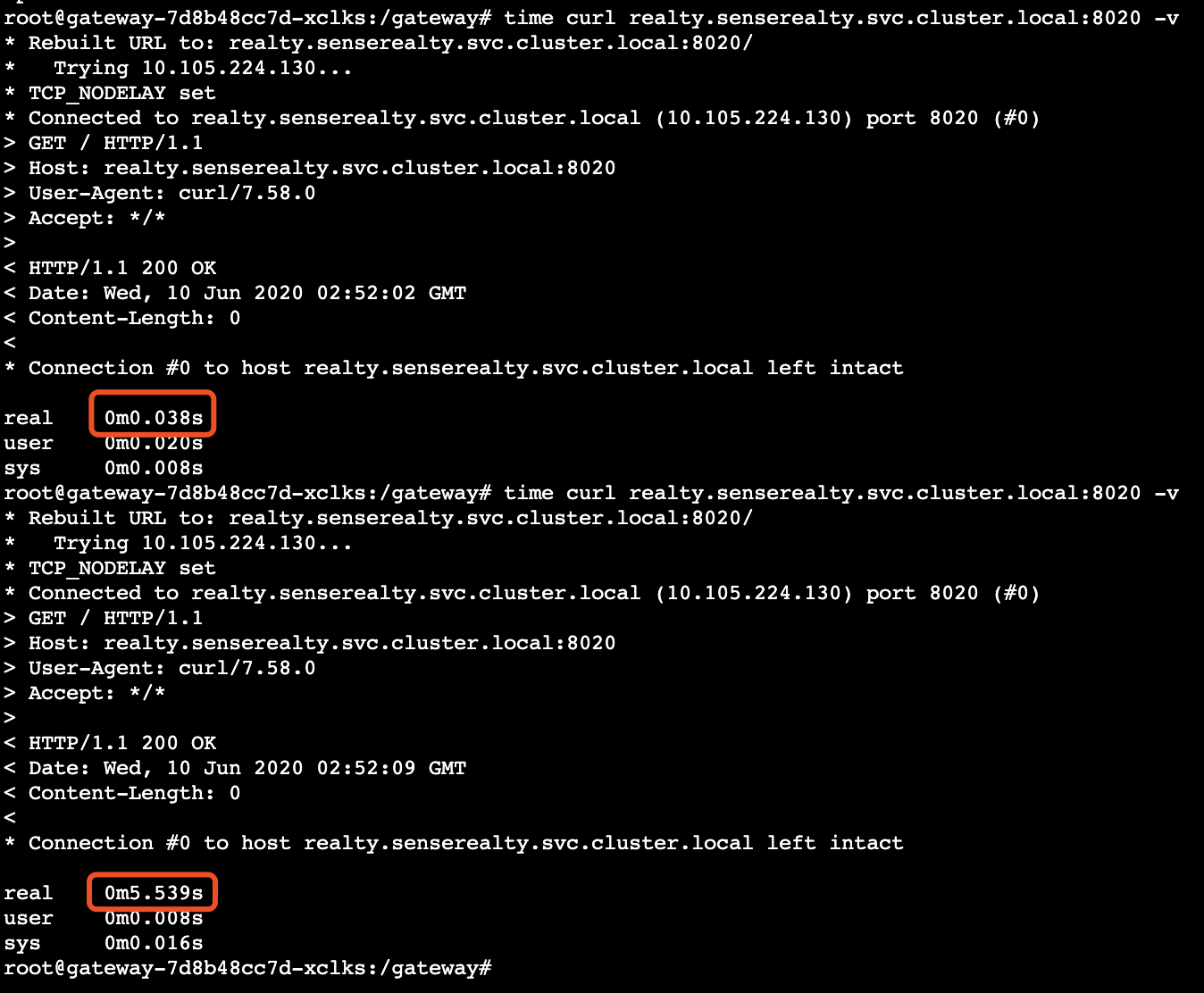
排查过程
Services
首先很容易想到, 因为现象是时好时坏,是不是有可能服务中有某一个节点不正常, 排查一圈后,涉及的服务都未见异常.
ClusterIP
既然服务都正常, 那会不会是解析有问题, 因为coreDNS也是多实例的, 因此直接通过ClusterIP访问, 未见超时,因此可以判断是解析环节出现问题
CoreDNS
在确认是解析环节的问题后, 就从coreDNS入手了, coreDNS的运行情况未见异常, 日志也不见错误输出, 打开debug日志后,再次观察
也未见任何错误日志,这就奇怪了, 没办法,只能tcpdump了
Tcpdump
只需要看53端口的流量即可, 通过tcpdump抓到包后,也并未发现在任何可疑的地方. 本来寄希望于神器, 却什么都没发现,这就尴尬了
Kube-proxy
由于dns的实现是通过kube-proxy实现的, 因此kube-proxy的差异也会引起转发异常, 但是通过比对两台宿主机的iptables,也一样, 这就排除了kube-proxy的问题
Why 5s
其实从现象来看, 我第一想到的是这个5s很熟悉, 因为之前优化过DNS服务器重试的问题, 记得默认的超时时间就是5s, 所以很容易想到了
这里需要简单地说一下k8s中的服务名字 –>实例IP的一个的流程:
ServiceName –> coreDNS ClusterIP –> coreDNS instance –> ClusterIP –> Service instance
测试了从coreDNS ClusterIP --> coreDNS instance的解析是没有问题的,因此问题出现coreDNS instance --> ClusterIP
那么单独通过coreDNS的两个实例去解析, 会发现有一个实例确实会出现5s Timeout的情况,另一个实例没有问题.
对比了两个实例所在的宿主机, 跟dns相关的/etc/resolv.conf,/etc/sysctl.conf等有关系的文件,没有差别
这就很奇怪了, 几乎相关的组件都排查了,并没有发现可疑的地方, 没办法,只能网上查看是否有相关的issue.
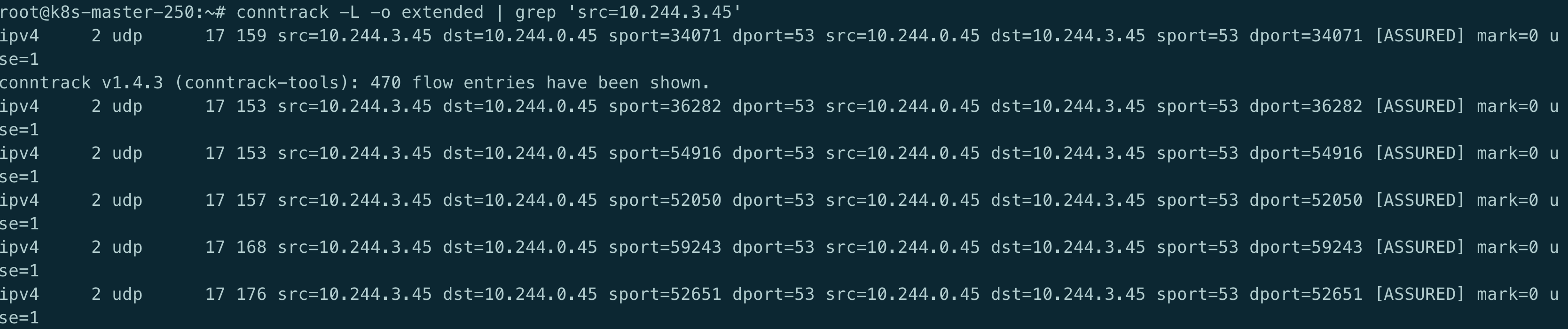
Conntrack
经过一番搜索, 还真发现是踩到了一个坑, 倒不是k8s的问题, 而是conntrack的一个bug.
关于conntrack, 涉及到内核的一些知识,没办法搞的太深,太深了也看不太懂, 大家可自行了解
这里就参考这里总结一下:
当加载内核模块nf_conntrack后,conntrack机制就开始工作,如上图,椭圆形方框conntrack在内核中有两处位置(PREROUTING和OUTPUT之前)能够跟踪数据包。对于每个通过conntrack的数据包,内核都为其生成一个conntrack条目用以跟踪此连接,对于后续通过的数据包,内核会判断若此数据包属于一个已有的连接,则更新所对应的conntrack条目的状态(比如更新为ESTABLISHED状态),否则内核会为它新建一个conntrack条目。所有的conntrack条目都存放在一张表里,称为连接跟踪表
连接跟踪表存放于系统内存中,可以用cat /proc/net/nf_conntrack, ubuntu则是conntrack命令查看当前跟踪的所有conntrack条目
Prombles
经过一番参考之后, 发现问题的根源在于:
DNS client (glibc 或 musl libc) 会并发请求 A (ipv4地址) 和 AAAA (ipv6地址)记录,跟 DNS Server 通信自然会先 connect (建立fd),后面请求报文使用这个 fd 来发送,由于 UDP 是无状态协议, connect 时并不会创建 conntrack 表项, 而并发请求的 A 和 AAAA 记录默认使用同一个 fd 发包,这时它们源 Port 相同,当并发发包时,两个包都还没有被插入 conntrack 表项,所以 netfilter 会为它们分别创建 conntrack 表项,而集群内请求 kube-dns 或 coredns 都是访问的CLUSTER-IP,报文最终会被 DNAT 成一个 endpoint 的 POD IP,当两个包被 DNAT 成同一个 IP,最终它们的五元组就相同了,在最终插入的时候后面那个包就会被丢掉,如果 dns 的 pod 副本只有一个实例的情况就很容易发生,现象就是 dns 请求超时,client 默认策略是等待 5s 自动重试,如果重试成功,我们看到的现象就是 dns 请求有 5s 的延时,
netfilter conntrack 模块为每个连接创建 conntrack 表项时,表项的创建和最终插入之间还有一段逻辑,没有加锁,是一种乐观锁的过程。conntrack 表项并发刚创建时五元组不冲突的话可以创建成功,但中间经过 NAT 转换之后五元组就可能变成相同,第一个可以插入成功,后面的就会插入失败,因为已经有相同的表项存在。比如一个 SYN 已经做了 NAT 但是还没到最终插入的时候,另一个 SYN 也在做 NAT,因为之前那个 SYN 还没插入,这个 SYN 做 NAT 的时候就认为这个五元组没有被占用,那么它 NAT 之后的五元组就可能跟那个还没插入的包相同
所以总结来说,根本原因是内核 conntrack 模块的 bug,DNS client(在linux上一般就是resolver)会并发地请求A 和 AAAA 记录netfilter 做 NAT 时可能发生资源竞争导致部分报文丢弃
这篇post有非常详细的解释,建议大家都好好地读一读racy conntrack and dns lookup timeouts
post的相关结论:
- 只有多个线程或进程,并发从同一个 socket 发送相同五元组的 UDP 报文时,才有一定概率会发生
- glibc, musl(alpine linux的libc库)都使用 “parallel query”, 就是并发发出多个查询请求,因此很容易碰到这样的冲突,造成查询请求被丢弃
- 由于 ipvs 也使用了 conntrack, 使用 kube-proxy 的 ipvs 模式,并不能避免这个问题
Resolve
Use TCP
默认情况下, dns的请求一般都是使用UDP请求的, 因为力求效率,不需要三握四挥
由于TCP没有这个问题,有人提出可以在容器的resolv.conf中增加options use-vc, 强制glibc使用TCP协议发送DNS query。下面是这个man resolv.conf中关于这个选项的说明:
1 | use-vc (since glibc 2.14) |
缺点是使用tcp会比udp稍慢
single-request-reopen/sing-request
resolv.conf还有另外两个相关的参数:
- single-request-reopen (since glibc 2.9)
- single-request (since glibc 2.10)
man resolv.conf中解释如下:
1 | single-request-reopen (since glibc 2.9) |
single-request-reopen: 发送 A 类型请求和 AAAA 类型请求使用不同的源端口,这样两个请求在 conntrack 表中不占用同一个表项,从而避免冲突single-request: 避免并发,改为串行发送 A 类型和 AAAA 类型请求,没有了并发,从而也避免了冲突
所以需要将参数写入到容器的/etc/resolv.conf中, 那么也有几种办法
对于已经上线运行的容器可以直接修改yaml定义
1 | template: |
也可以直接写到启动命令中
1 | lifecycle: |
再或者直接通过Entrypoint/CMD写入
/bin/echo 'options single-request-reopen' >> /etc/resolv.conf
musl libc
前几种方案是 glibc 支持的,而基于 alpine 的镜像底层库是 musl libc 不是 glibc,所以即使加了这些 options 也没用,因此如果是通过alpine构建的镜像,当然也有解决办法,网上推荐使用本地DNS的方式,也就是每个节点都部署一个本地的dns, 容器直接请求本的dns,不需要走 DNAT,也不会发生 conntrack 冲突。另外还有个好处,就是避免 DNS 服务成为性能瓶颈
NodeLocal DNScache(k8s v1.15中的beta),这已在k8s官方文档中进行了详细介绍。该解决方案旨在通过作为DaemonSet在每个节点上运行DNS缓存代理来提高群集上的总体DNS性能,以便Pod可以与在同一节点上运行的这些代理联系,从而减少仍然使用conntrack发生竞争的可能性
当然,这个需要集群版本在1.15以上,如果低于这个版本使用其它的dns加速工具如dnsmasq nscd等也可以实现本地dns缓存,但部署起来会比较复杂
当然也可以直接设置 POD.spec.dnsPolicy 为 “Default”, 意思是POD里面的 /etc/resolv.conf是从宿主机上的 /etc/resolv.conf继承而来,这样宿主机上的所有pod都会将宿主机上的/etc/resolv.conf直接挂载到容器内.这样也能解决问题
- “
Default“: The Pod inherits the name resolution configuration from the node that the pods run on. See related discussion for more details. - “
ClusterFirst“: Any DNS query that does not match the configured cluster domain suffix, such as “www.kubernetes.io“, is forwarded to the upstream nameserver inherited from the node. Cluster administrators may have extra stub-domain and upstream DNS servers configured. See related discussion for details on how DNS queries are handled in those cases.
如果想尽快解决问题的话,个人还是建议直接更换alpine镜像, 基于alpine构建的镜像还是有挺多坑的.
getaddrinfo()、gethostbyname()
关于A与AAAA, 有两个很常用的函数, 之前也有用过, 但是从来没有关注过这两者的区别
getaddrinfo()会返回A与AAAA的记录, 如果其中任一个没有返回,都将超时重试
而gethostbyname()只会返回A记录
参考文章:
- https://tencentcloudcontainerteam.github.io/
- https://dzone.com/articles/racy-conntrack-and-dns-lookup-timeouts
- https://www.bookstack.cn/read/kubernetes-practice-guide/troubleshooting-cases-dns-lookup-5s-delay.md
- https://tencentcloudcontainerteam.github.io/
- https://unix.stackexchange.com/questions/141163/dns-lookups-sometimes-take-5-seconds
- https://blog.codacy.com/dns-hell-in-kubernetes/
- https://opengers.github.io/openstack/openstack-base-netfilter-framework-overview/