Kubernetes之ListOptions使用不当引发的ETCD网络风暴
最近排查了一个因业务层使用List接口时因listOptions参数使用不当引起的etcd压力极速增长的问题,顺着listOptions把源码过了一遍, 知识又涨不少.
业务背景
kubernetes为任务型集群, 每天的任务量2k-4k, job保留时长为3天
问题现象
在某个时刻,多个业务方反应如下情况:
- 发布任务很慢,很久才能running起来
- 任务状态不对,有的任务实际已经执行完了,但过了很久状态才变成completion
问题排查
apiserver
在业务方反映的问题的同时,收到了关于apiserver的监控告警, 这个指标: KubeAPIErrorBudgetBurn,
long/short时间内都出现了告警,给作者的第一感觉就是apiserver响应不过来了,接着查看监控dashboard, 发现apiserver的内存上涨很多,同时,Read/Write SLI Duration相关的指标都有明显的延时,特别是对于pod的Read SLI Duration, 涨了数十倍之多,这显然是不正常
然后查看apiserver的日志,同样出现很多List请求10s timeout, 日志如下:
1 | List etcd3 key "xxx" ,resourceVersion:, resourceVersionMatch:,limit: 0, continue: xxx, total: 10002ms |
这段日志很重要,下文分解
难道是etcd扛不住了???
简单解释下上述提到的3个指标:
KubeAPIErrorBudgetBurn: 按照时间范围长短分为紧急及不紧急,不紧急的不要求立刻解决,可能apiserver自己会慢慢消化,而紧急的则建议立即处理, 链接中有一些promsql可以查看具体的metrics.
Read SLI Duration: 对应prometheus中的promsql: 统计apiserver_request_total中verb为read的所有请求的SLI Duration,这是一个融合查询, 统计了在某个时间范围内所有的write操作的时延,如get、list请求
Write SLI Duration: 对应prometheus中的promsql: 统计apiserver_request_total中verb为write的所有请求的SLI Duration,这是一个融合查询, 统计了在某个时间范围内所有的write操作的时延, 如update、create等请求
etcd
接着查看etcd的监控dashboard, 发现etcd实例的内存同样上涨很多, etcd_network_client_grpc_received_bytes_total倒是很正常
但是另一个关键指标: etcd_network_client_grpc_send_bytes_total,5分钟的增量达到了惊人的500-600Mb/s, 1分钟的增量更是到了Gb/s ,显然不正常
这里也简单介绍下这2个metrics(来自ChatGPT):
etcd_network_client_grpc_send_bytes_total: 此指标衡量了通过 gRPC 客户端接收的总字节数,表示 etcd 通过客户端接收的网络流入量(以字节为单位)。
etcd_network_client_grpc_received_bytes_total:相反,此指标衡量了通过 gRPC 客户端发送的总字节数,表示 etcd 通过客户端发送的网络流出量(以字节为单位)
etcd_network_client_grpc_received_bytes_total常态下很小可以理解,因为只是原始请求,最多带一些参数也不可能很大
但是etcd_network_client_grpc_send_bytes_total这个值很大,说明etcd要反馈给client端的数据量很大,第一时间想到的就是是不是有LIST接口使用不当查询了全量数据
问题解决
结合上面在apiserver日志中看到了相关的接口:
1 | List etcd3 key "xxx" ,resourceVersion:, resourceVersionMatch:,limit: 0, continue: xxx, total: 10002ms |
可以看出有一个list接口中resourceVersion及limit都没有设置,而且时间都超过了10s, 有一些还引发了timeout.
所以第一时间优先排查这个LIST接口, 果然,在某个java业务(使用的是fabricio8/kubernetes-client库)新增了一个接口,功能是想每隔3秒查询一次某个namespace下某job下的所有pod状态,但是使用LIST时因参数使用不当导致在etcd中返回了全量数据,集群中存在大量的job数据量很庞大,由于出现问题时刚好是任务高峰期且任务的时效性非常重要, 对于这个接口是否合理的讨论并没有做为第一优先讨论的,采取优先解决问题的做法,使用了一个最简单的修复方式上线,即在这个接口中指定resourceVerison=0
上线一段时间后观察所有的监控指标都趋于正常
问题解决
那么抛出另一个问题,为什么在list中指定了resourceVersion=0就能解决问题呢?
问题复盘
问题在一开始时从apiserver的日志中就已经反应出来了, 也第一时间推动业务进行了调整,但要深入探讨起来,需要说的东西还不少
为什么在list中指定了resourceVersion=0就能解决问题呢?
要回答这个问题,那么就得把数据在etcd及kube-apiserver中是如何存储及处理的说起
一个实际 etcd 集群存储的数据量可能很小,GB级别,甚至足够缓存到内存中。它的并发请求数量可能会高几个量级,单个 LIST 请求可能只需要返回几十 MB 到上 GB 的流量,但并发请求一多,etcd 显然也扛不住,所以最好在前面有 一层缓存,这就是 apiserver 的功能(之一)。K8s 的 LIST 请求大部分都应该被 apiserver 挡住,从它的本地缓存提供服务,但如果使用不当,就会跳过缓存直接到达 etcd,有很大的稳定性风险。
kube-apiserver LIST 请求处理逻辑可以看到下图原图地址:
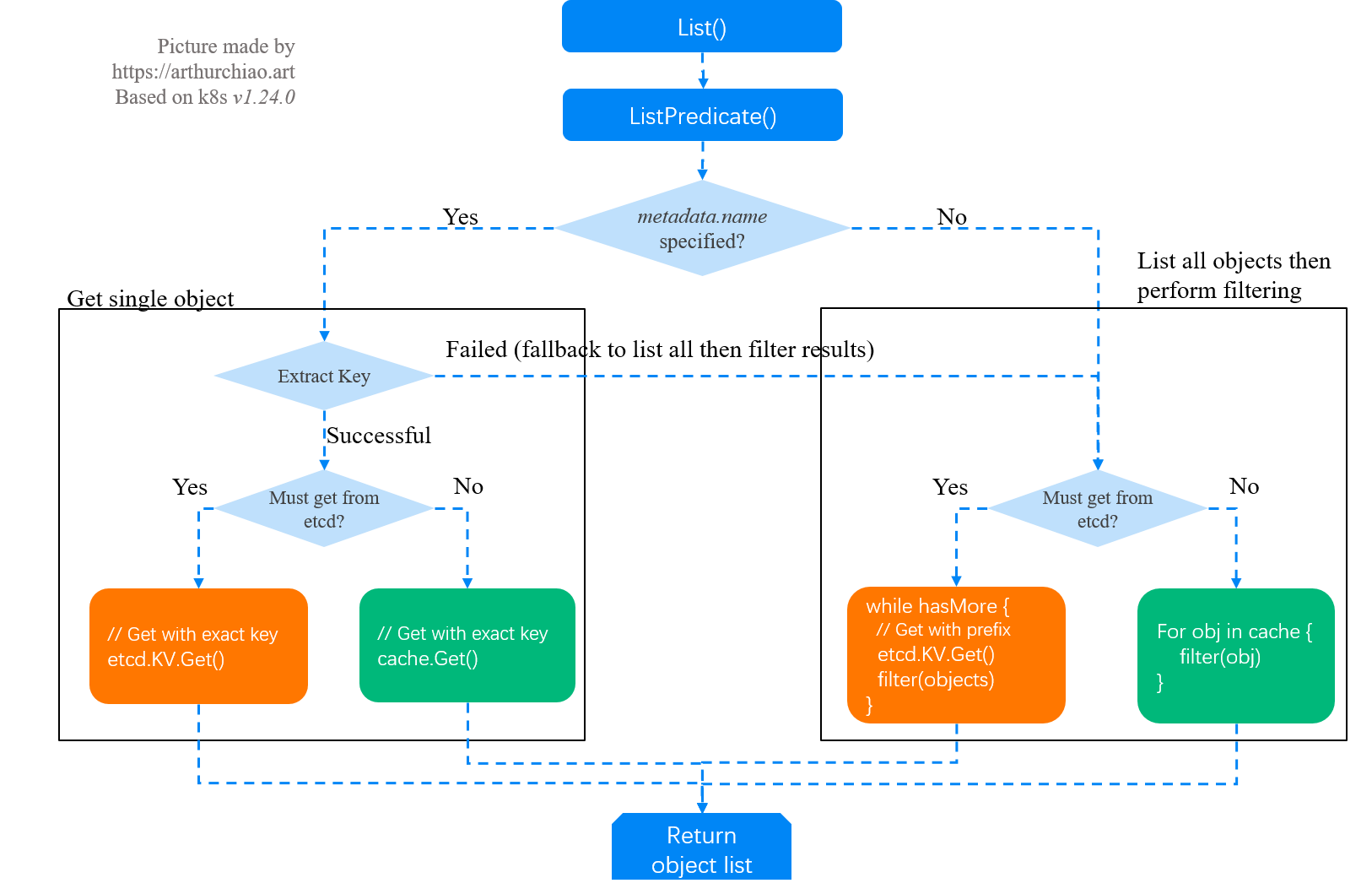
以上可以看到,系统路径中存在两级 List/ListWatch(但数据是同一份):
- apiserver List/ListWatch etcd
- 其它对象如controller/operator List/ListWatch apiserver
因此,从最简形式上来说,apiserver 就是挡在 etcd 前面的一个代理(proxy),
1 | +--------+ +---------------+ +------------+ |
绝大部分情况下,apiserver 直接从本地缓存提供服务(因为它缓存了集群全量数据);
某些特殊情况,例如如下比较常见的2种:
- 客户端明确要求从 etcd 读数据(追求最高的数据准确性),
- apiserver本地缓存还没建好
apiserver就只能将请求转发给 etcd, 这里就要特别注意了客户端 LIST 参数设置不当也可能会走到这个逻辑
常见的List请求可归类为两种:
- List 全量数据:开销主要花在数据传输;
- List指定用 label 或字段(field)过滤,只需要匹配的数据。
这里需要特别说明的是第二种情况,也就是 list 请求带了过滤条件,不要以为list带了过滤条件就不会全量查询etcd,也分两种情况:
大部分情况下,apiserver 会用自己的缓存做过滤,走缓存的操作很快,直接从apiserver的内存中就可以返回,因此耗时主要花在数据网络传输
需要将请求转给 etcd 的情况
注意,etcd 只是 KV 存储,并不理解 label/field 信息,因此在etcd层面无法处理过滤请求。 实际的过程是:apiserver 从 etcd 拉全量数据,然后在内存做过滤,再返回给客户端。因此除了数据传输开销(网络带宽),这种情况下还会占用大量 apiserver CPU 和内存
以几个常见的LIST请求为例:
LIST apis/cilium.io/v2/ciliumendpoints?limit=500&resourceVersion=0这里同时传了两个参数,但
resourceVersion=0会导致 apiserver 忽略limit=500, 所以客户端拿到的是全量 ciliumendpoints 数据。但由于指定了resourceVersion=0, 所以虽然是全量数据,但是会直接从apiserver的缓存中返回。
LIST api/v1/pods?fieldSelector=spec.nodeName%3Dnode1这个请求是获取
node1上的所有 pods(%3D是=的转义)。根据 nodename 做过滤,给人的感觉可能是数据量不太大,但其实背后要比看上去复杂:
- 首先,这里没有指定 resourceVersion=0,导致 apiserver 跳过缓存,直接去 etcd 读数据;
- 其次,etcd 只是 KV 存储,没有按 label/field 过滤功能(只处理
limit/continue),所以apiserver 是从 etcd 拉全量的pod数据,然后在内存做fieldselector过滤,开销也是很大的
这种行为是要避免的,除非对数据准确性有极高要求,特意要绕过 apiserver 缓存。
LIST api/v1/pods?filedSelector=spec.nodeName%3Dnode1&resourceVersion=0跟 2 的区别是加上了
resourceVersion=0,因此 apiserver 会从缓存读数据,性能会有量级的提升。但要注意,虽然实际上返回给客户端的可能只有几百 KB 到上百 MB, 但 apiserver 需要处理的数据量可能是几个 GB。
以上可以看到,不同的 LIST 操作产生的影响是不一样的,而客户端看到数据还有可能只是 apiserver/etcd 处理数据的很小一部分。如果基础服务大规模启动或重启, 就极有可能把控制平面打爆。
总结一下resourceVersion作用: 保证客户端数据一致性和顺序性,乐观锁,实现并发控制
设置ListOptions时,resourceVersion有三种设置方法:
- 不设置(不传递ListOptions或者不设置resourceVersion字段),此时会直接从etcd中读取,此时数据是最新的
- 设置为”0”,此时会从API Server Cache中获取数据
- 设置为指定的resourceVersion,获取resourceVersion大于指定版本的所有资源对象
分析源码
从上面可以看出resourceVersion的重要性,现在来看看代码,以client-go为例list Jobs
1 | // ListJobs lists all jobs details. |
最重要的是metav1.ListOptions{}这个结构体,在很多的operator的代码中,大量地使用上述这种写法,可能有人会很奇怪,按照上面的说法,这不是没有传递参数么,它不是会全量获取数据吗?
别着急,来看一下它的定义,由于代码过长,这里就不全贴
1 | type ListOptions struct { |
定义中ResourceVersion默认为unset, 但是在client-go中 的 ListWatch/informer 接口, 那它默认已经设置了 ResourceVersion=0(如果客户端没传 ListOption,则初始化一个默认值,其中的 ResourceVersion 设置为空字符串),这也就是为什么写operator时会直接传递metav1.ListOptions{}(ResourceVersion具体的设置方法将在下一篇中进行分析)
但是在其它语言的kubernetes client中就不一定,比如java fabric8 client中,可能就需要显式地指定resourceVersion
问题总结
所以可以看到,某些请求看起来很简单,只是客户端一行代码的事情,但背后的数据量是惊人的,集群规模比较小的时候,这个问题可能看不出来(etcd 在 LIST 响应延迟超过某个阈值 后才开始打印 warning 日志);规模大了之后,如果这样的请求比较多,apiserver/etcd 肯定是扛不住的。
其实,业务层每3秒去list resource结果显然也是不合适的,这本就是watch要做的事情,这是后续在稳定性上要推进业务的todo之一
更多参数
这里官方resourceVersion-in-metadata有个表格来说明Get/List接口中的一些参数
ListOptions{}
| resourceVersionMatch param | paging params | resourceVersion not set | resourceVersion=”0” | resourceVersion=”{value other than 0}” |
|---|---|---|---|---|
| unset | limit unset | Most Recent | Any | Not older than |
| unset | limit= |
Most Recent | Any | Exact |
| unset | limit= |
Continue Token, Exact | Invalid, treated as Continue Token, Exact | Invalid, HTTP 400 Bad Request |
resourceVersionMatch=Exact |
limit unset | Invalid | Invalid | Exact |
resourceVersionMatch=Exact |
limit= |
Invalid | Invalid | Exact |
resourceVersionMatch=NotOlderThan |
limit unset | Invalid | Any | Not older than |
resourceVersionMatch=NotOlderThan |
limit= |
Invalid | Any | Not older than |
GetOptions{}
基本原理与 ListOption{} 一样,不设置 ResourceVersion=0 会导致 apiserver 去 etcd 拿数据,应该尽量避免
| resourceVersion unset | resourceVersion=”0” | resourceVersion=”{value other than 0}” |
| Most Recent | Any | Not older than |
- Most Recent:去 etcd 拿数据;
- Any:优先用最新的,但不保证一定是最新的;
- Not older than:不低于某个版本号。
未完待续
上面【分析源码】一节中只是说明了可以通完传递resourceVersion=0给list以达到通过apiserver的缓存返回数据减少etcd的压力,但还有些其它情况apiserver的判断逻辑是如何的呢,比如确实是需要直接从etcd获取数据以保证数据是最新的,或者缓存没有建设又该如何及client-go中对resourceVersion判断赋值操作?
下回源码阅读分解