理解NUMA架构
最近在研究kubernetes下NUMA架构的支持, 看到一篇关于NUMA的博文,就尝试翻译成了中文, 原文地址: Understanding NUMA Architecture
设计电脑总是一种妥协。计算机的四个基本部件——中央处理单元(CPU)或处理器、内存、存储器和连接部件的电路板(I/O总线系统)——被尽可能巧妙地组合在一起,以创造出一台既划算又强大的机器。设计过程主要涉及处理器(协处理器、多核设置)、内存类型和数量、存储(磁盘、文件系统)以及价格的优化。协同处理器和多核架构背后的理念是,在尽可能小的空间中,将操作分配到尽可能多的单个计算单元,并使并行执行计算指令更容易获得和负担得起。就内存而言,这是一个可以由单个计算单元处理的数量或大小的问题,以及哪种内存类型具有尽可能低的延迟。存储属于外部内存,其性能取决于磁盘类型、正在使用的文件系统、线程、传输协议、通信结构和附加的内存设备的数量。
I/O总线的设计代表了计算机的主干,并显著地决定了上面列出的单个组件之间可以交换多少数据和多快的数据。排名第一的是用于高性能计算(HPC)领域的组件。截至2020年年中,高性能计算的当代代表产品有英伟达特斯拉和DGX、Radeon Instinct和英特尔Xeon Phi gpu加速器产品(产品对比见[引用1,2])。
理解NUMA
非统一内存访问(NUMA)描述了当代多处理系统中使用的共享内存架构。NUMA是一个由多个节点组成的计算系统,所有节点共享聚合的内存:每个CPU被分配自己的本地内存,并且可以从系统中的其他CPU访问内存,见[引用12,7]。
NUMA是一个巧妙的系统,用于将多个中央处理单元(CPU)连接到计算机上任何数量的可用内存。单个NUMA节点通过可伸缩网络(I/O总线)连接,这样CPU就可以系统地访问与其他NUMA节点关联的内存。
本地内存是CPU在特定NUMA节点中使用的内存。外部或远程内存是CPU从另一个NUMA节点获取的内存。术语NUMA比率描述了访问外部内存成本与访问本地内存成本的比率。比例越大,成本就越大,因此访问内存所需的时间就越长。
但是,它所花费的时间比CPU访问它自己的本地内存要长。本地内存访问是一个主要的优势,因为它结合了低延迟和高带宽。相比之下,访问属于任何其他CPU的内存具有更高的延迟和更低的带宽性能。
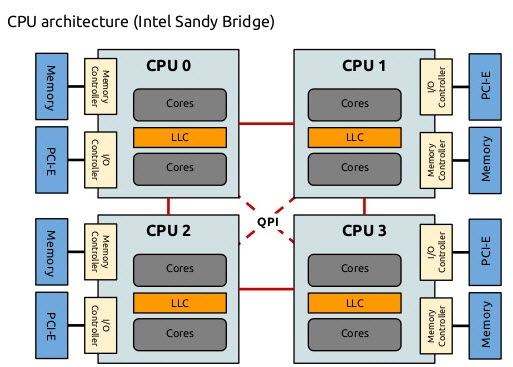
回顾:共享内存多处理器的发展
Frank Dennemann[引用8]指出,现代系统架构不允许真正的统一内存访问(UMA),即使这些系统是专门为此目的而设计的。简单地说,并行计算的思想是让一组处理器协同计算给定的任务,从而加快传统的顺序计算。
正如Frank Dennemann[引用8]所解释的那样,在20世纪70年代早期,随着关系数据库系统的引入,“对能够服务多个并发用户操作和过多数据生成的系统的需求成为主流”。“尽管单处理器的性能令人印象深刻,但多处理器系统能够更好地处理这种工作负载。为了提供性价比高的系统,共享内存地址空间成为研究的重点。早期,使用交叉开关的系统被提倡,然而随着这种设计的复杂性随着处理器的增加而增加,这使得基于总线的系统更有吸引力。总线系统中的处理器(可以)通过在总线上发送请求来访问整个内存空间,这是一种尽可能优化地使用可用内存的非常划算的方式。”
然而,基于总线的计算机系统有一个瓶颈——有限的带宽会导致可伸缩性问题。系统中添加的cpu越多,每个节点可用的带宽就越少。此外,添加的cpu越多,总线就越长,因此延迟就越高。
大多数cpu都是在二维平面上构建的。cpu还必须添加集成内存控制器。对于每个CPU核心,有四个内存总线(上、下、左、右)的简单解决方案允许完全可用的带宽,但仅此而已。cpu在很长一段时间内都停滞在4核状态。当芯片变成3D时,在上面和下面添加痕迹允许直接总线穿过对角线相反的cpu。在卡上放置一个四核CPU,然后连接到总线,这是合乎逻辑的下一步。
如今,每个处理器都包含许多核心,这些核心都有一个共享的片上缓存和片外内存,并且在服务器内不同内存部分的内存访问成本是可变的。
提高数据访问效率是当前CPU设计的主要目标之一。每个CPU核都被赋予了一个较小的一级缓存(32 KB)和一个较大的二级缓存(256 KB)。各个核心随后共享几个MB的3级缓存,其大小随着时间的推移而大幅增长。
为了避免缓存丢失(请求不在缓存中的数据),需要花费大量的研究时间来寻找合适的CPU缓存数量、缓存结构和相应的算法。关于缓存snoop协议[引用4]和缓存一致性[引用3,5]的更详细的解释,以及NUMA背后的设计思想,请参见[引用8]。
NUMA的软件支持
有两种软件优化措施可以提高支持NUMA架构的系统的性能—处理器关联性和数据放置。正如[引用19]中解释的那样,“处理器关联[…]允许将进程或线程绑定到单个CPU或一系列CPU,以便进程或线程只在指定的CPU或CPU上执行,而不是在任何CPU上执行。”术语“数据放置”是指将代码和数据尽可能地保存在内存中的软件修改。
不同的UNIX和UNIX相关操作系统通过以下方式支持NUMA(以下列表来自[引用14]):
- Silicon Graphics IRIX支持ccNUMA架构超过1240 CPU与Origin服务器系列。
- Microsoft Windows 7和Windows Server 2008 R2增加了对64个逻辑核上NUMA架构的支持。
- Linux内核的2.5版本已经包含了基本的NUMA支持,在后续的内核版本中得到了进一步的改进。Linux内核的3.8版带来了新的NUMA基础,允许在以后的内核版本[引用13]中开发更有效的NUMA策略。Linux内核的3.13版本带来了大量的策略,旨在将进程放在靠近其内存的位置,以及对各种情况的处理,例如在进程之间共享内存页,或使用透明的巨大页;新的系统控制设置允许启用或禁用NUMA平衡,以及配置各种NUMA内存平衡参数[引用15]。
- Oracle和OpenSolaris都采用了引入逻辑组的NUMA架构。
- FreeBSD在11.0版本中添加了初始NUMA亲和性和策略配置。
蔡宁在《Computer Science and Technology, Proceedings of the International Conference (CST2016)》一书中提出NUMA架构的研究主要集中在高端计算环境,提出了NUMA-aware Radix Partitioning (NaRP),优化NUMA节点中的共享缓存的性能,以加速商业智能应用程序。因此,NUMA代表共享内存(SMP)系统与几个处理器[引用6]之间的中间地带。
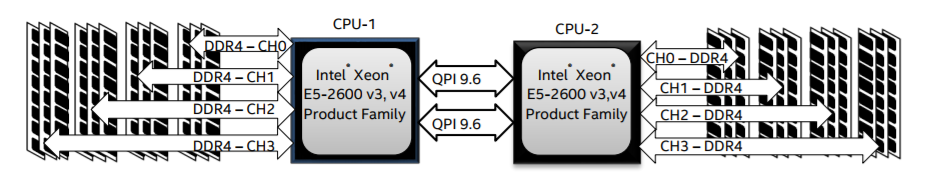
NUMA和Linux
如上所述,Linux内核从版本2.5开始就支持NUMA了。Debian GNU/Linux和Ubuntu都提供numactl[引用16]和numad[引用17]两个软件包对进程优化的NUMA支持。在numactl命令的帮助下,您可以列出系统[引用18]中可用NUMA节点的清单:
1 | # numactl --hardware |
NumaTop是Intel开发的一个有用的工具,用于监视运行时内存位置和分析NUMA系统中的进程[引用10,11]。该工具可以识别潜在的NUMA相关性能瓶颈,从而帮助重新平衡内存/CPU分配,以最大限度地发挥NUMA系统的潜力。有关更详细的描述,请参阅[引用9]。
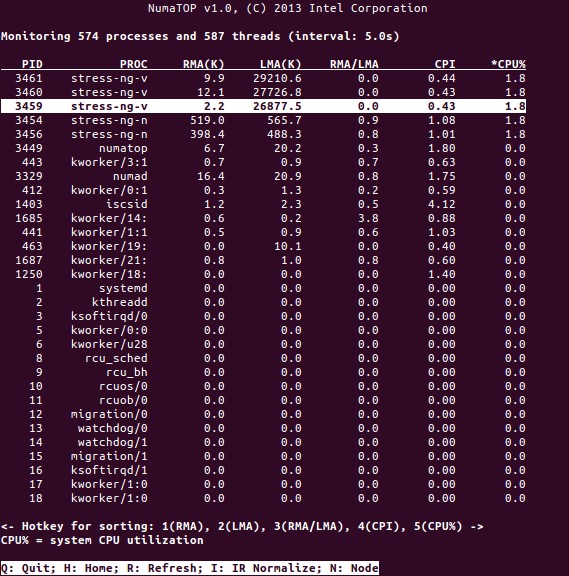
使用场景
支持NUMA技术的计算机允许所有cpu直接访问整个内存——cpu将其视为一个单一的线性地址空间。这可以更有效地使用64位寻址方案,从而更快地移动数据、更少地复制数据、更容易地进行编程。
NUMA系统对于服务器端应用程序非常有吸引力,比如数据挖掘和决策支持系统。此外,有了这种架构,为游戏和高性能软件编写应用程序变得更加容易。
结论
总之,NUMA架构解决了可伸缩性问题,这是它的主要优点之一。在NUMA CPU中,一个节点将拥有更高的带宽或更低的延迟来访问同一节点上的内存(例如,本地CPU在远程访问的同时请求内存访问;优先级在本地CPU上)。如果将数据本地化到特定的进程(以及处理器),这将显著提高内存吞吐量。缺点是将数据从一个处理器移动到另一个处理器的成本较高。只要这种情况不经常发生,NUMA系统将优于具有更传统架构的系统
引用
- Compare NVIDIA Tesla vs. Radeon Instinct, https://www.itcentralstation.com/products/comparisons/nvidia-tesla_vs_radeon-instinct
- Compare NVIDIA DGX-1 vs. Radeon Instinct, https://www.itcentralstation.com/products/comparisons/nvidia-dgx-1_vs_radeon-instinct
- Cache coherence, Wikipedia, https://en.wikipedia.org/wiki/Cache_coherence
- Bus snooping, Wikipedia, https://en.wikipedia.org/wiki/Bus_snooping
- Cache coherence protocols in multiprocessor systems, Geeks for geeks, https://www.geeksforgeeks.org/cache-coherence-protocols-in-multiprocessor-system/
- Computer science and technology – Proceedings of the International Conference (CST2016), Ning Cai (Ed.), World Scientific Publishing Co Pte Ltd, ISBN: 9789813146419
- Daniel P. Bovet and Marco Cesati: Understanding NUMA architecture in Understanding the Linux Kernel, 3rd edition, O’Reilly, https://www.oreilly.com/library/view/understanding-the-linux/0596005652/
- Frank Dennemann: NUMA Deep Dive Part 1: From UMA to NUMA, https://frankdenneman.nl/2016/07/07/numa-deep-dive-part-1-uma-numa/
- Colin Ian King: NumaTop: A NUMA system monitoring tool, http://smackerelofopinion.blogspot.com/2015/09/numatop-numa-system-monitoring-tool.html
- Numatop, https://github.com/intel/numatop
- Package numatop for Debian GNU/Linux, https://packages.debian.org/buster/numatop
- Jonathan Kehayias: Understanding Non-Uniform Memory Access/Architectures (NUMA), https://www.sqlskills.com/blogs/jonathan/understanding-non-uniform-memory-accessarchitectures-numa/
- Linux Kernel News for Kernel 3.8, https://kernelnewbies.org/Linux_3.8
- Non-uniform memory access (NUMA), Wikipedia, https://en.wikipedia.org/wiki/Non-uniform_memory_access
- Linux Memory Management Documentation, NUMA, https://www.kernel.org/doc/html/latest/vm/numa.html
- Package numactl for Debian GNU/Linux, https://packages.debian.org/sid/admin/numactl
- Package numad for Debian GNU/Linux, https://packages.debian.org/buster/numad
- How to find if NUMA configuration is enabled or disabled?, https://www.thegeekdiary.com/centos-rhel-how-to-find-if-numa-configuration-is-enabled-or-disabled/
- Processor affinity, Wikipedia, https://en.wikipedia.org/wiki/Processor_affinity
感谢
作者要感谢Gerold Rupprecht在准备本文时的支持。
关于作者
- 普莱克斯·内翰达(Plaxedes Nehanda)是一位多才多艺、自我驱动的多面手,他身兼多种职务,其中包括活动策划、虚拟助理、转录员以及热心的研究员,现居南非约翰内斯堡。
- Prince K. Nehanda是位于津巴布韦哈拉雷的paflow Metering公司的仪器和控制(计量)工程师。
- 弗兰克·霍夫曼(Frank Hofmann)在路上工作——最好是来自德国柏林、瑞士日内瓦和南非开普敦——他是Linux- user和Linux Magazine等杂志的开发者、培训师和作者。他也是Debian包管理书籍(http://www.dpmb.org)的合著者。