从工程角度说AI平台建设
作者参与AI模型生产平台的建设已经有很多一段时间了,对于这类平台来说,因为牵扯到算法,会比一般的业务相对复杂,同时业界也是缺少AI Platform事实标准,要想做到如同使用SASS般丝滑,这其中还是有很多的坑要趟。
这次作者站在工程的角度同时结合作者亲身的经验来聊一聊一个好的AI训练平台需要解决哪些问题,算是做为阶段性的回顾及思考.
什么是AI平台
AI平台是个比较笼统的说法,可以理解为跟AI相关的一类平台,但是AI又可以分为好些类, 这个要看具体的业务了,作者所在的AI平台叫做模型生产平台, 其它的还有AI数据平台、AI推理平台等等,这里就不具体区分了,但大多数的AI平台都面临相同的几类问题, 所以下文就用AI平台表达吧.
首先,AI要阐述下什么算是AI平台?
这个问题对于不了解AI业务的同学可能不太好回答,因为会让人感觉知道答案,但像是又少了些什么,作者也是如此,没接触AI之前,只觉得不就是倒腾一些算法,接触之后才发现,水太深, 这里放上在网上收藏的一篇博文,作者觉得写的非常好,很适合回答什么是AI平台这个问题,这是地址一文介绍AI商品模型训练平台(深度学习平台)
划重点
AI平台提供业务到产品、数据到模型、端到端,线上化的人工智能应用解决方案。用户能在AI平台能够使用不同的深度学习框架进行大规模的训练,对数据集和模型进行管理和迭代,同时通过API和本地部署等方式接入到具体业务场景中使用
哦,原来,算法解决的是得到业务结果,而工程解决的是如何便捷地使用这些算法能力
为什么需要它?
所以,为什么需要平台呢?我直接在机器上不也能跑起来么?
当然,站在个人的角度来讲没有问题,但如果是多个人共用这台机器呢? 进一步多人用的还不是同一个框架?如果要很方便地把整个环境迁移到另外的机器上? 如果每个人用的版本还有差异?
是不是就有点不好处理
所谓的平台,其它提供的是一种能力,像Saas一样,给你这样的一个平台,可以屏蔽掉很多用户不需要关注的方面,用户只需要使用就好,从而让用户更专注业务层面.
同样,放上在网上收藏的一篇博文,作者觉得写的非常好,很适合回答为什么需要它这个问题,感兴趣的可以稳步为什么需要机器学习平台
从上面的链接中比较全面的提到了要做好一个AI平台会面临的痛点,下面是作者之前画的现在负责的AI模型生成平台训练流程
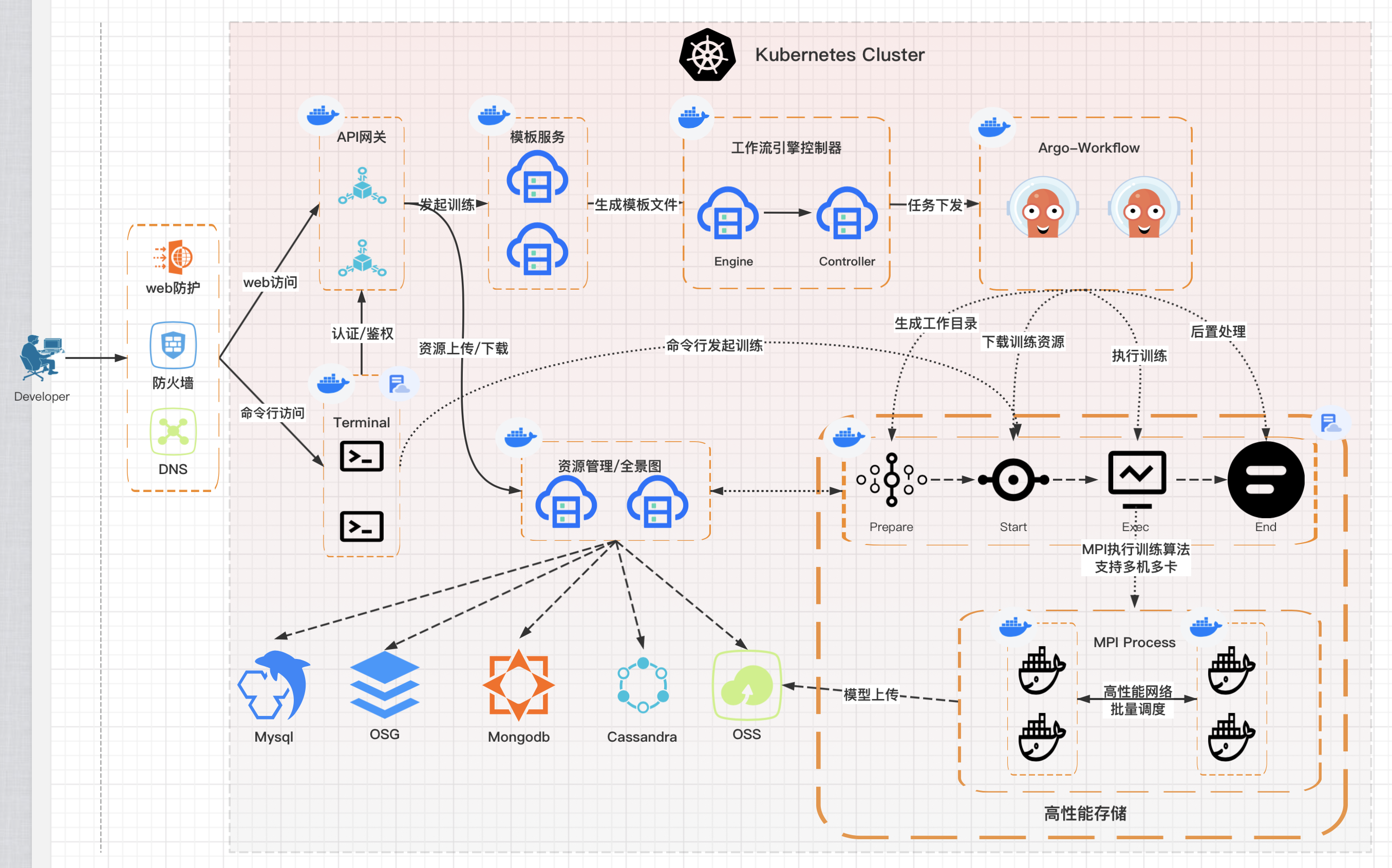
显然,上面所述的痛点作者也都面临了,同时,由于所有的模块都是基于kubernetes之上建设, 需要考虑的问题会更多.
一个系统怎么也绕不开从计算、网络、存储三板斧说起.
计算资源
硬件好是硬道理,再怎么优化1C也没2C香,计算除了硬件本身的优劣之外,一个好的调度系统也能起到事半功倍的效果.
Scheduler
AI跟其它业务不一样的是,AI需要大量消耗GPU来进行图形加速, 这是GPU擅长的领域,同时,也需要CPU进行大量的计算,更特别的是,一个AI任务一般都是由多个job共同完成的,多个job中的任一个job资源得不到满足都不应该发起这个任务,因为其它的job就算发起了,也没办法完成这个任务(有些大厂云厂商已经实现了从失败的checkpoint点再次执行任务),整个任务对于资源分配来讲,要么都分配,要么都不分配,这就是组调度的特性: All or Nothing,这样可以将资源分配给其它满足条件的任务,提高资源使用率.
面对更复杂的资源请求,如果还存在异构资源的情况下,就会对平台的调度能力提出更高、更智能的要求
云原生的解决方案比较常见的有kube-batch、volcano等开源调度器,kube-batch是不建议使用了,volcano加入了CNCF,内置了多种调度算法,非常使用用在AI任务中
vGPU
vGPU是一种对GPU进行虚拟化的技术,出发点在于AI中也存在很多的任务无法用满一块GPU,通过虚拟化的方式可以让GPU得到更加充分的利用,另一方面是云厂商的超卖,作者所在的AI平台上,未使用vGPU,因为整卡的资源都不够用,就谈不上再切分了.
那vGPU需不需要呢?当然要看具体业务而定,作者也收藏了一篇好文比较详细地阐述了这个问题,值得一看浅谈GPU虚拟化和分布式深度学习框架的异同
在kuberntes中,各大GPU厂商也出了自己的vGPU plugin,如果有需要再次开发的地方,kubernetes本身的插件化也完全可以支持.
关注CPU
大多数的AI项目都是使用Python写的,python社区存在着大量很成熟的AI框架,但不得不考虑python语言的性能问题,当然作者不是算法侧的,在算法方面的研究也不是很深,但是不可否认的是,python确实不够快,在海量计算的情况下,如果内存、CPU资源设置不合理的话,就会得到截然不同的结果
作者就在某次的性能验证中发现如果CPU设置的不合理,会直接让性能降低N倍
内存还好观察,如果是超过了给定的limit,会有OOM的现象,比较容易发现,而CPU则不存在OOM,由于CPU是切片运行的如果CPU一直处于100%的状态运行,会频繁的进行CPU的切换导致性能下降,而AI任务中动不动就可能成千上万次的迭代,整体影响就非常大了,这个从总体时间上就有很非常直观的体现。
GPU拓扑
GPU的拓扑结构也是非常关键的,比如在一台机器上,有8张GPU,同一个AI任务需要分配2张GPU,则分配在GPU1与GPU2上会比分配在GPU1与GPU7上效率更高,原理很简单, 地理位置更接近,信息交换更快
关于GPU拓扑结构的感知,现在也有一些方案支持,kuberentes中要想做到GPU的拓扑感知,得在调度器上实现,不过遗憾的是, 现在还是不特别成熟,用在生产上的好像也比较少
Node拓扑
GPU拓扑相对于同一台机器上GPU与GPU之间来说影响相对比较小,但跨Node的GPU之间的通信,影响就比较大了,因此对于同一个AI任务上,如果一台GPU能够满足要求,要尽可能地都调度在同一台机器上,原则上就是减少跨主机通信,这个成本对性能非常重要
Multi-Tenant
计算资源很重要, 如何有效地提高资源使用率,多租户的资源隔离的软硬如何权衡,队列如何设计?
业务需求千奇百怪,多租户模型会是个取舍问题
kubernetes中如何实现多租户模型, 本人也有一些实践,感兴趣的可以移步kubernetes中如何实现多租户模型
高性能网络
同理,原则上做到减少跨主机通信只能说是尽量,但一定存在跨主机通信的情况, 这个情景,网络上的差别又有天壤之别,Infinitband network就会比Ethernet快很多,高性能网络这个对AI过程也是非常重要.
Infinitband network这个是硬件网络,本身协议就支持RDMA, 但付出的代价就是成本会随之直线升高,土豪专用.
在Ethernet上, 也有一些成熟的方案可以很提升网络侧的性能,比如RDMA, RoCE等,在跨主机通信时可以直接绕过操作系统直接进行内存数据交换,不用进行用户、内核态copy数据,相当高效.
可以通过sriov技术实现在Infinitband网卡上虚拟出多块网卡,由于Infinitband网卡本身的性能就很强劲,加上sriov,虚拟出来的网卡跟Infinitband物理网卡的性能差别不大, 作者所负责的平台就是采用的sriov+infinitband进行的组网,感兴趣的可以移步Kubernetes学习(k8s基于InfiniBand实现HPC高性能容器网络组网方案实践一).
CNI
当然上面说的是硬件层面的网络,在基于kubernetes架构上的系统,集群间网络的性能也是个需要认真选型的点, CNI 使用cilium(基于ebpf)就会比kube-proxy快很多
cilium的生产实践,感兴趣的可以移步cilium在kubernetes中的生产实践一(cilium介绍), 还在更新
高性能存储
AI任务中会涉及到大量的数据处理,因此计算与存储之间的数据交换性能也显得格外重要,除了存储本身需要高性能IO之外,网络的吞吐量也很关键, 特别是在使用分布式存储系统时.
业界常用的如Gluster, Ceph-hook等提供了较高的性能,Ceph-hook对可运维能力要求比较高.
缓存加速
在AI任务中,也是存在热点数据的,比如一些常用的数据集,可能在多个AI任务中都会使用到,那提前将这些热点数据先缓存在内存中,这样可以避免每次都去存在系统中获取,也将降低时间.
Alluiox就是一款不错的开源组件,更重要的是它统一了多种常用对象存储的接口,对上层应用屏蔽了底层的存储介质.
弹性架构
好的业务架构需要好的基础架构,而丝滑般的可伸缩性必将为好的架构添上一双翅膀
首先是infra层,弹性资源池就是一个很好的解决方案, 将算力、存储、网络进行打包
这需要可观测性做到极致,系统能够清楚地知道什么时机需要扩缩容,体量需要多大
但如果要充分考虑多租户、硬隔离,调度,而且还要替人做决定等因素,要想实现一个功能完善的弹性架构,还是需要多部门通力合作。
可观测性
可观测性是作者面临的最大难题,不仅要解决的是业务层的可观测性,更难的在于AI任务的可观测性:
- 引入的AI框架如何监控
- AI任务测试覆盖率如何保障
- 整体链路如何打通
- AI可视化如何实现
- …
等等,一系列问题中的每个问题都值得深思,可观测性对于平台稳定性来说不言而喻,每一个环节都需要联合各方诸侯推进
任重道远…
参考文章:
- https://izsk.me/2023/04/01/cilium-on-kubernetes-introduction/
- https://izsk.me/2023/06/26/Kubernetes-multi-tenant/
- https://zhuanlan.zhihu.com/p/102581335
- https://izsk.me/2021/07/02/Kubernetes-Infinitband-SRIOV-network-1-backgroud/
- https://insights.thoughtworks.cn/why-machine-learning-platform/?hmsr=toutiao.io&utm_campaign=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io