Prometheus学习(PromSQL常用函数)
prometheus从某种程序上也算是一种数据库, 使用的是promSQL语言, 既然做为一种数据库查询语言, 自然也跟其它数据库一样内置各种查询函数, prometheus中内置的函数比较多, 完整的函数列表在这里, 这里会记录在工作中常用到的一些函数.
时间区间
首先要了解的是, 在prometheus中,不能直接指定时间区间,不过可以使用如[180m]、offset 5m等方式来表示距当前时间的一段时间内, 这种方式在prometheus中叫做范围向量选择器(range-vector)
1 | # 返回当前五分钟之前http_requests_total的数据 |
速率函数
increase(增长量)
increase(v range-vector)
获取时间区间内的第一个样本与最后一个样本,返回之间的增长量
这个比较容易理解,就是在时间区间内的最后一个值减去第一个值, 获得差值
比如: 计算http get类型的请求在5m内增长数
increase(http_requests_total{instance="10.42.6.52:9100", method="get"}[5m])

rate(增长率)
rate(v range-vector)
计算范围向量中时间序列的每秒, 第一个点及最后一个点来平均增长率,然后求平均增长率
比如: 计算http get类型的请求在5m内增长率
rate(http_requests_total{instance="10.42.6.52:9100", method="get"}[5m])

可以发现value=0.05, 恰恰是在5m内增的15除于300所得到的
因此rate所得到的增长率就是rate=increase/range
irate(增长率)
irate(v range-vector)
计算范围向量中时间序列的每秒, 最后两个点来计算瞬时增加率,用增长量/时间区间来计算增长率
同样,比如: 计算http get类型的请求在5m内增长率
irate(http_requests_total{instance="10.42.6.52:9100", method="get"}[5m])

我们能够发现, irate得到的数据跟rate得到的数据是一样, 那为何同时存在这两个函数呢?
先回答下为何这两个值是一样的, 因为这个测试环境没多少请求, 请求数增长才几十个, 在量小的情况下对于使用rate与irate的并别不会很明显
如果这里换个例子, 用rate/irate来计算某机器在1m内网卡的增长率,就能看出点区别了
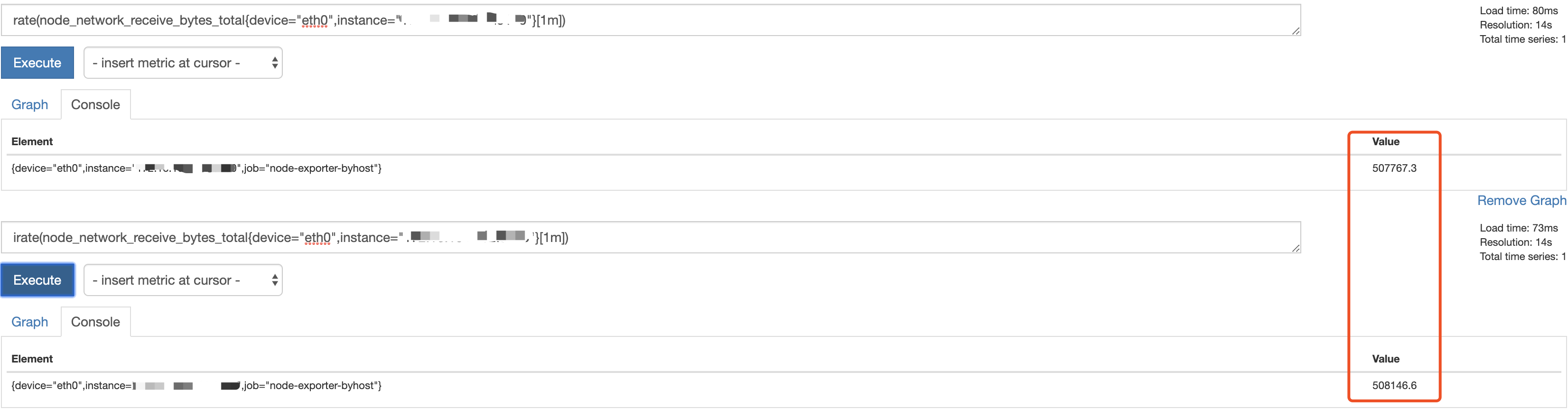
所以变化越快的场合这两者的差别越大, 那两者到底有啥区别呢
rate与irate区别
irate和rate都会用于计算某个指标在一定时间间隔内的变化速率。但是它们的计算方法有所不同:irate取的是在指定时间范围内的最近两个数据点来算速率,而rate会取指定时间范围内所有数据点,算出一组速率,然后取平均值作为结果。
所以官网文档说:irate适合快速变化的计数器(counter),而rate适合缓慢变化的计数器(counter)。
根据以上算法我们也可以理解,对于快速变化的计数器,如果使用rate,因为使用了平均值,很容易把峰值削平.而irate则是在范围向量中每个时间序列的两个最近数据点的增长率.
计算函数:
sum
很简单, 直接求和

count
很简单, 直接请记录数

ceil
四舍五入,将所有元素的样本值四舍五入v到最接近的整数
abs
返回绝对值
round
保留小数点位数
后面这几个的意思都比较明确, 在这就不贴图了, 这些计算函数一般都会跟by结合使用.
排序函数
sort/sort_desc
sort(v instant-vector)/sort_desc(v instant-vector)
将结果按升序/降序排列
sort(sum(nginx_ingress_controller_response_duration_seconds_bucket{path=~"/sensego/v2.0/mingyuan",status="200"}) by (le))
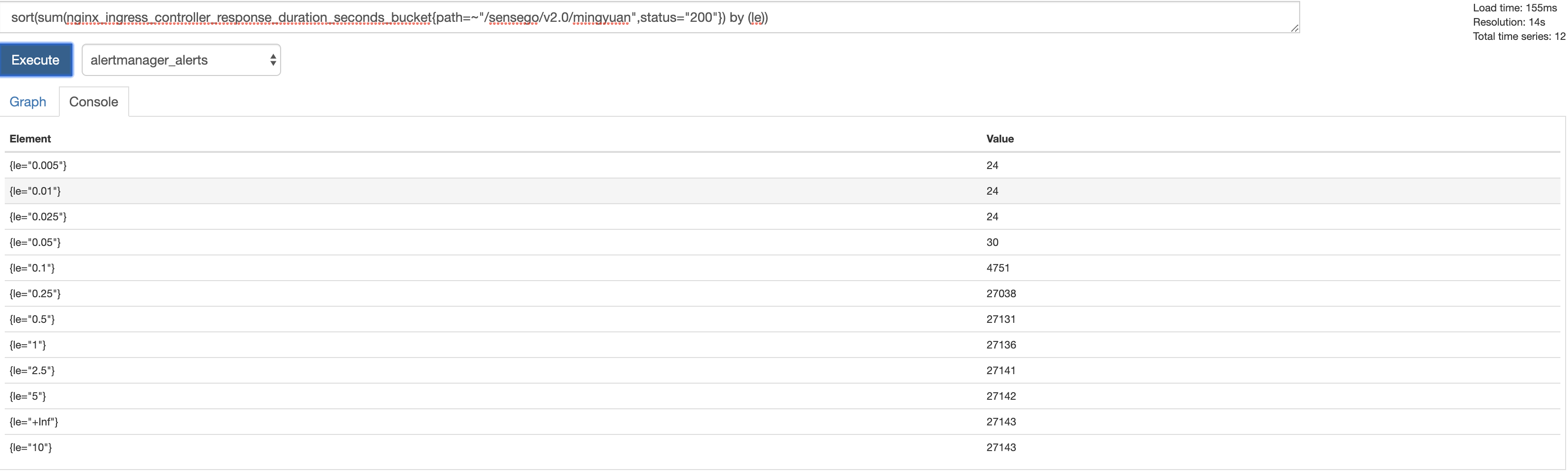
####topk
k表示按照某种排列只保留K条记录
topk(3, sort(sum(nginx_ingress_controller_response_duration_seconds_bucket{path=~"/sensego/v2.0/mingyuan",status="200"}) by (le)))

标签函数
label_join
将多个 src_label 拼接成一个新的 dst_label,用分隔符 separator 连接
label_join(v instant-vector, dst_label string, separator string, src_label_1 string, src_label_2 string, ...)
- v: 表示需要操作记录
- dst_label: 添加/覆盖的label, 如果指定的label不存在,则添加
- separator: 分隔符
- src_label_1: 源label
- 可以有N个标签
比如, 想在以下记录中添加一个foo 标签, 这个标签的值来自instance与job

label_join(up{instance="localhost:9090",job="prometheus"}, "foo", ",", "instance", "job")

最终的结果会出现多了个foo="localhost:9090,prometheus",达到目的.
lable_replace
用于给监控项添加/覆盖label
label_replace(v instant-vector, dst_label string, replacement string, src_label string, regex string)
- v: 表示需要操作记录
- dst_label: 添加/被覆盖的label, 如果指定的label不存在,则添加
- replacement: 匹配到的string ,使用$1,$2…引用
- src_label: regex表达式匹配的源label
- regex: 正则表达式,可使用$1,$2…引用
比如:
label_replace(kubelet_running_pod_count,"node", "$1", "kubernetes_io_hostname","(.*)")
原kubelet_running_pod_count 结果集如下,可以看出集中没有node 标签

通过以上语句添加一个node label:

覆盖label:

分位函数
histogram_quantile
用于计算通过histogram获取数据的分位数
假如,要计算nginx_ingress中95%的响应时间落在哪个区间可以使用以下命令
histogram_quantile(0.95, sum(rate(nginx_ingress_controller_response_duration_seconds_bucket{path=~"/sensego/v2.0/mingyuan",status="200"}[1800m])) by (le))

当然正常情况下都是在grafana中对Prometheus的数据进行查询, grafana本身也有一些常用的函数, 有机会也学习记录下.