volcano如何应对大规模任务系列之volcano插件系统
volcano做为CNCF目前唯一一款应对大规模资源批调度工具被大家熟知.
作者负责的kubernetes集群每天都有大量的任务需要运行, GPU任务、短任务、长任务等等,同时还存在多租户场景、复杂的调度策略等, 依托volcano的高度可插拔能力, 同时结合业务场景进行相应的优化,极大提高了资源使用效率,结果导向明显
在此也分享一下整个落地过程,也做为现阶段的一个工作总结, 工作之余尽量更新.
注: 业务各有不同, 作者的选型及观点可能并不适用其它人
此篇为: volcano如何应对大规模任务系列之volcano插件系统
总体分为以下几块内容:
volcano如何应对大规模任务系列之volcano开篇介绍
volcano如何应对大规模任务系列之volcano关键对象
volcano如何应对大规模任务系列之volcano插件系统
volcano如何应对大规模任务系列之volcano源码解析
volcano如何应对大规模任务系列之volcano优化之道
volcano如何应对大规模任务系列之volcano生产实践
volcano如何应对大规模任务系列之volcano总结建议
本系列的所用volcano版本基于v1.7.0
工作流
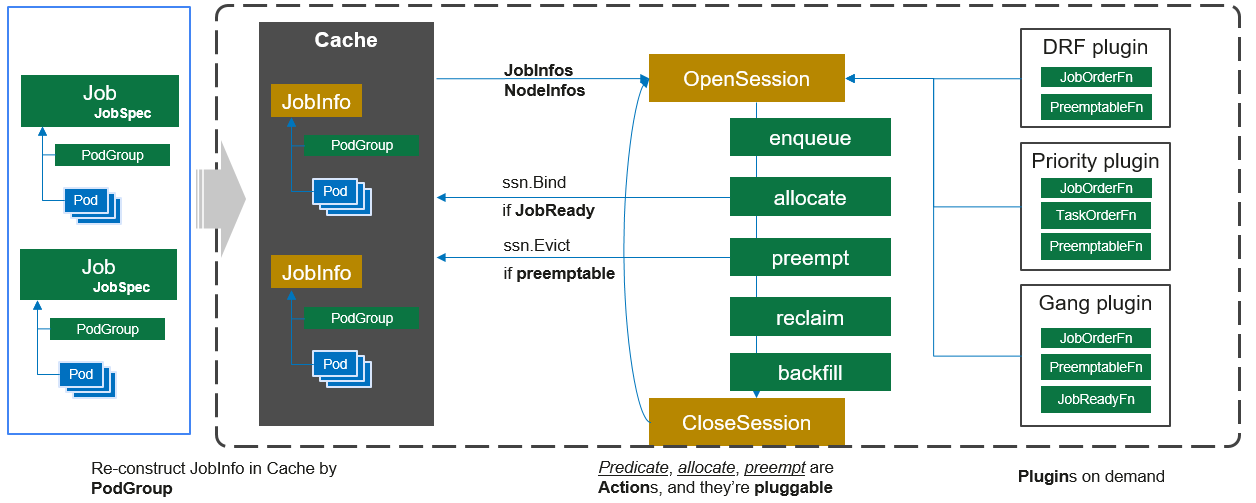
再来简单说一下volcano的调度流程:
每隔一个调度周期(默认是1s)开启一个Session对象,这个Session的初始化将集群中的节点、任务和队列的信息都会拷贝一份做为副本cache起来,然后依次执行action, action中会引用各plugin插件的实现逻辑
现在支持的插件列表主要可归为以下几类:
容量相关: 如proportion、capacity、resourcequota等
节点相关: nodegroup、usage、numaaware等
任务相关: 剩下的基本就跟任务相关,比如priority、gang等
Configuration
这里以一个典型的volcano配置为例展开
1 | # default configuration for scheduler |
首先解释一下这里为什么要分为多层的tiers?
在网上看到这个解释我觉得讲的清晰
每个plugin 注册了一堆函数,action 会在会在适当的实际调用Session.函数()执行。Session.函数()的大体逻辑都是遍历plugin 注册的所有函数并执行,每个plugin 只注册了跟自己逻辑有关的函数。
Session.函数()核心逻辑是两层循环,分为三种情况:
“一言不合”直接返回的
1
2
3
4
5
6
7
8
9
10func (ssn *Session) xx() xx{
for _, tier := range ssn.Tiers {
for _, plugin := range tier.Plugins {
if(xx){
return xx
}
}
}
return xx
}所有plugin 一起配合计算的,比如给某个node 打分
1
2
3
4
5
6
7
8func (ssn *Session) xx() xx{
for _, tier := range ssn.Tiers {
for _, plugin := range tier.Plugins {
sum += xx
}
}
return sum
}tier内 的所有plugin 参与计算。比如 Reclaimable 决定回收哪些正在运行的pod,即寻找victim。如果在第一层tier 中可以找到牺牲者 就直接返回了,毕竟能牺牲少点就牺牲少点,实在不行,才会计算第二层tier。
1
2
3
4
5
6
7
8
9
10func (ssn *Session) xx() xx{
var victims []*api.TaskInfo
for _, tier := range ssn.Tiers {
for _, plugin := range tier.Plugins {
// 寻找victim
}
if victims != nil {
return victims
} }
return nil前两种情况,是不需要区分两层的,此时所有的plugin 先后顺序是重要的,是不是在一个tier 里不重要,即要么立即结束要么全局聚合。第三种情况, tier内 的plugin局部聚合,两层for 之间做判断,如果有数据则 return。以默认的配置文件
scheudler.conf来说,第一个tier 更多是基于用户设置,第二个tier 是基于task 和集群的实际情况,以用户设置为优先。
要注意一点的是:如果config里配置的语法有误,比如当格式不对时,volcano-scheuler是不会panic退出的,它会直接使用内置的默认配置进行启动,我就在某一次配置变更时多写了一个冒号未及时发现,导致所有的调度策略都以意料之外的方式进行,跑了几天后才发现问题
actions
在volcano如何应对大规模任务系列之volcano关键对象一节中已经把现有的action对象都介绍了一遍, 这里不再赘述
action在volcano中就像流水线,从上面的工作流图中可以看出,在一个session开始时,会将cache中拿到的所有相关的信息依次经过configuration中配置的action列表, 然后action中调用各插件的逻辑。
actions列表也是可选择的, 这里以enqueue为例。
enqueue校验pending job是否满足容量相关的条件, 如果满足,则可以从pending状态转到inqueue状态,那容量条件都有哪些呢? 从pkg/scheduler/actions/enqueue.go中可以看到
1 | // 省略 代码其它 |
enqueue.go中存在ssn.JobEnqueueable(job), JobEnqueueable目前只在proportion、capacity、resourcequota三个plugin中有相关实现(如何知道???),从上面的配置文件来看,第一层的plugin并没有与容量相关的插件(如何知道???),因此第一层会直接弃权(或者叫通过),来到第二层,第二层里注册了proportion、resourcequota二个与容量相关的插件,那么这2个插件中一定会有JobEnqueueable的相关实现,这里以proportion为例
1 | // pkg/scheduler/plugins/proportion/proportions.go |
同样,在resourcequota plugin中也同样会有相同的逻辑,这两个插件需要同时满足,ssn.JobEnqueueable(job)才会满足,
这也很好理解, proportion是与queue的容量相关, 如果queue的容量无法满足这个job,那它自然需要继续pending,同理resourcequota是与namespacequota的容量相关,如果namespace的resourcequota资源无法满足这个job,那它还是需要pending。
当然也可以不配置enqueue这个action,那么所有的待调度的pending状态的job默认都直接到达inqueue状态
1 | // pkg/scheduler/actions/allocate.go |
篇幅有限,源码以及上下文并没有说的很清楚,后续会有更详细的代码走读
由于actions相对来说比较稳定,其中的很多功能都是由plugin实现的,plugins才是volcano中自由扩展的利器。
plugins
在pkg/scheduler/actions/plugins下, 每一个目录实现了一种插件, 这些插件在调度过程会提供特定逻辑, 这里以priority为例来说明插件是什么时候起作用.
先试想一种典型的场景: 在集群中, 一般会存在紧急程度不一的各类job(这里的job是一种统称,可以是batchjob/pytorchjob/volcanojob/deployment等等吧), 但是资源是永远不够的,那么我们期望的是在有限的资源下, 优先让紧急/重要的job先运行起来, 不紧急的job可以排队
那priority如何发挥作用? 通过上面我们得知, plugins只在actions中”调用”,因此,当进入到enqueue action时
对于所有的jobs, enqueue会通过jobOrderFn这类的函数对所有的job进行排序, 排序的方法就在pkg/schedule/plugins/priority/priority.go中实现,方法可以是多样的,比如可以按PriorityClass、按创建时间等等,还自定义排序逻辑,只要能比对即可,最终生成一个heap map来存放所有job排序之后的结果提供到下一环节
1 | // pkg/scheduler/actions/enqueue.go |
来看看pkg/schedule/plugins/priority/priority.go对jobOrderFn的实现
1 | // 其它代码 |
很简单,将jobOrderFn add到ssn的AddJobOrderFn中,jobOrderFn接受两上jobinfo的对象,通过比对这两个对象的Priority大小返回
当然, jobOrderFn可以在多个action中进行注册. enqueue是一种场景,preempt是另外一种场景, 按优先级进行回收, 即先回收优先级低的job, 那么在preempt中就会需要通过ssn.JobOrderFn来引用
说的可能会有些乱,比如上面的疑问,我怎么知道一个action中会调用哪些plugin, 或者说一个plugin都在哪些action中起作用以及在volcano system中如何将job封装成volcano中的job, pod如何封装成volcano中的task, 这些确实需要对照代码才能更加清晰, 好在volcano的代码风格还是比较统一, 有很多约定俗成的写法, 有些疑问可以先暂放,等走读代码后会有一个更直观的体验
如何将volcano结合进业务中发挥最大的价值,这个需要结合业务特性才能得出最符合业务架构的生产实践