Kubernetes学习(再谈kubernetes中的各种内存OOM)
本篇内容主要围绕kubernetes中的各种内存,对以下灵魂话题进行深入剖析:
- 为什么容器没有到达limit后却被OOM了?
- 容器中产生的PageCache如何统计?
- 容器中emptydir类型为medium=Memory是否会引起OOM?
- 如何更好地监控容器内存?
- PageCache相关参数
说明: 为了方便,这里不对容器与pod进行区分.
之前也写有几篇关于kubernetes中OOM的文章, 感兴趣的以先睹为快,
这一篇与之前几篇的不同之处主要在于讨论了PageCache这类内存对OOM的影响.
OOM日志怎么看?
首先还是有必要对Linux OOM日志做一个细致的说明,以便更好地带入下面的话题.
1 | Apr 14 14:13:32 sha2uvp-gert01 kernel: telegraf invoked OOM-killer: gfp_mask=0x201da, order=0, oom_score_adj=0 |
以上log是发生了oom后内核打印出来的信息, 有几个重要的参数需要关注:
前几行说明系统在发生OOM时当前内存的一个snapshot, 第一行直接说明了是telegraf触发了OOM-killer
然后中间几行是发生OOM时各个进程内存的相关情况,需要说明的是:
最后二行是被OOM-killer选出来的进程(这里是telegraf)的内存占用情况
中间那几行中的total_vm那列所表示的值的单位页,在转换为内存kB时需要*4,
比如上面pid: 6033在中间的total_vm的值为7482510*4=29930040,刚好等于最后一行中的total-vm的kB值。
好。这里再解释一下total_vm, anon-rss, file-rss, shmem-rss这几个名词的含义:
- total-vm:
含义:总虚拟内存(Total Virtual Memory)。
解释:表示进程使用的总虚拟内存量,包括所有已分配的内存(无论是否实际使用),即进程请求的虚拟地址空间的大小。
- anon-rss:
含义:匿名驻留集(Anonymous Resident Set Size)。
解释:表示进程当前使用的匿名内存部分,这部分内存不与任何文件关联,通常由动态分配(如通过 malloc())生成。它反映了实际驻留在物理内存中的匿名页的数量
- file-rss:
含义:文件驻留集(File Resident Set Size)。
解释:表示进程使用的与文件映射相关的内存部分。这部分内存是通过文件映射(如 mmap)分配给进程的,反映了实际驻留在物理内存中的文件页的数量。
- shmem-rss:
含义:共享内存驻留集(Shared Memory Resident Set Size)。
解释:表示进程使用的共享内存部分。这种内存可以被多个进程访问,通常用于进程间通信, 最常见的有/dev/shm。
使用一个简单的例子来说明:
假设一个进程通过 malloc() 请求了 1GB 的内存,但只使用了其中的一部分,比如256MB,其中/dev/shm中使用了100MB, 那么:
total-vm 将显示为 1GB
anon-rss 将显示为 256MB(实际使用的匿名内存)
没有映射到任何文件,file-rss 将为 0
因为使用了/dev/shm, 则shmem-rss将为100MB
total-vm与shmem-rss都比较好理解,这里再重点说一下anon-rss与file-rss.
上面提到, anon-rss是进程当前使用的匿名内存, 它不与任何文件相关联, 这到底是什么意思呢?
打个比方:
我在C程序中通过malloc()方法申请了并使用了一段内存,之所以叫匿名内存指的是不需要手动指定对应的文件(linux中万物皆文件,内存也是如此)
最常见的是在堆和栈上分配的内存都属于 anon-rss, 这部分内存中的数据即使被销毁了也不会被写回到任何文件中,这就是它不与任何文件相关联的特点
而file-rss内存则是通过文件映射(如 mmap)分配给进程的,这又是什么意思呢?
打个比方,假设你有一个进程打开了一个大文件并且该文件被映射到内存中。这个过程可能涉及以下步骤:
打开文件:进程使用系统调用打开了这个文件。
内存映射:进程通过 mmap() 系统调用将该文件映射到其虚拟地址空间。这使得文件内容可以直接在内存中访问,而不需要每次都从磁盘读取。
使用文件:当进程读取或修改该文件的内容时,相关的内存页会被加载到物理内存中。
这就是最常见的场景: 在处理大文件或进行大量I/O操作时,file-rss的值可能会显著增加.
ok, 了解了这些概念之后,再来分析内核中出现如上的OOM日志后就可以进一步分析。
为什么容器没有到达limit后却被OOM了?
正常的超过limit被OOM的场景这里就不分析了,如果监控比较完善就应该很容易发现。
那有没有可能一个node上的所有容器都没有达到limit,但产生了OOM事件,其中一个容器被OOM了?
答案是肯定存在的, 有如下的几种常见场景都可能造成这个局面
一、节点上有不受kubernetes管控的程序
从这里可以知道, 节点上显示的可分配资源(allocatable)无法控制运行在集群节点上、但在集群之外的应用使用的资源。
也就是说,如果我直接在节点上运行一个进程,这个进程所占用的内存是不被kubelet监控的,因此当所有容器使用的内存加上节点上直接运行的进程的内存达到系统的安全内存阈值之下(见最后一节)时,系统就会通过OOM-killer来杀死某些进程来让节点可用内存维持在安全阈值以下,
这个被杀的进程可能就是某个容器。至于系统怎么选择出被杀进程的过程将不在本文中展开。
二、容器产生了大量的pageCache
详情见下文
容器中产生的PageCache如何统计?
考虑这样一种场景: 节点A上的容器B在运行过程中产生大量的page cache, 这部分内存该如何统计呢?
这个例子相对来说比较复杂, 同样有几个概率需要先进行说明:
首先,解释下page cache是什么?
每当读取一个文件,数据会被缓存在 page cache 中以避免后续访问时重复读取磁盘带来的昂贵开销。也就是说我们平时访问文件(read 或 mmap 系统调用)都会创建对应的 page cache,这部分内存由操作系统管理,并不记录在用户程序的内存开销中
Page Cache 是由内核管理的内存,位于虚拟文件系统(VFS)层与具体文件系统层之间。
常见的查看page cache的命令如下:
1 | # free -h |
其中:
shared对应的是shared memory共享内存。
buff/cache对应的就是page cache(这里没有必要去区别buff跟cache到底是什么区别,你看它们都放在了同一列)
因此回到上面那个场景,如果容器B进行了大量的文件读写,将会导致free中的buff/cache值增大,当大到一定程序时就有可能产生OOM事件, 这又是为什么呢?
Page Cache 是由内核管理的内存,请务必牢记这句话,下面的分析无时不刻地在印证这句话。
这句话有两层含义: 一是page cache是由内核管理, 二是Page Cache是一种内存
既然它是由内核直接管理的,因此将不会计算在容器的limit内,所以就会有这样的情况:
容器A(假如limit设置为1Gi)中的进程进行了大量的文件读写,可能产生了2Gi的pageCache, 但容器A本身的内存使用量(包括 anon-rss 和 file-rss)一直保持在1GiB, 所以不会OOM.
但对于节点A来说就不一定,考虑一种极端情况, 如果节点A上存在很多容器B这样的问题,
虽然内核对pagecache有清理机制(LRU(Least Recently Used)算法),当page cache增涨超出了内核安全内存的阈值之下,那么OOM-killer将会被激活,然后杀死进程以让系统可用内存保持在安全线之下.
从这个例子可以看出,虽然所有的容器使用的内存都在limit之内,但由于pagecache的原因还是会产生OOM事件
还有以下结论我这里直接给出答案:
Q1: 一个节点上产生的pagecache是否可以在这个节点上的所有容器中进行共享?
A: 由于pagecache是由内核管理的,所以当容器读取宿主机上相同的文件时,产生的PageCache是可以共享的,不过存在一些潜在的安全和一致性问题不在此讨论。
Q2: 如果可以共享,这部分cache内存是算在哪个容器上的?
A: 有一个metrics: container_memory_cache是来统计容器使用了多少cache的,
产生的PageCache是算在第一个读取文件的容器对应的container_memory_cache, 后续读取相同文件的容器的container_memory_cache则不会被重复统计,即使第一个容器被删除了,后面的容器的container_memory_cache也不统计。
Q3: 在容器中是否可以管理pagecache?
A: 由于pagecache是由内核统一管理的,正常情况下是不能在容器中进行管理的,注意这里说的是默认情况下你无法在容器中执行清理pagecache的操作, 但在privileged模式下可以
Q4: 容器单是否可以隔离pagecache?
A: 不行, pagecache 是由宿主机内核统一管理
Q5: 如果在宿主机上清理了pagecache, 是否会立即反映到容器里?
A: 是的, 这是因为容器共享宿主机的内核和物理内存,虽然容器通过cgroups限制了内存的使用上限,但还是因为pagecache 是由宿主机内核统一管理, 如果在宿主机上清理缓存,容器内也会感受到内存的释放效果。
容器中emptydir类型为medium=Memory是否会引起OOM?
对于在pod中使用emptydir类型为medium=Memory,一般是直接将这种volume直接挂载到容器中的/dev/shm。
这个话题在我的另一篇文章: Kubernetes学习(深入理解emptyDir)中详细进行了说明, 感兴趣的可以移步,这里也直接说结论了:
emptydir类型为medium=Memory中指定的内存不能超过pod中所有容器limit.memory资源之和, 所以会引起OOM
如何更好地监控容器内存?
最后我想再说一下, 容器中存在多个与内存相关的metrics, 在生产上这几个metrics如何更好地反应容器的真实使用情况呢?
先来看看有哪些metrics
| 指标名称 | 含义 | 是否包括缓存 | 实际内存反映 |
|---|---|---|---|
container_memory_usage_bytes |
容器使用的总内存,包括匿名内存、Page Cache 和 Slab Cache。 | 是 | 部分反映实际使用,但包括可回收内存。 |
container_memory_working_set_bytes |
实际使用的内存,不包括可回收的缓存(Page Cache 和交换空间)。 | 否 | 最能反映实际需求的内存。 |
container_memory_rss |
容器分配的匿名内存和文件映射内存,实际占用的物理内存部分。 | 否 | 反映了物理内存使用。 |
container_memory_cache |
文件系统缓存(Page Cache),用于加速磁盘访问。 | 是 | 只包含缓存,不反映应用需求。 |
总结起来的结论如下:
1 | container_memory_cache = active_cache + inactive_cache |
container_memory_working_set_bytes是否OOM的唯一指标,当这个值到达limit后, OOM-killer将会生效- 容器中的共享内存(如/dev/shm)包含在除container_memory_cache外的其它3个metrics中。
- container_memory_cache无法直接区分出active和inactive的值, 如果需要采集,只能通过解析容器的
/sys/fs/cgroups/memory/memory.stat文件获取 - 文件映射内存是指通过
mmap()系统调用将一个文件的内容映射到进程的虚拟地址空间中。这种方式允许进程直接访问文件数据,而不需要通过标准 I/O 操作(如read()和write())进行数据传输 - container_memory_rss提到的实际占用的物理内存,这里的物理内存是实实在在的物理层面上的内存概念,有别于虚拟内存。
- 表格中不存在
container_memory_swap以及container_memory_max_usage_bytes, 这两个没有歧义不用在此讨论
注:
active_file:活跃 LRU 列表中所有 file-backed 进程使用内存。
inactive_file:不活跃 LRU 列表中所有 file-backed 进程使用内存。Linux内核使用LRU(Least Recently Used)算法来管理活动和非活动缓存,当内存需要被回收时,系统会首先考虑回收非活动缓存,而保留活跃缓存。
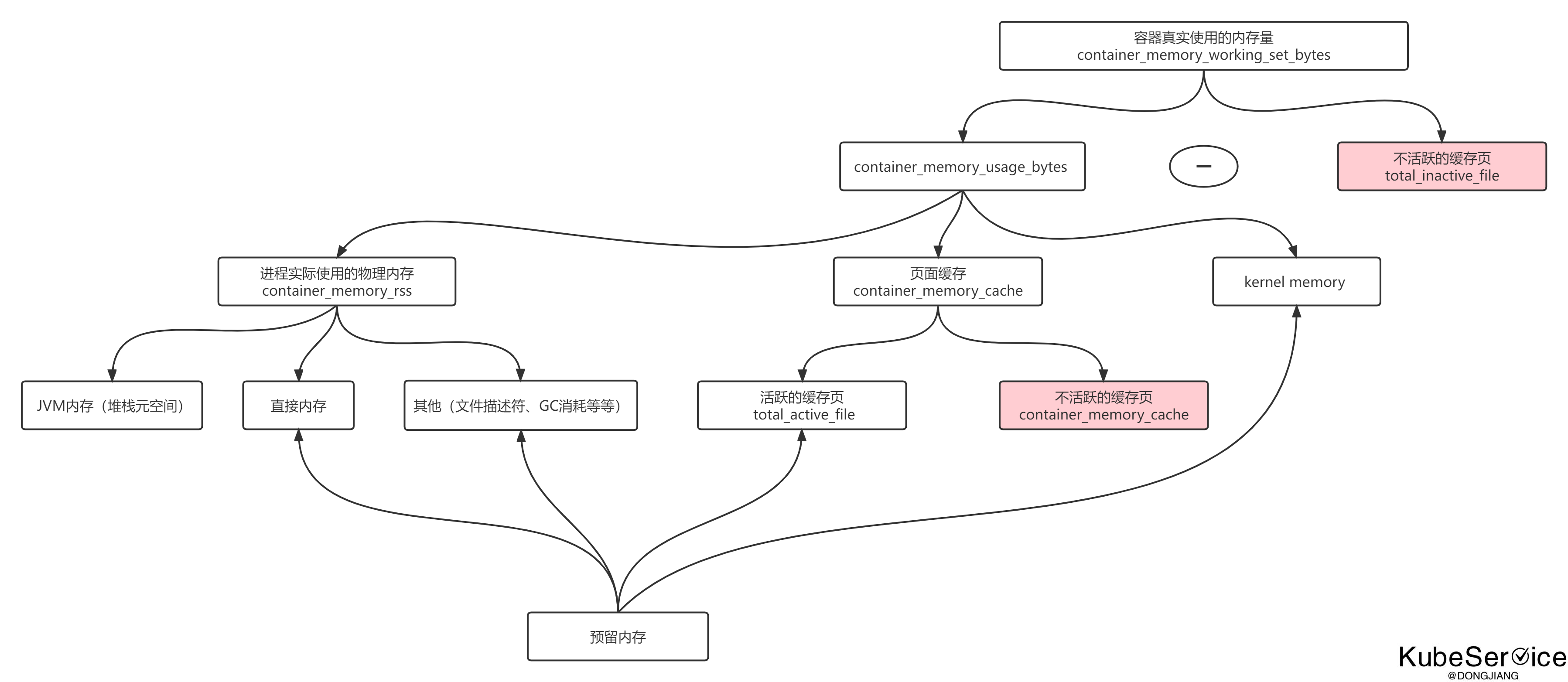
注: 该图引用于这里,原作者画的有识破,图中下面这个红色的应该是total_inactive_file
PageCache相关参数
Linux内存水位控制与可用内存计算中存在两个水位:
- low watermark:当 free 内存低于 low watermark 时触发异步内存回收
- min watermark:当内存低于 min watermark 时暂停内存分配,立即进行内存回收
也就是说系统中剩余的内存不能低于min watermark,这是一个操作系统的保护机制:预留一部分内存给内存回收等关键程序使用。
可以通过 cat /proc/zoneinfo 看到 min watermark 的取值,单位是页。
从上面的几个例子中可以看到PageCache的使用也会引起OOM的产生, linux中有以下参数可以控制pagecache的行为:
1 | `vm.vfs_cache_pressure`是一个内核参数,控制 Linux 系统如何平衡 inode 和 dentry 缓存(VFS 缓存)的回收与匿名内存(进程使用的堆栈、数据段等)回收之间的优先级 |
当然,还有一些其它的内存对象如Slab Cache等, 不再此讨论。
参考文章:
- https://izsk.me/2022/12/30/Kubernetes-emptyDir/
- https://izsk.me/2023/02/09/Kubernetes-Out-Of-Memory-1/
- https://izsk.me/2023/02/15/Kubernetes-Out-Of-Memory-2/
- https://help.aliyun.com/zh/alinux/support/causes-of-and-solutions-to-the-issue-of-oom-killer-being-triggered
- https://blog.hdls.me/17255242628777.html
- https://blog.lv5.moe/p/from-k8s-pod-memory-usage-to-linux-memory-management
- https://faun.pub/how-much-is-too-much-the-linux-oomkiller-and-used-memory-d32186f29c9d
- https://kubeservice.cn/2024/06/24/fault-k8s-pod-container-memory-high/