Kubernetes学习(flannel深入学习)
得益于社区的繁荣, 包括部署工具的完善, 现在几乎没人会从0去搭建kubernetes集群, 随便拿起一个开源工具, 几乎都是一条命令, 喝个咖啡, 然后整个集群就能用了, 非常快捷, 但是方便的时候, 也容易遗漏掉其中的一些知识点, 有些对整个kubernetes的了解及生态还是非常有必要的.
由于社区可选的CNI成熟方案非常的多, 而flannel是kubernetes默认的容器网络模型, 还是要重点深入学习下
由于flannel涉及到CNI相关的知识, CNI也不会在这里深入探讨, 有机会跟CRI一起更.
比如有以下涉及容器网络的问题?
- kubernetes如何知道集群中采用了哪种CNI, 处理逻辑是什么?
- 使用ip addr看到一个docker0、cni0、flannel.1它们有什么作用, docker0在flannel中扮演什么角色?
- flannel的通信方式?
- 从使用kubectl创建了一个pod后,期间发生了什么?
如何知道使用了哪种CNI,处理逻辑是什么?
这里并不会对CNI的规范做一个说明, 简单总结来说就是:
CNI旨在为容器平台提供网络的标准化,它 本身并不是实现或者代码,可以理解成一个协议,这个协议连接了两个组件:容器管理系统和网络插件。它们之间通过 JSON 格式的文件进行通信,实现容器的网络功能。具体的事情都是插件来实现的,包括:创建容器网络空间(network namespace)、把网络接口(interface)放到对应的网络空间、给网络接口分配 IP 等等。
要知道一个集群使用了哪种CNI, 最好的办法就是顺序数据流向一步一步分析.
从上面对CNI的总结看, CNI的相关配置一定是在容器运行时这一端, 因为要创建容器网络空间, 自然是要在client端,那么对于kubernetes来说就是kubelet, 查看kubelet参数(这里kubelet是以容器启动的)
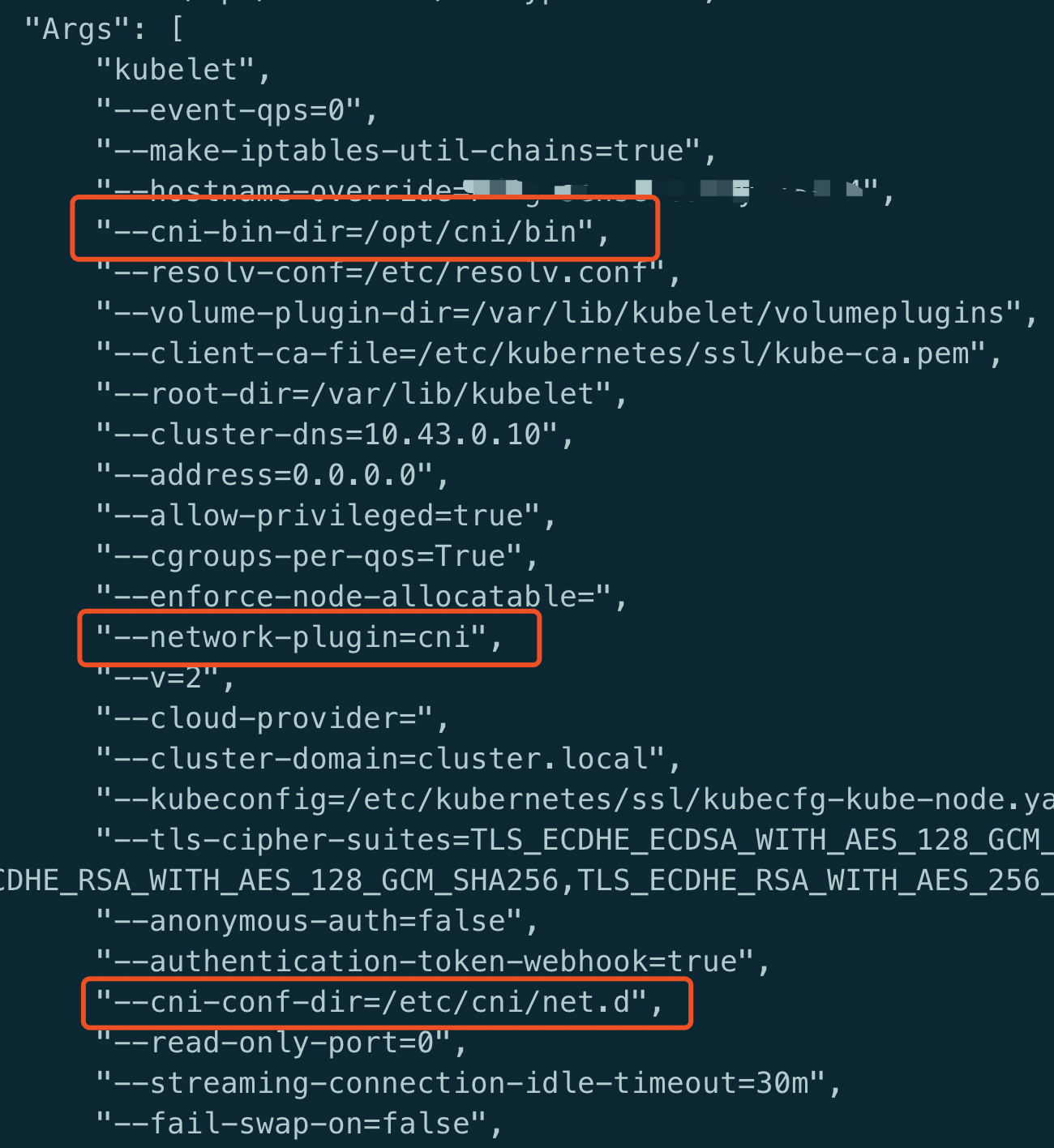
这3个参数决定了集群使用的哪种CNI, 其中第2个参数指定了使用CNI来组件容器网络, 现在来逐一的查看这些目录
/etc/cni/net.d
该文件下只有一个文件10-flannel.conflist
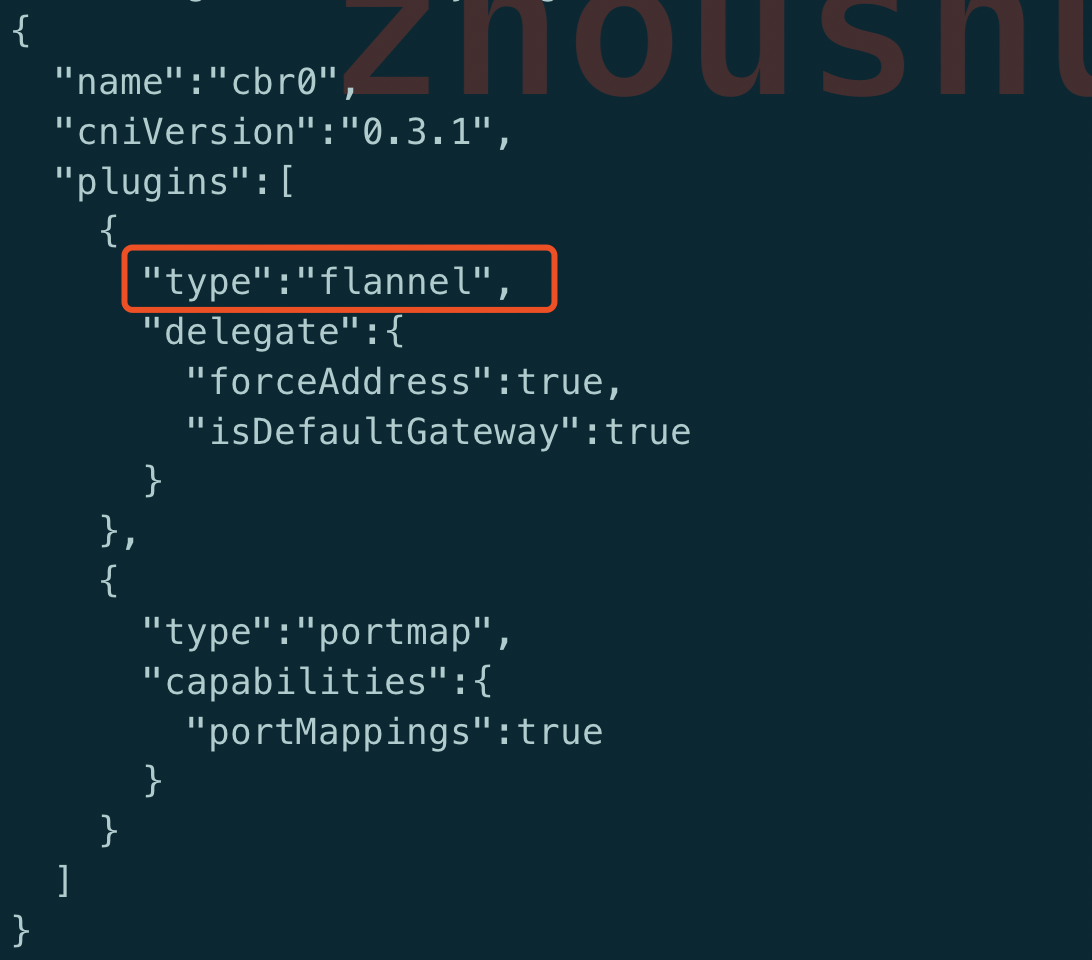
注意type: flannel, 那么这里就指定了使用的是flannel, 而不是calico, macvlan等其它CNI
/opt/cni/bin
这个目录下放置着CNI的二进制文件, 因为CNI协议规则,所有实现了CNI的都必须提交二进制的文件供kubelet调用, 并且会调用后端的网络插件

因此通过指定type: flannel来这个目录下调用flannel
这里要区分一下flannel跟flanneld这两个
flannel
平时大家说的flannel指的是/opt/cni/bin/flannel, 但是这个二进制的github源码是在plugins, 并不是指的flanneld.
这个flannel才是真正做为CNI插件实现了CNI_COMMAND ADD/DEL方法
flanneld
这个flanneld的github源码在flannel, 这个flanneld主要实现overlay网络, 包含给所有node分配subset段, 同步节点间的网络信息等.
flanneld可以以容器的方式(daemonset)运行, 查看下配置文件
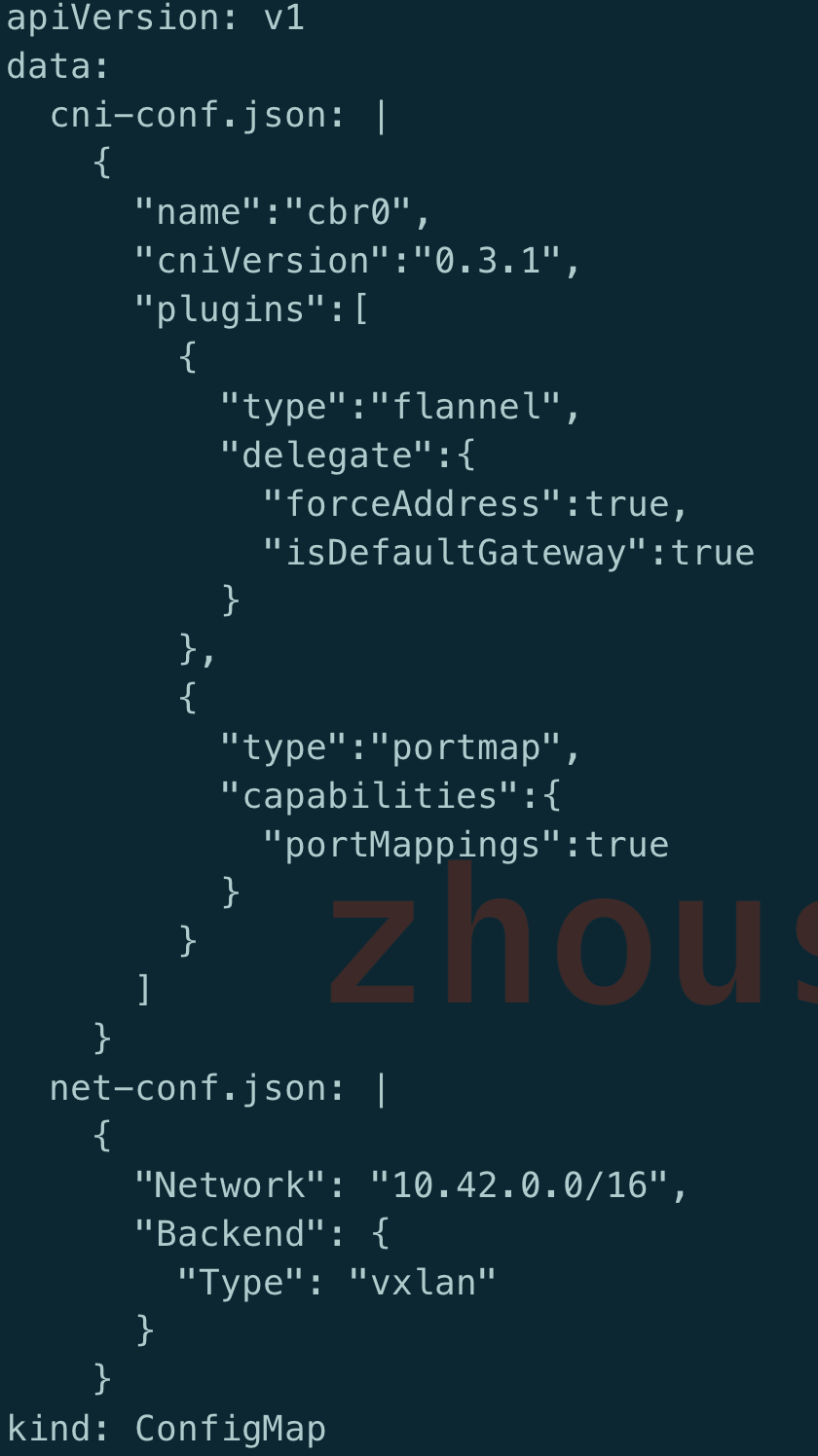
从配置文件可以到有两个配置文件
cni-conf.json
这个文件就是/etc/cni/net.d/10-flannel.conflist, 指定backend使用flannel
net-conf.json
这个文件指定了整个kubernetes网络能够使用的ip地址段(在部署时可以被覆盖), 且指定了flannel使用vxlan模式(flannel本身提供多种模式), 最终这个文件会挂载到/etc/kube-flannel/net-conf.json, 提供给cni使用
subset.env
还有一个很关键的文件就是/run/flannel/subnet.env, 该文件记录了某个node上的flanneld启动后在etcd端分配的ip子段, 也就是说, 这个node上的所有pod只能在这个ip段内分配

从这里可以看出, 每台机器上最多能够使用的ip有254个, 这个是远远够的, 一般情况下一台机器的pod数不会过百
flannel-cni容器
细心的可能会发现flannel的yaml文件还包含了install-cni.sh的容器, 这个容器的逻辑比较简单, 大家可自行查看源码github
etcd
flanneld的启动参数中指定了etcd, etcd在flannel充当数据的角色, 同时使用etcd做为服务注册、 发现, 所有pod/node的ip/mac信息都存储在etcd中, 所有flanneld节点共享, 通过这种方式来避免ip重复分配.
处理逻辑
因此, 如果集群中使用了flannel做为CNI, 完整的处理逻辑如上分析, 简单说的话就是:
- 指定整个集群pod的ip CIDR
- 每个node上都会启动flanneld进行, 通过etcd分配该node上所有pod的使用地址, 后续会在整个集群内共享各个node上的pod ip信息, 生成路由信息.
- 所有node通过flannel overlay网络进行通信
docker0、cni0、flannel.1
如果在一台node上使用ip addr, 会发现有docker0、cni0、flannel.1这些网络接口
这三者充当什么角色.
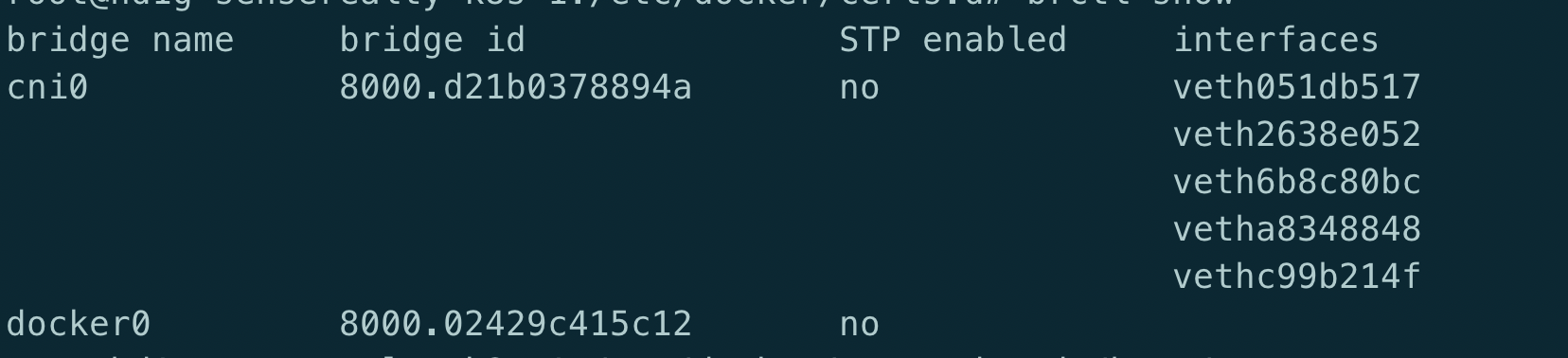
首先docker0这个跟flannel及docker的部署顺序有关系, 如果是docker先部署了, 后再部署flannel,部署完成之后也没有重启docker, 那么这种情况docker0是不做为node与pod之间的bridege, 而是使用了默认的cni0来组成veth对
可以使用brctl show来查看, 会发现该node上所有的pod都是绑定在cni0上
而如何在部署flannel时修改了docker的启动参数, docker使用了flannel的bip参数的话,那就会默认使用docker0来组vth对, 即pod都会通过docker0通信.
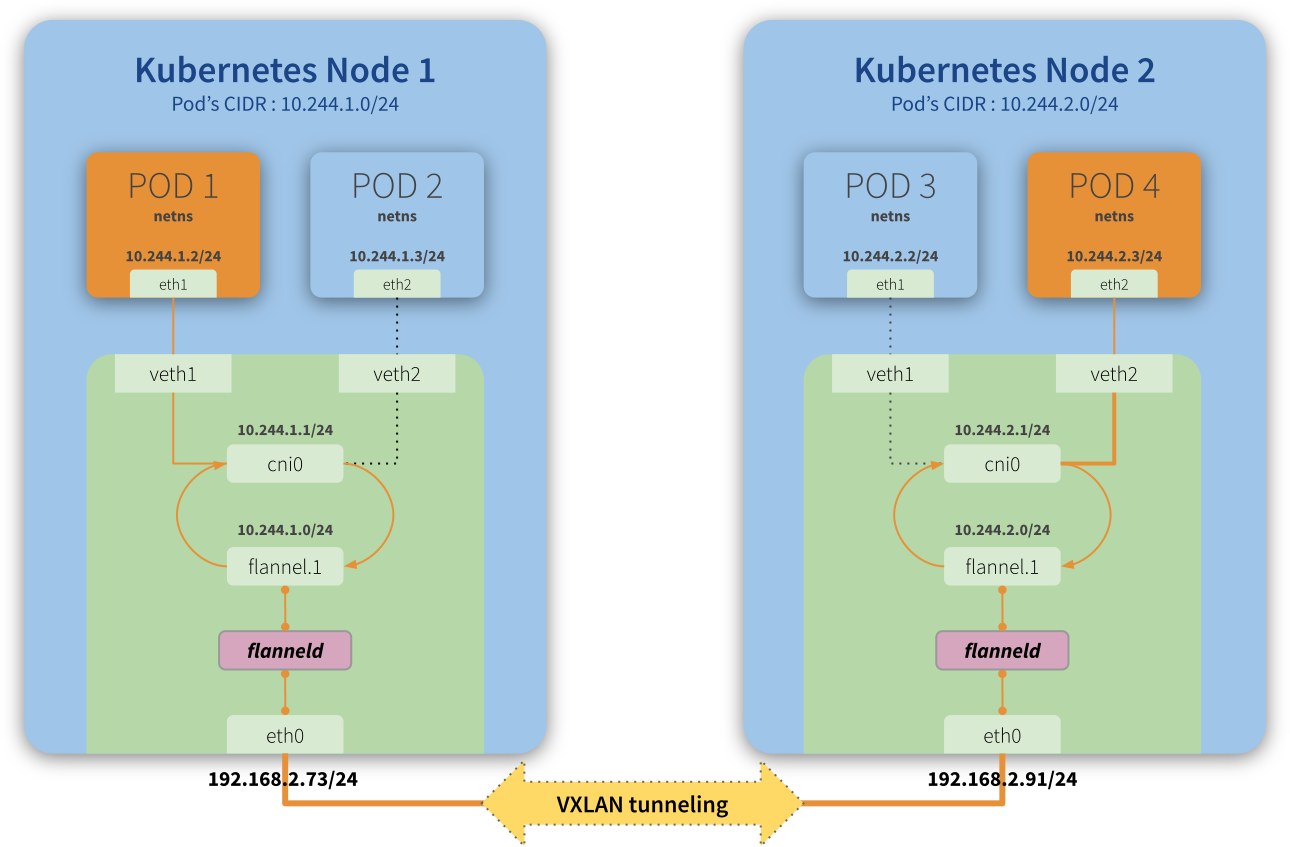
而flannel.1则是flanneld组成的overlay网络的通道, 它本质上是个VXLAN Tunnel End Point,如上图所示
具体的细节下面使用flannel的通信来说明
flannel通信方式
Kube-dns
这里简单提一下kube-dns, kube-dns负责集群内的域名解析, 因此在集群内访问时才能使用xxx.namespace.svc.cluster.local这种形式访问.
kube-dns也支持上游dns, kube-dns集群内解析不了的可交由上游dns解析.
如在kube-dns的pod中挂载宿主要的/etc/resolv.conf文件.

路由规则
kubernets的网络,从设计上来讲是“扁平、直接”的,要实现kubernetes的cni模型, 需要实现3点要求:
- 所有容器可以不使用NAT技术就可以与其他容器通信
- 所有节点(物理机 虚拟机 容器)都可以不使用NAT同容器通信
- 容器看到的IP地址和别的机器看到的IP是一致的
那么一条网络报文是怎么从一个容器发送到另外一个容器的呢(跨主机) ?
这里以vxlan为例
- 容器直接使用目标容器的 ip 访问,默认通过容器内部的 eth0 发送出去
- 报文通过 veth pair 被发送到 vethXXX
- vethXXX 是直接连接到虚拟交换机 cni0 的,报文通过虚拟 bridge cni0 发送出去
- 查找路由表,外部容器 ip 的报文都会转发到 flannel.1 虚拟网卡,这是一个 P2P 的虚拟网卡,然后报文就被转发到监听在另一端的 flanneld
- flanneld 通过 etcd 维护了各个节点之间的路由表,把原来的报文 UDP 封装一层,通过配置的
iface发送出去 - 报文通过主机之间的网络找到目标主机
- 报文继续往上,到传输层,交给监听在 8285 端口的 flanneld 程序处理
- 数据被解包,然后发送给 flannel.1 虚拟网卡
- 查找路由表,发现对应容器的报文要交给 cni0
- cni0 找到连到自己的容器,把报文发送过去
如果是同一node上pod通信, 则直接通过cni0就可以,
查看node上的路由信息:
route -n
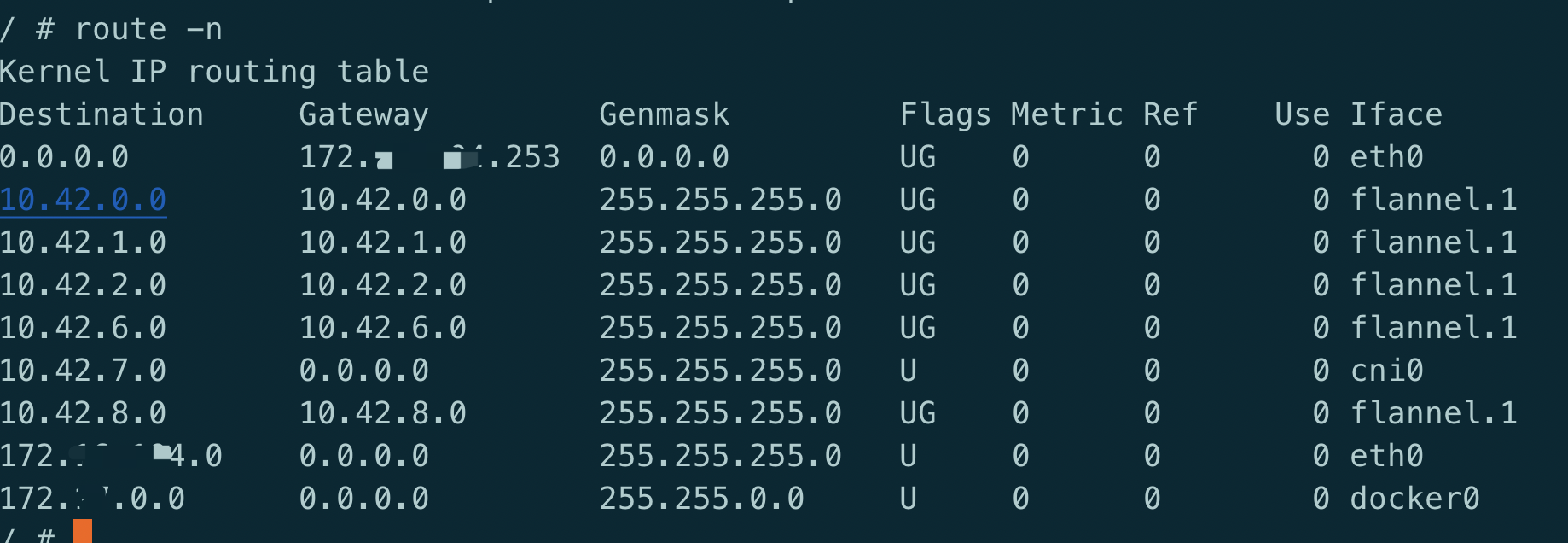
从这里可以看到, 10.42.xx的使用flannel.1 iface转发, 这也是集群pod的网段.
而如果是访问的其它ip,则是通过eth0 iface
VXLAN
vxlan是Linux上支持的一个隧道的技术,隧道也就是点到点,端到端的两个设备的通信,其实vxlan实现是有一个vtep的设备做数据包的封装与解封装,而现在已经封装到flannel.1这个进程里面了,也就是这个虚拟网卡包含了veth对使用对这个vxlan进行封装和解封装
为何需要封装
为什么需要封装呢? 从上面的图可以看到
假如现在有如下请求.podA –> podB(如果是serviceB的clusterIP,则会通过kube-proxy机制随机得到一个后端ip)
则根据路由信息, 知道需要从flannel.1网口转发, 但是flannel.1要发送到哪呢?按照常规逻辑, 这个请求包中只包含有如下信息:
src: podA地址
dst: podB地址
通过flannel生成的路由信息可以知道需要通过NodeA上的flannel.1进行转发.
如果仅仅知道上面这些信息是无法将请求转发到NodeB的, 因为现在还不知道NodeB的IP,就无法路由
因此, 需要一种机制把NodeB的IP封装到原始包中, 进行路由, 同时NodeB需要支持解封装
这就是需要封装的原因, 而vxlan是内核原生支持的特性.性能也比较高
当然也许有人会问不是可以通过api-server根据podip来查找所属的NodeIP吗?
这完全是没问题的, 但这会交付网络寻址的问题融入到kubernetes的代码中,将会变得异常复杂,同时也违背了插件化的理念, 因此路由寻址问题必须在容器网络插件层面解决.
封包格式
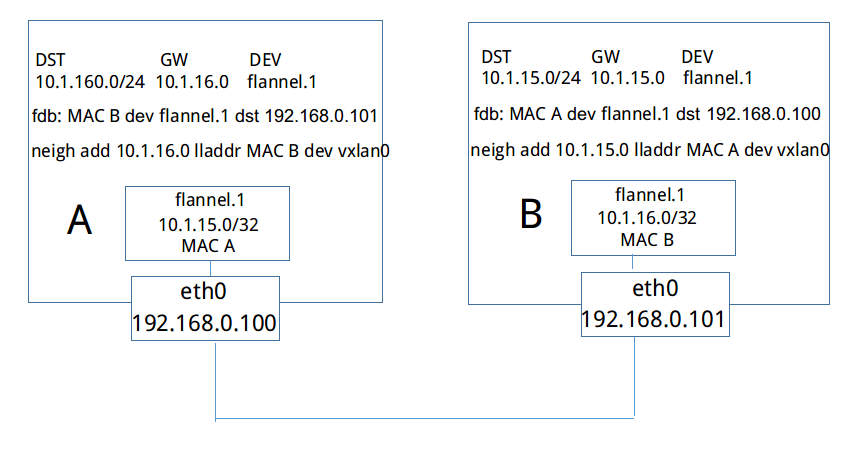
如上图所示,当NodeB加入flannel网络时,和其他所有backend一样,它会将自己的subnet 10.1.16.0/24和Public IP 192.168.0.101写入etcd中,和其他backend不一样的是,它还会将vtep设备flannel.1的mac地址也写入etcd中。
之后,NodeA会得到EventAdded事件,并从中获取NodeB添加至etcd的各种信息。这个时候,它会在本机上添加三条信息:
路由信息:所有通往目的地址10.1.16.0/24的封包都通过vtep设备flannel.1设备发出,发往的网关地址为10.1.16.0,即NodeB中的flannel.1设备
fdb信息:MAC地址为MAC B的封包,都将通过vxlan首先发往目的地址192.168.0.101,即NodeB
arp信息:网关地址10.1.16.0的地址为MAC B
最终生成的封装包如下:

可以查看其它机器的flannel.1设备的mac地址
bridge fdb show dev flannel.1
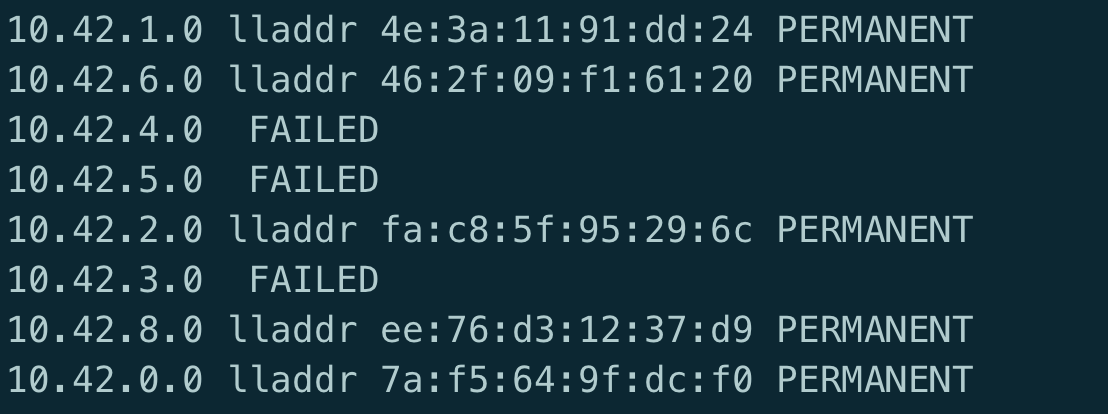
通过mac地址查找ip地址
bridge fdb show dev flannel.1|grep '46:2f:09:f1'

完整流程
有一个容器网络封包要从A发往容器B,封包首先通过网桥转发到NodeA中。此时通过,查找路由表,该封包应当通过设备flannel.1发往网关10.1.16.0。通过进一步查找arp表,我们知道目的地址10.1.16.0的mac地址为MAC B。到现在为止,vxlan负载部分的数据已经封装完成。由于flannel.1是vtep设备,会对通过它发出的数据进行vxlan封装(这一步是由内核完成的),通过查询fdb获取目的mac地址为MAC B的ip地址为192.168.0.101
封包到达主机B的eth0,通过内核的vxlan模块解包,容器数据封包将到达vxlan设备flannel.1,封包的目的以太网地址和flannel.1的以太网地址相等,三层封包最终将进入主机B并通过路由转发达到目的容器
先通过NodeB的IP在三层网络进行路由, 到达NodeB后, 再在二层网络使用MAC地址发现NodeB上的flannel.1设备, 最终通过PodB的IP进行转发完成整个流程
整个流程如下:
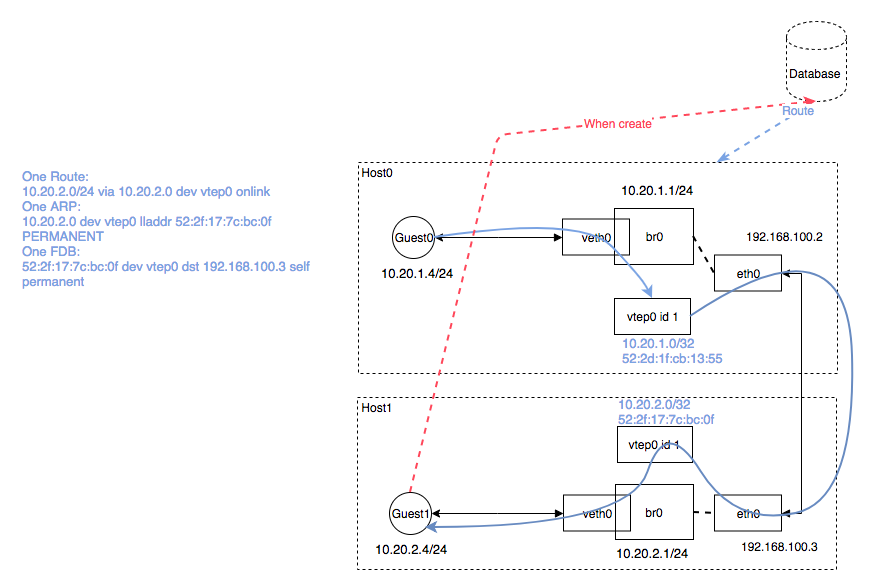
flannel不需要Nodes之间在同一个子网, 只需要能够互通就行.
host-gw
hostgw是最简单的backend,它的原理非常简单,直接添加路由,将目的主机当做网关,直接路由原始封包。例如,我们从etcd中监听到一个EventAdded事件:subnet为10.1.15.0/24被分配给主机Public IP 192.168.0.100,hostgw要做的工作非常简单,在本主机上添加一条目的地址为10.1.15.0/24,网关地址为192.168.0.100,输出设备为上文中选择的集群间交互的网卡即可。对于EventRemoved事件,删除对应的路由即可
Host-gw有一定的限制,就是要求所有的主机都在一个子网内,即二层可达(不需要经过路由),否则就无法将目的主机当做网关,直接路由
至于选择vxlan还是host-gw, 根据实际情况吧, 性能上host-gw肯定是高一点, 但网络上有限制, 而vxlan如果集群规则不是很大的话, 基本跟host-gw的性能差不多.
参考文章:
- https://kubernetes.io
- https://github.com/containernetworking/plugins
- https://github.com/coreos/flannel-cni
- https://blog.51cto.com/14143894/2462379
- https://www.cnblogs.com/YaoDD/p/7681811.html
- https://blog.51cto.com/14143894/2462379
- https://itnext.io/kubernetes-journey-up-and-running-out-of-the-cloud-flannel-c01283308f0e