工程侧如何加速模型训练
模型训练除了算法侧需要优化之外,工程师也可以做很多落地来加速这个过程,今天就结合作者在落地训练平台的经验来聊一聊其中常用技术.
训练常常提到的单机单卡,单机多卡,多机多卡以及数据并行及模型并行的概念(作者并不是算法研究工作者,也没有能力深入了解其代码细节,所以接下来只会广义上引出一些概念)
GPU使用
单机单卡
这是最简单的一种方式, 使用一台机器上的一张卡运行任务, 常常用于本地调试目的,这个没什么好说的
单机多卡
有时只使用一张卡效率太慢,如果刚好一台机器上又有好几块GPU,那么自然就会想到是不是可以从单卡扩展到多卡上,同时在多张卡上运行
多机多卡
一般情况下,一台服务器可安装8块GPU,如果性能还是无法满足的情况下,就需要使用多机多卡方式了,从单机扩展到多机实现分布式
单机多卡和多机多卡(分布式)的区别:
- 单机多卡:只需运行一份代码,由该代码分配该台机器上GPU资源的使用
- 多机多卡:每台机器上都需要运行一份代码,机器之间需要互相通信传递梯度,并且模型参数的更新也存在同步训练模式和异步训练模式的区别
GPU并行
那么有以上几种对GPU的使用, 存在多GPU的情况下,又涉及到另一个问题就是: 多GPU之间如何协调数据、模型的关系呢?
显然要么把数据切分,要么把模型切分,业界大体以数据并行、模型并行的方式实现,而又以数据并行使用较多
数据并行
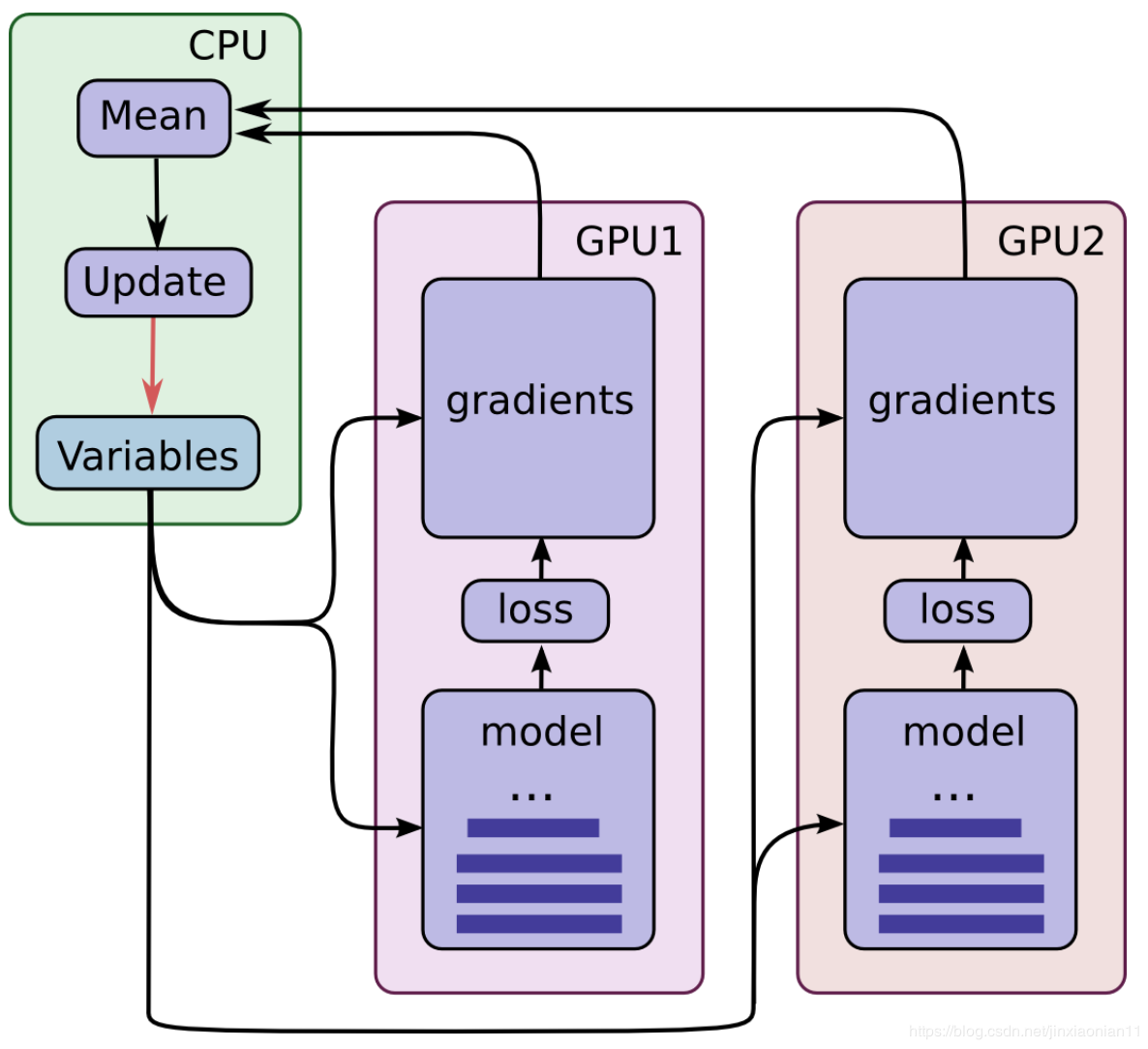
数据并行时,每个GPU设备上保持了同样的模型数据,且一次完整的训练过程包括以下3步:
- 1.CPU负责将不同的训练数据(mini-batch)分别喂给GPU0和GPU1设备;
- 2.不同的显卡设备上存储了完全一致的模型,通过mini-batch数据进行了前向和反向传播;
- 3.位于不同GPU设备上的模型进行权重同步和更新
其中第一点关心的是训练数据如何平均地分配给GPU,也就是dataloader, 这个大多数的训练框架都会实现
数据并行又分为同步、异步, 这里就不展开了
模型并行
相对于数据并行而言,模型并行就是将模型切成若干份放到若干GPU中(模型就是网络,分为很多层,我们可以将网络层切割分布到不同的GPU上)
关于模型并行作者所在的业务中几乎没有用到,而且网络上使用的也不是太多,作者了解不多,这里就不误人子弟了,有空的时候再详细研究研究
OK, 回到正题, 那么多卡的情况下,他们的通信如何加速呢?
加速训练
还是这张图
从这个图我们可以知道,不管是在单机多卡还是多机多卡训练场景下, 如果有parameter server参与,则ps很容易成为瓶颈, 如果想让速度更快,就成本而言,有那么下面几种方式:
成本小:
- 把训练时的单卡 batchsize 加大,将计算量增大而传输量不变
- 让研究员尽量训更大的网络,让他们多放点 Conv 而不是 FC,这让计算量增加的比参数量(即传输的数据量)更多一些
- 说服研究员不要坚持等价的 SGD,换用 ASGD,计算与通讯同时进行
成本小的方案一般需要通过调参得到最优解
成本大:
- 把 PS 变成多机版本,每台服务器管一部分 weight,从而带宽压力可以均摊到更多服务器上,降低传输量
- 依靠更好的硬件
- 机器间通讯:万兆网络是底线,Infiniband 和 RoCE 的带宽从 56Gbps 一直上升到 100Gbps 甚至 200Gbps,让 Mellanox 这家公司生意越来越好(现在被 NVIDIA 直接收购了)
- 机器内通讯:AMD 比牙膏厂更早支持 PCIe 4.0,让带宽翻了个倍;NVIDIA 搞出 NVLink,愣是把通讯带宽搞上了不可思议的 600Gb/s……
- Mellanox 表示:我们的智能 Switch 可以直接当 PS,我没带宽瓶颈!
直接换性能更好的硬件效果是立竿见影,就是太费钱, 所以要千方百计的降低传输,又引出了若干niubility的技术
RDMA
DMA全称为Direct Memory Access,即直接内存访问。意思是外设对内存的读写过程可以不用CPU参与而直接进行
如果说DMA解决的是本机外设直接操作内存的话,而RDMA则是Remote Direct Memory Access, 解决的对远程节点的内存直接访问
关于DMA,这篇博文写的不错,可以参考: 海思专家如何看待RDMA技术?
RDMA本身指的是一种技术,不是一类特定的产品, 具体协议层面,包含Infiniband(IB),RDMA over Converged Ethernet(RoCE)和internet Wide Area RDMA Protocol(iWARP)。三种协议都符合RDMA标准。
DMA需要硬件的支持,所以成本比较贵
IB
需要硬件、协议、软件的全套支持,现在IB已经达到了全双工惊人的400Gb/s
这玩意就更贵了,除了网关外,交换机也需要配套
RoCE
RoCE从英文全称就可以看出它是基于以太网链路层的协议,v1版本网络层仍然使用了IB规范,而v2使用了UDP+IP作为网络层,使得数据包也可以被路由
某种程度上可以做为IB的低成本替代方案,不过性能肯定是不及IB的
MPI
mpi做为老牌的消息通信接口,多用于HPC或者超算的并发编程领域, 作者所在的平台中也使用到了基于mpi实现的mpich2库.
MPI工作大多在CPU端,如果想作用于GPU,则会有些损耗(MPI传递GPU中的数据是有一个步骤是从Device拷贝数据到Host的内存), 所以对GPU来说(切确来说是nvidia gpu),则不得不说nccl
####NCCL
Nvidia于2015年公开发布NCCL,一个开源的、基于自身硬件的开源的集合通信库实现。其算法基本实现原理,和mpi的实现是基本类似的,由于其完全基于自家硬件,可以进行充分的优化,所以基于nvidia-gpu时,使用nccl性能是很强的,目前nccl是v2版本
NCCL 最初只支持单机多 GPU 通信,从 NCCL2 开始支持多机多 GPU 通信
以nvidia v100 gpu为例,来看看v100的Hardware Architecture
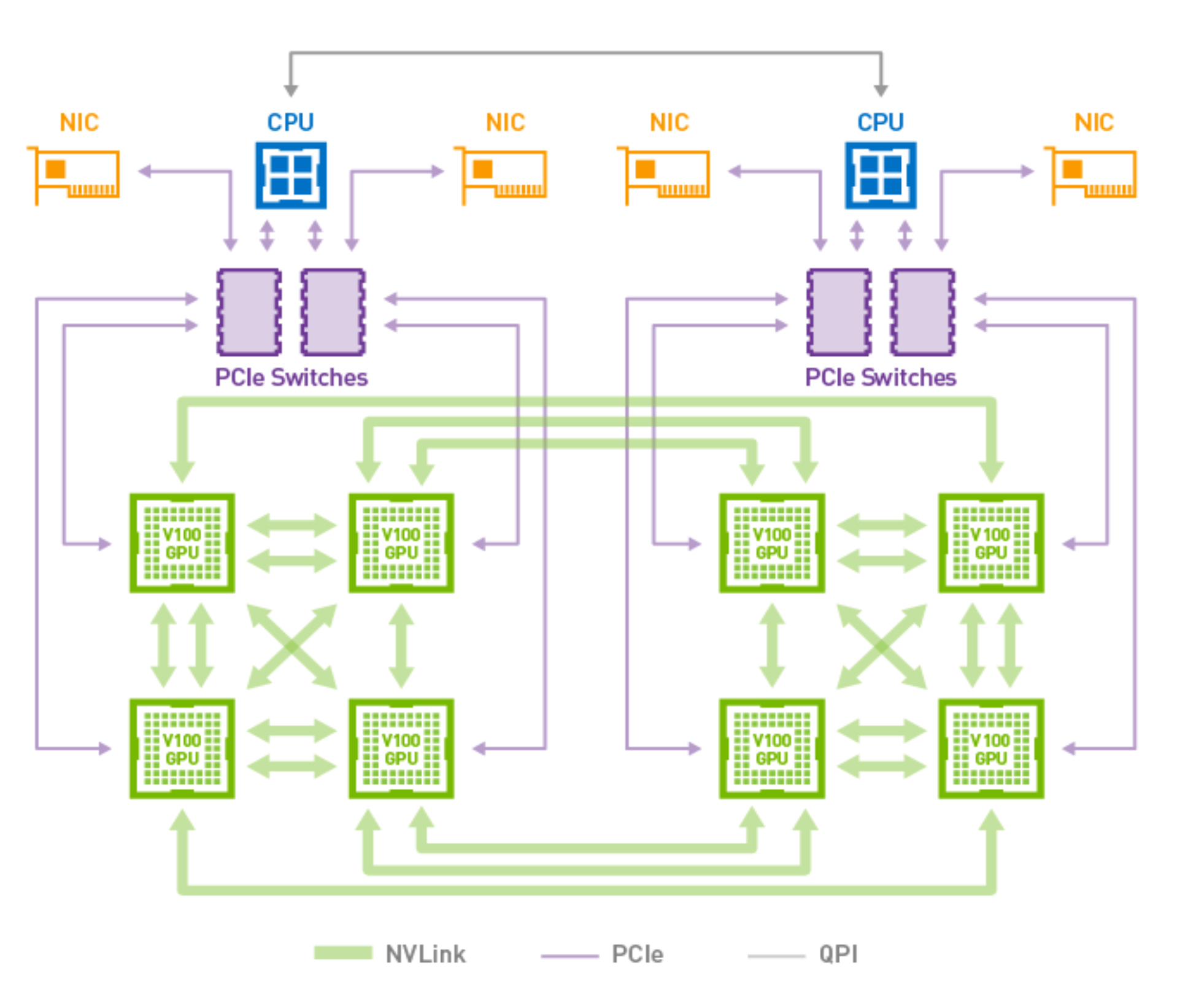
图中不同的连线代表不同的通信方式,有3种通信方式: nvlink、PCIE、QPI
nvlink
nvlink是nvidia出品的高速 GPU 互连技术, 目前已经更新至nvlink v3(A100上就是),v100是 nvlink v2
由于nvlink是全双工的通道,单向通道带宽为25Gb/s,双向则为50Gb/s,6个的话最大300Gb/s
这里要注意, 一块GPU上的nvlink通道是有限的,v100上最大是6通道,所以从图上可以看到,GPU与GPU之间的通道是nvlink, 但是只有6通道,所以没办法实现一块GPU跟其它的GPU都建立nvlink通道,所以没办法建立nvlink的两块gpu只得通过PCIE来进行通信了
PCIE
PCIE(PCI-Express),实质上是一种高速串行计算机扩展总线标准, 最新为PCIE v5版本,GPU上用的最多的还是PCIE v4
PCIE v4版本的速度大概在16Gb/s,而且还得看PCIE的插槽数量
所以可看出,如果GPU与GPU之间通过PCIE通道,则会比nvlink v2差很多.
同样,要注意PCIE v4直连CPU最大只能有16条
QPI
Intel的QuickPath Interconnect技术缩写为QPI,译为快速通道互联,也是全双工的
每个QPI总线总带宽=每秒传输次数(即QPI频率)×每次传输的有效数据(即16bit/8=2Byte)×双向
即QPI频率为4.8GT/s的总带宽=4.8GT/s×2Byte×2=19.2GB/s,QPI频率为6.4GT/s的总带宽=6.4GT/s×2Byte×2=25.6GB/s
另外说一下,nvidia v100的GPU与cpu也可以通过nvlink实现通信
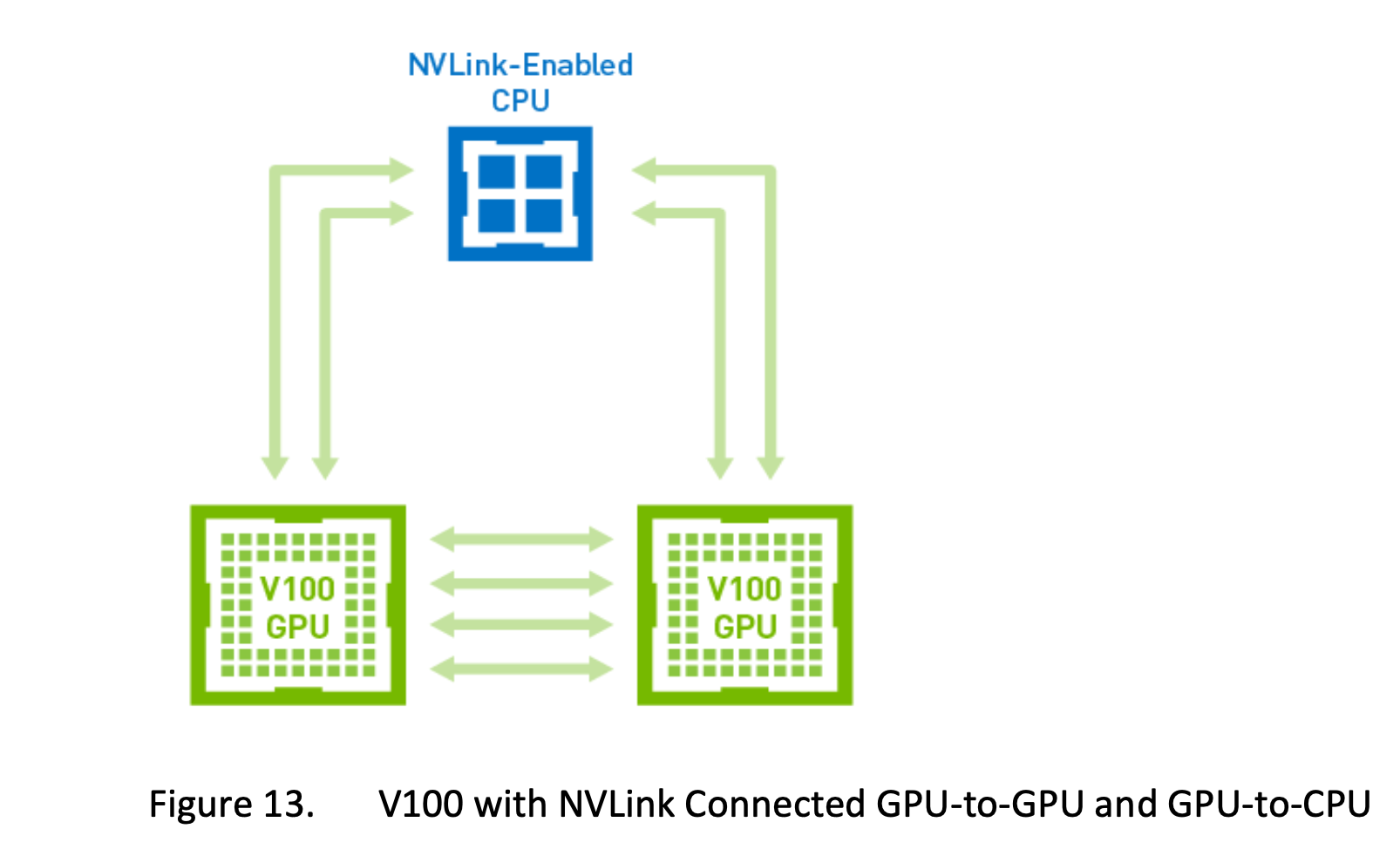
所以,这就是为什么很多大厂在GPU调度时要做GPU的拓扑感知的原因, 也是为了让GPU之间的路径更短, 不同的通道不同速度
最后,来说说在nvidia gpu的场景下,怎么知道走的是哪个方案呢, 使用以下命令
1 | $ nvidia-smi topo -m |
可以看到,上述服务器上有4块GPU卡,48个CPU核。
GPU0和GPU1之间是通过PCIe switch通信的(不经过cpu);
GPU2和GPU3之间也是通过PCIe switch通信的;
其它的GPU卡两两之间是通过QPI通信的(PCIe + QPI总线);
而mlx5_0 和mlx5_1是Mellanox ConnectX-4 PCIe网卡设备(10/25/40/50千兆以太网适配器,另外该公司是IBA芯片的主要厂商)。
当然,就算只说通信方向也还有很多的方法可以加速训练过程. 就CPU来说,外设也有远近之分,NUMA技术就是解决这个问题之一
百度飞桨的深度学习分布式训练专题非常不错,值得看看.
参考文章:
- https://izsk.me/2022/04/20/MPI-Structure/
- https://mpitutorial.com/tutorials/mpi-introduction/zh_cn/
- https://developer.aliyun.com/article/11181
- https://zhuanlan.zhihu.com/p/33714726
- https://zhuanlan.zhihu.com/p/453295832
- https://zhuanlan.zhihu.com/p/367327698
- https://blog.51cto.com/u_15642578/5316839
- https://zhuanlan.zhihu.com/p/367327698
- https://link.zhihu.com/?target=https%3A//www.mellanox.com/
- https://cloud.tencent.com/developer/article/1771431
- https://mp.weixin.qq.com/s/UqSydz8hJCFcX5CF30gXSw
- https://product.pconline.com.cn/itbk/diy/cpu/1111/2572054.html
- https://max.book118.com/html/2019/0609/8101047056002027.shtm