cilium在kubernetes中的生产实践一(cilium介绍)
在前东家的时候其实就有意将cilium强大的链路追踪能力集成到生产环境中,各种因素导致没有很大信心落地, 经过深入调研(也就把官网docs翻了四五遍)及测试, 终于有机会在生产kubernetes集群中(目前一个集群规模不算很大,2w+核心,持续增长)使用cilium做为cni,同时替换kube-proxy, 到现在已经有一段时间了,也算是有生产经验可以跟大家聊一聊这个工具,使用体验总结一句话: 轻松愉悦.
分享一下整个落地过程,同时也总结下方方面面, 工作之余尽量更新.
此篇为: cilium在kubernetes中的生产实践一(cilium介绍)
总体分为以下几块内容:
cilium在kubernetes中的生产实践一(cilium介绍)
cilium在kubernetes中的生产实践二(cilium部署)
cilium在kubernetes中的生产实践三(cilium网络模型之关键配置)
cilium在kubernetes中的生产实践四(cilium网络模型之生产实践)
cilium在kubernetes中的生产实践五(cilium网络策略)
cilium在kubernetes中的生产实践六(cilium排错指南)
cilium在kubernetes中的生产实践七(cilium中的bpf hook)
eBPF
现在很火的技术eBPF,相信大家都有所耳闻,cilium就是在eBPF的技术之上构建的功能强大工具, eBPF技术不是本文的重点,因此不详细展开,引用网上一个比较通俗的概述:
**eBPF(extended Berkeley Packet Filter)**是一套通用执行引擎,提供了可基于系统或程序事件高效安全执行特定代码的通用能力,通用能力的使用者不再局限于内核开发者;eBPF 可由执行字节码指令、存储对象和 Helper 帮助函数组成,字节码指令在内核执行前必须通过 BPF Verfier 的验证,同时在启用 BPF JIT 模式的内核中,会直接将字节码指令转成内核可执行的本地指令运行
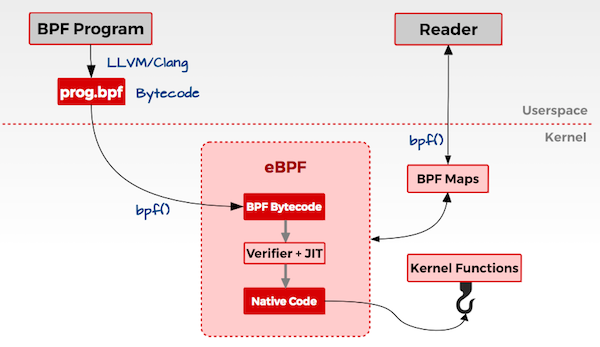
由于不需要修改内核就可以完成原本要在内核才能做到的事情,因此功能强大,eBPF也逐渐在观测、跟踪、性能调优、安全和网络等领域发挥重要的角色
cilium
回到本文的主角: cilium
一个多么痛的领悟: 当kubernetes发展到一定规模后,维护的成本也跟随升高, 特别是在某些链路很长,网络很复杂的场景下,
(对,说的就是本人目前在维的集群)对在网络的deubg, 链路可观测方面提出更高要求, 但这恰恰是eBPF的强项,
Google更是宣布使用Cilium 作为 GKE 的下一代数据面, 作为第一个通过ebpf实现了kube-proxy所有功能的网络插件,那cilium到底有什么魔力呢?
摘一段官网的介绍:
Cilium is open source software for transparently securing the network connectivity between application services deployed using Linux container management platforms like Docker and Kubernetes
因此: 当在kubernetes中需要开箱即用解决以下问题时:
服务依赖关系和通信图
- 哪些服务正在相互通信?有多频繁?服务依赖关系图是什么样子的?
- 正在进行哪些HTTP调用?服务从哪些Kafka主题消费或生产到哪些Kafka主题?
网络监控和警报
- 是否有网络通信故障?为什么通信失败?是DNS吗?是应用程序问题还是网络问题?第4层(TCP)或第7层(HTTP)上的通信是否中断?
- 哪些服务在过去5分钟内遇到了DNS解析问题?哪些服务最近遇到了TCP连接中断或连接超时?未应答TCP SYN请求的速率是多少?
应用程序监控
- 特定服务或所有群集中5xx或4xx HTTP响应代码的比率是多少?
- 在集群中,HTTP请求和响应之间的第95和第99百分位延迟是多少?哪些服务性能最差?两个服务之间的延迟是多少?
安全可观察性
- 哪些服务的连接因网络策略而被阻止?从群集外部访问了哪些服务?哪些服务解析了特定的DNS名称?
借助cilium,都可以得到答案。
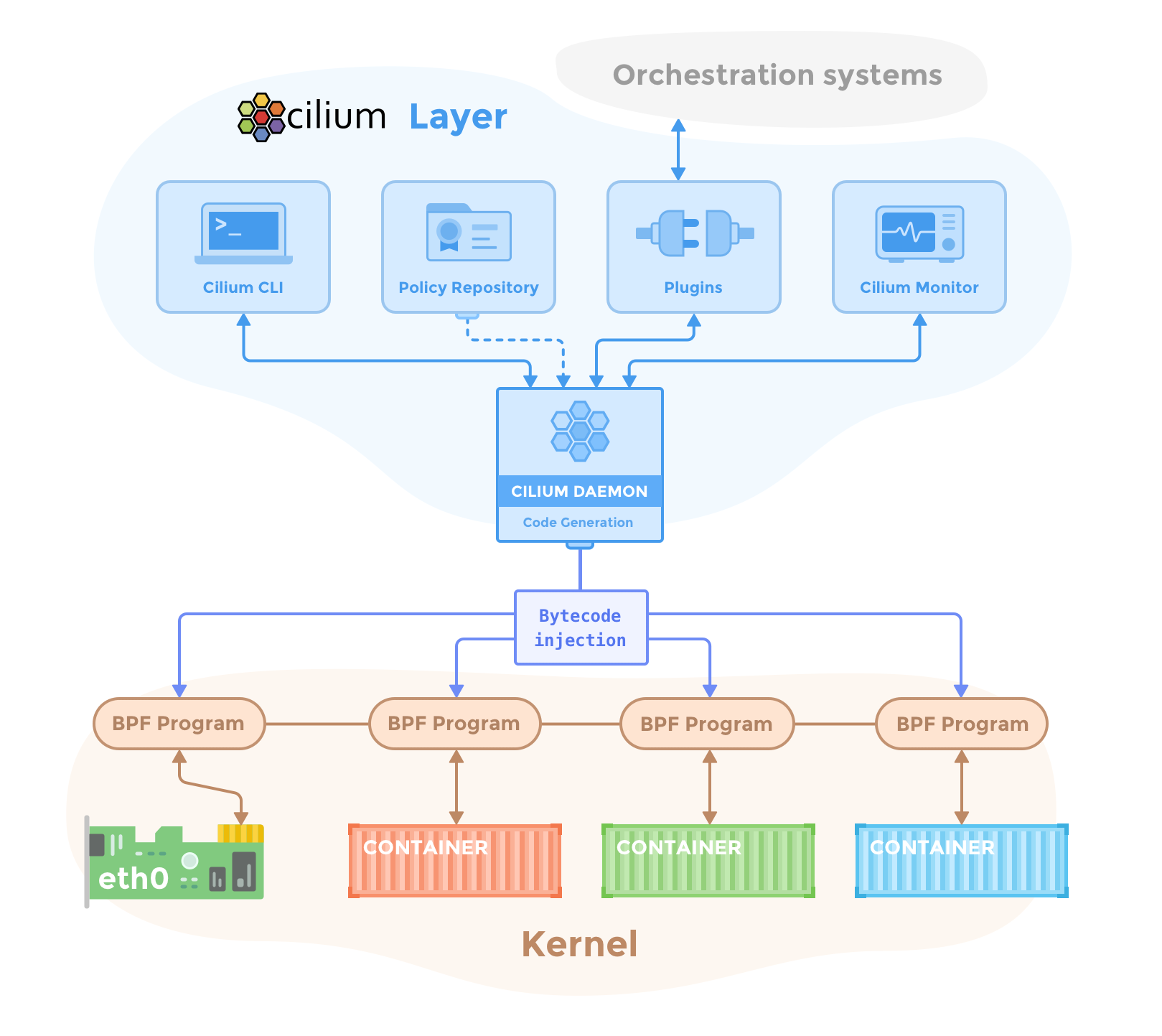
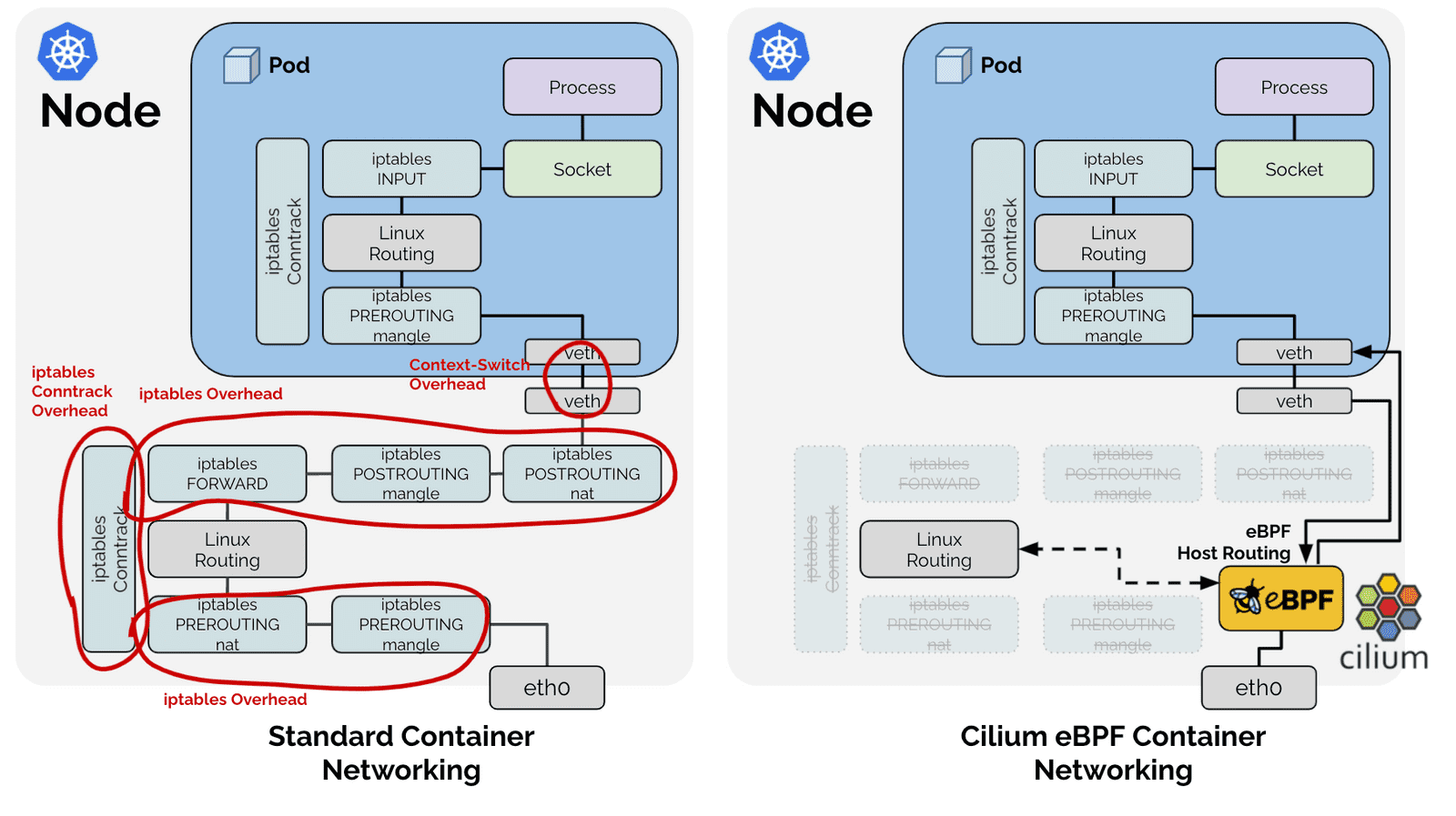
上一张神图来说明cilium的优越性:
cilium由好几部分构成:
- cilium-agent: cilium-agent在集群中的每个节点上运行(通常以daemonset方式运行)agent通过Kubernetes或API接受配置,这些配置描述了网络,服务负载平衡,网络策略以及可见性和监控要求。
Cilium agent监听来自编排系统(如Kubernetes)的事件,以了解容器或工作负载何时启动和停止。它管理Linux内核用来控制进出这些容器的所有网络访问的eBPF程序。
- cilium-client: Cilium clienet是随Cilium-agent一起安装的命令行工具(即部署在cilium-agent的容器中)。它与运行在同一节点上的Cilium agent的REST API交互。同时允许检查本地代理的状态。它还提供了直接访问eBPF映射以验证其状态的工具。
- cilium-cli: 官方还出了一个命令行工具, 就叫cilium, 可以直接运行在集群之外(类似kubectl这类的客户端, 通过token或者kubeconfig方式访问apiserver), 它与cilium-client的命令有些区别
注: cilium-client是 get from client-agent,而clium-cli是整个cilium cluster的命令行工具
- cilium-operator: Cilium Operator负责管理集群(逻辑上是为整个集群处理一次,而不是为集群中的每个节点处理一次),Cilium operator不在任何转发或网络策略决策的关键路径中。如果operator暂时不可用,群集通常会继续运行。但是,根据配置的不同,operator的可用性故障可能导致:
- IP地址管理(IPAM)延迟,因此,如果要求operator分配新的IP地址,则会延迟新工作负载的调度
- 更新kvstore心跳密钥失败,这将导致代理程序声明kvstore不健康并重新启动。
要注意,cilium operator与Kubernetes中的operator概念不同, cilium operator不生成子对象,它负责全局的一些配置等
- cni plugin: cilium自身可做为kubernetes cni插件存在,且可完全替代kube-proxy的功能(这个功能是后续介绍的重点)
以上算是cilium自身的components,还有hubble, hubble是存储、展示从cilium获取的相关数据:
- hubble-server: 在每个节点上运行,并从Cilium检索基于eBPF的可见性。它被嵌入到Cilium agent中,以实现高性能和低开销。它提供了一个gRPC服务来检索流和Prometheus指标。
- hubble-relay: hubble-relay是一个独立的组件,它可以感知所有正在运行的Hubble服务器,并通过连接到它们各自的gRPC API并提供表示集群中所有服务器的API来提供集群范围的可见性。
- hubble-cli: 是一个命令行工具,能够连接到hubble-relay的gRPC API或本地服务器以检索流事件。
- hubble-ui: 图形用户界面,可以在该界面上查看网络调用关系。
虽然有些hubble功能被内嵌到cilium中,但hubble对于cilium来说不是必需的
另外, cilium也有数据库(data-store),用来在代理之间传播状态。它支持以下数据存储:
- Kubernetes crds(默认)
存储任何数据和传播状态的默认选择是使用Kubernetes自定义资源定义(CRD)。Kubernetes为集群组件提供CRD,以通过Kubernetes资源表示配置和状态。
- key-value存储
状态存储和传播的所有要求都可以通过Cilium默认配置中配置的Kubernetes CRD来满足。键值存储库可以可选地用作优化以提高集群的可扩展性,因为直接使用键值存储库会使更改通知和存储需求更有效。
可使用etcd做为key-value数据库,当然可以直接使用Kubernetes的etcd集群,也可以维护一个专用的etcd集群
以上是cilium的介绍,算是对cilium有个基本认识,接下来是cilium在kubernetes中的安装部署,由于eBPF在不同版本的linux内核中的支持不同,因此cilium中某些功能对linux内核有版本要求,详见下文