cilium在kubernetes中的生产实践三(cilium网络模型之关键配置)
在前东家的时候其实就有意将cilium强大的链路追踪能力集成到生产环境中,各种因素导致没有很大信心落地, 经过深入调研(也就把官网docs翻了四五遍)及测试, 终于有机会在生产kubernetes集群中(目前一个集群规模不算很大,2w+核心,持续增长)使用cilium做为cni,同时替换kube-proxy, 到现在已经有一段时间了,也算是有生产经验可以跟大家聊一聊这个工具,使用体验总结一句话: 轻松愉悦.
分享一下整个落地过程,同时也总结下方方面面, 工作之余尽量更新.
此篇为: cilium在kubernetes中的生产实践三(cilium网络模型之关键配置)
总体分为以下几块内容:
cilium在kubernetes中的生产实践一(cilium介绍)
cilium在kubernetes中的生产实践二(cilium部署)
cilium在kubernetes中的生产实践三(cilium网络模型之关键配置)
cilium在kubernetes中的生产实践四(cilium网络模型之生产实践)
cilium在kubernetes中的生产实践五(cilium网络策略)
cilium在kubernetes中的生产实践六(cilium排错指南)
cilium在kubernetes中的生产实践七(cilium中的bpf hook)
本节,会详细介绍一下cilium的网络模型中的一些关键参数及相关参数的配置及这些参数的必要条件, 在一些场景下,这些参数的启停对网络性能有很大影响
Routing(路由)
开始先说一说路由, 各节点之前互通是kubernetes对CNI的通用要求, 但集群节点上的pod通信要通过什么样的方式路由到其它节点上呢? 在cilium中有多种选择:
- Encapsulation(封装)
这个相信对大家不陌生了, 最常见的vxlan就属于这种
在未提供任何配置的情况下,Cilium会自动以这种模式运行,因为这种模式对底层网络基础设施的要求最低
在这种模式下,所有集群节点都会使用基于 UDP 的封装协议VXLAN或Geneve形成网状隧道。Cilium 节点之间的所有流量都经过封装.
不过这种模式的缺点,由于要封装额外的协议头,提高了MTU开销,不过这个可以通过开启巨帧网络来降低影响.
由于增加了封装头,有效载荷可用的 MTU 要低于本地路由(VXLAN 每个网络数据包 50 字节)。这导致特定网络连接的最大吞吐率降低。
注:
这里简单说一下Encapsulation vs Masquerading(下文会介绍)的区别:
Encapsulation翻译过来是封装/包装,就是把AAA封装到BBB里, 它是一种叠加的过程
而Masquerading翻译过来是伪装的, 它则是把AAA转变成BBB,是一种替换的过程, 最常见的如NAT,存在IP伪装
- Native-Routing(原生路由)
Native-Routing网上的文档有不同的译法,被翻译成原生路由或者本地路由,作者觉得原生路由更贴合一些
在原生路由模式下,Cilium将把所有未寻址到另一个本地端点的数据包委托给Linux内核的路由子系统。这意味着数据包将被路由,就像本地进程发出数据包一样。因此,连接群集节点的网络必须能够路由PodCIDR。
再简单来说就是所有节点对所有pod的ip是可寻址的
可寻址以通过两种方式实现:- 节点本身不知道如何路由所有pod IP,但网络上有路由器知道如何到达所有其他pod。在这种情况下,Linux 节点被配置为包含指向此类路由器的默认路由。这种模式用于云提供商网络集成
- 每个节点都知道所有其他节点的所有pod IP,并在Linux内核路由表中插入路由来表示这一点。
如果所有节点共享一个L2网络,则可以启用选项auto-direct-node-routes: true来解决这个问题。如果kubernetes节点并非在同一个L2网络上,则需要BGP daemon组件的辅助。
配置原生路由时,Cilium会自动在Linux内核中启用IP转发
开启原生路由,表明cilium不能工作在任一隧道模式中
开启native-routing的方式如下:
1 | --set tunnel=disabled |
注:
在cilium中还有一个词很常见: host-routing(主机路由,下文会介绍), 也是个很重要的性能优化点,这里只简单说一说host-routing vs native-routing区别:
native-routing说的是跨主机的pod间是如何导址访问的
而host-routing则说的是网络数据是否会绕过iptables和上层主机堆栈,以实现比常规veth 设备操作更快的网络命名空间切换
所以这两个完全是不同的二个概念, 很容易混淆
- 还有一些是在特定云厂商集群环境下才会用的路由方式,这里不过多介绍.
所以总结来说,如果想要更佳的网络性能,选择native-routing是个不错的选择
如果集群网络复杂, 可以使用Encapsulation,虽然有点性能损耗,好在任何网络都可满足条件, 只需要node间互通.
IPAM
cilium做为CNI, 自然需要具备为集群node上的pod分配地址段的能力, 这部分直接使用cilium默认的选项即可
在部署时指定ipam.Operator.clusterPoolIPv4PodCIDRList=10.244.0.0/16及ipam.Operator.ClusterPoolIPv4MaskSize=24即可
最终, 每个node所具备的pod ip pool将会以CiliumNode这种CRD的形式存在,可通过以下命令查看
1 | kubectl get cn # cn代表ciliumNode |
Masquerading(伪装)
通常情况下, pod的ip在集群外是不可寻址的,所以从pod里访问集群外的资源, 在网络协议里需要把pod IP masquerading成node IP, 这样网络请求来回时才可对应上, 这是典型的iptables mode,会降低网络性能
而基于eBPF mode是一种更加高效的masquerading技术
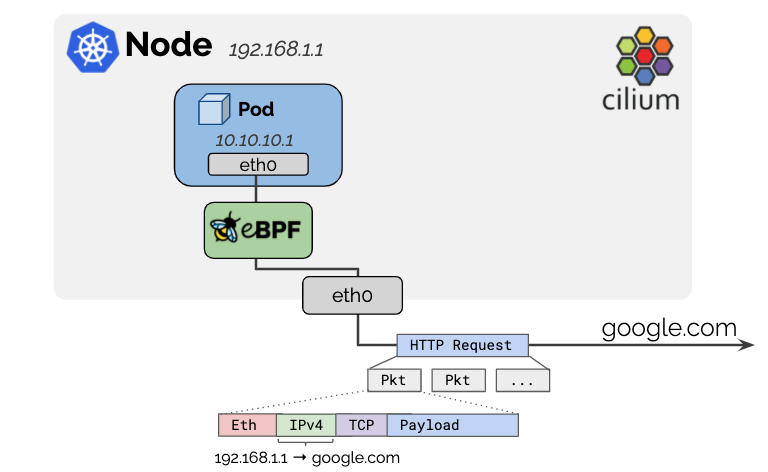
eBPF-based masquerading时需要具备如下条件:
- Linux kernel 4.19+
- BPF NodePort特性(即在相应的网络接口上需要开启nodeport)
在安装cilium时通过指定如下参数: bpf.masquerade=true开启
如果上述条件不满足,就算是开启了bpf.masquerade=true,也无法使用, cilium会自动回退到iptables的方式
可通过如下命令确认masquerading属处的mode
1 | cilium status --verbose |
Host-Routing(主机路由)
即使Cilium使用eBPF执行网络路由,默认情况下,网络数据包仍然会遍历节点的常规网络堆栈的某些部分。这就导致了所有数据包仍能通过所有iptables钩子而增加了开销。
在Cilium 1.9中引入了基于eBPF的主机路由,以完全绕过iptables和上层主机堆栈,并实现比常规veth设备操作更快的网络命名空间切换.
host-routing 分为Legacy mode及BPF mode,
BPF mode要求如下:
- Kernel >= 5.10
- Direct-routing configuration or tunneling
- eBPF-based kube-proxy replacement
- eBPF-based masquerading
可通过如下命令确认masquerading属处的mode
1 | cilium status --verbose |
如果内核支持BPF.则会自动启用它.如果不满足BPF mode,则会自动回退到Legacy mode
不过从实践来看, Kernel>=5.10应该不是必须, 作者的集群 node kernel=4.19时, 也可开启host-routing BPF
DSR(直接服务返回)
默认情况下,Cilium的eBPF NodePort实现在SNAT模式下运行。也就是说,当节点外部流量到达节点LoadBalancer、NodePort或具有externalIP的服务后端位于远程节点时(即该服务的pod没有部署在请求到达的这台node上),则节点通过执行SNAT将请求重定向到远程后端。这不需要任何额外的MTU更改。代价是来自后端的回复需要进行额外的跳回到该节点,以在将数据包直接返回到外部客户端之前在那里执行反向SNAT转换。
可以通过loadBalancer.mode Helm选项将此设置更改为dsr,以便让Cilium的eBPFNodePort实现在DSR模式下运行。在DSR模式下,后端直接回复外部客户端,而不需要额外的跳,这意味着后端使用服务IP/端口作为源进行回复。
DSR的前置要求为:
- 需要cilimi开启Native-Routing.
DSR模式的另一个优点是客户端的源IP被保留,因此策略可以在后端节点上与之匹配。在SNAT模式下,这是不可能的。给定一个特定的后端可以被多个服务使用,后端需要知道它们需要回复的服务IP/端口。因此,Cilium在Cilium特定的IPv4选项或IPv6目的地选项扩展报头中编码此信息,代价是较低的MTU。对于TCP服务,Cilium只对SYN数据包的服务IP/端口进行编码,而不对后续数据包进行编码。后者还允许在混合模式下操作Cilium,其中DSR用于TCP,SNAT用于UDP,以避免另外需要的MTU减少
请注意,DSR模式在某些公共云提供商环境中可能无法使用,原因是底层网络结构可能会丢弃特定于Cilium的IP选项。如果后端位于处理给定NodePort请求的节点的远程节点上的服务的连接问题,首先检查NodePort请求是否实际到达包含后端的节点。如果不是这种情况,则建议切换回默认SNAT模式作为一种解决方法
总结就是, DSR有利于提高服务响应时间
socketLB
socketLB也是一个很实用的功能,旨在将BPF程序attach到socket的系统调用hooks,使客户端直接和后端pod建连和通信, 但socketLB需要cgroup v2的支持, 相信大多数的生产环境还是在用cgroup v1, 因此这里将不进行socketlb的实践.
vxlan下的虚拟网口
在默认部署方式下,使用vxlan的overlay组网情况,主机上的网络会发生了以下变化,在主机的 root 命名空间,新增了如下图所示的四个虚拟网络接口,
- cilium_vxlan: 主要是对数据包进行vxlan封装和解封装操作
- cilium_net和cilium_host: 是一对 veth-pair, 一端插在主机上,一端插在容器里
- cilium_host: 作为该节点所管理的Cluster IP子网的网关,容器中使用ip a看到的eth0的网卡的形式就eth0@xxx, xxx与宿主机上的一个lxcxxxx@ifxxx相对应,一般为正负1的关系
可以通过以下cilium命令查看相关的vxlan tunnel
1 | cilium bpf tunnel list # 查看各个节点的vxlan tunnel |
暴露服务
还有一个很常见的场景是,需要在集群外访问集群内的服务, 当然直接使用原生的nodeport是最直接的, 在cilium中还提供了一个很重要的选择: lbExternalClusterIP, 用于是否开启集群外对集群内资源的访问,
也很简单,只需要二步:
- 集群外可访问得到集群内资源的ip(podIP或者是serviceIP)
- 设置cilium的
bpf.lbExternalClusterIP=true
但需要注意的是这种方式是开启所有服务可在集群外访问,相对于nodeport按需开启在安全方面会弱一些
参考文章:
- https://cilium.io
- https://www.infoq.cn/article/p9vG2G9T49KpvHrckFwu
- https://www.cnblogs.com/charlieroro/p/13403672.html
- https://zhuanlan.zhihu.com/p/404278920
- http://arthurchiao.art/blog/understanding-ebpf-datapath-in-cilium-zh/
- https://podsbook.com/posts/cilium/xdp/
- https://mdnice.com/writing/4429d86bf8dc42d1a42f60ae7b873f6a
- https://mp.weixin.qq.com/s/KSWrvOmKeX-74RU5d6NUlQ
- http://www.sel.zju.edu.cn/blog/2022/12/01/cilium-kind-setup/
- https://blog.51cto.com/liujingyu/5285535
- https://zhuanlan.zhihu.com/p/594084783
- https://izsk.me/2023/04/01/cilium-on-kubernetes-introduction/
- https://izsk.me/2023/06/03/cilium-on-kubernetes-install/