MPI框架学习一(架构组件)
Mpi: Message Passing Interface,消息传递接口
由于AI业务中使用到了MPI, 网上看MPI教程写的也是云里雾里,很难理解清楚,作者这里结合自身负责的业务来理解MPI的实现方式.
如果有理解存在有遗留或者错误的地方,请各位过客不吝赐教.
在AI多机多卡训练通信过程中,各节点之间需要进行数据交换,集群中大量的数据交换是很耗费时间的,因此需要一种在跨节点的情况下能快速进行数据交流的通道,MPI就是一种很常用的通信框架,在HPC中使用也较广.
MPI是一组用于多节点数据通信的标准,而非一种语言或者接口。MPI虽然很庞大 但是它的最终目的是服务于进程间通信这一目标的, 不同的实现,使用方法有所不同,如mpich or openmpi等。
mpirun vs mpiexec
mpirun与mpiexec在MPI中都可以叫做为launcher(启动器), 是比较通用的起名或者是别名的符号链接(symbolic link),实现可能会所不同,比如OpenMPI ,它自己的进程启动器称为 orterun .为了兼容性,orterun也被符号链接(symbolic link)为 mpirun和 mpiexec
hydra vs mpd
hydra与mpd同为进程管理器,mpd在mpich2-1.3+版本中被废弃,取而代之的是hydra,hydra是一种比较轻量的PM(相对于mpd),利用ssh、rsh、pbs、slurm和sge等调度工具部署运行并行程序
MPICH2是由Argonne国家实验室维护的开源MPI库,是高性能计算领域使用最为广泛的MPI库之一,作者所有的小组内也是以mpich2为公共组件,因此以下的case都以mpich2为例.
MPI的编程方式,是“一处代码,多处执行”。编写过多线程的人应该能够理解,就是同样的代码,不同的进程执行不同的路径
以下是Hydra Process Management Framework官方的架构图:
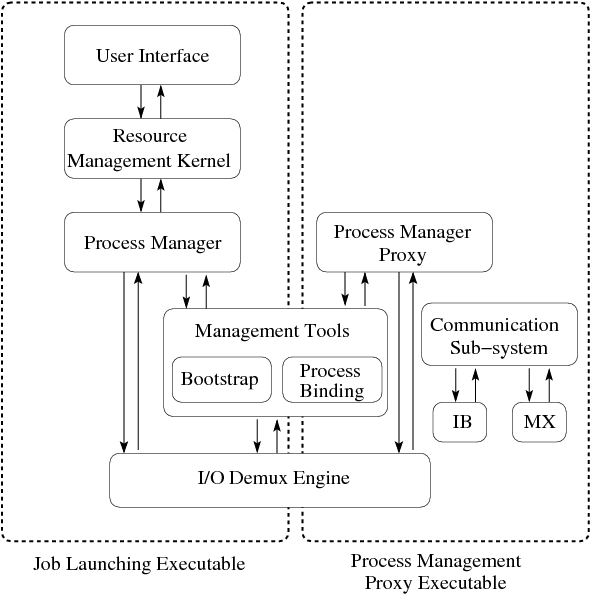
Hydra framework由以下几个基本部分组成:
- User Interface,用户接口UI
- Resource Managerment Kernel,资源管理核心RMK
- Process manager,进程管理PM
- Bootstrap,启动服务的方式,如ssh,fork,pbs,slurm,sge
- Process Binding,进程监听,如plpa
- Commnication Subsystem,例如IB,MX
- Process Managerment proxy,进程管理代理
- I/O demux engine ,IO复用引擎
从这个图也很容易看出:
JLE一般运行在称之为管理节点上(当然在计算节点也是ok的),用于接收指令然后将任务下发
计算节点则一般是跑具体任务的,而ManagermentTools则是在管理节点与计算节点间的桥梁
下面详细来解释一下上面的组件, 机器翻译自[wiki][https://wiki.mpich.org/mpich/index.php/Hydra_Process_Management_Framework]:wiki的文字时间有点早了,但整体不受影响,机翻出来还行.
User interface
此层的主要职责是从用户那里收集有关应用程序的信息: 在何处启动进程;将进程映射到内核;读取 标准输入(stdin) 并将其转发到适当的进程 (es); 从不同的程序中读取标准输出/标准错误并合适地指导。mpich2中的mpiexec.hydra就是个userinterface程序
Resource Mangerment Kernel(RMK)
RMK 提供了可与资源管理器进行交互的插件功能,比如Torque,Moab或者Cobalt。例如, 如果应用程序在启动作业之前需要在系统上分配节点, RMK 将完成这部分。同样, RMK 还可以允许在单个系统预留用于多个作业的情况下解耦作业启动。在当前的实现中, RMK 非常简单, 不提供任何这些功能
Process Manager(PM)
进程管理器提供了必要的环境设置以及主要的进程管理功能,例如进程管理器pmiserv进程管理器提供了MPICH PMI(PMI)功能。但目前仅支持PMI1,但我们也计划添加 PMI-2(目前正在起草中)。其他进程管理器也可以通过其他接口支持。Process Managerment Proxy(PMP)
进程管理代理基本上是一个帮助器代理, 它是在系统的每个节点上生成的, 以帮助进程管理器进行进程生成、进程清理、信号转发、I/O转发以及任何进程管理器特定的功能。
它基本上可以执行进程管理器可以做的任何任务, 因此, 甚至可以创建进程管理代理的层次结构, 其中每个代理都充当其子树的进程管理器。mpich2的hydra_pmi_proxy就是个PMP
Bootstrap
引导服务器主要充当预配置的守护进程系统, 允许上一层服务在整个系统中启动进程,目前运行多种方式。
例如, ssh 引导服务器fork进程, 每一个都通过执行一个 ssh 到另外一台机器,启动一个进程。Processing Binding进程监听组件主要处理提取系统体系结构信息 (例如, 处理器的数量、可用的内核和 SMT 线程、它们的拓扑、共享缓存等), 以及将进程绑定到可移植的不同内核中用一种简便的方式。PLPA 是一个这样的体系结构, 已经在Hydra中使用, 但它只提供有限的信息。Communication Subsystem
通信子系统是不同代理之间以可伸缩方式进行通信的一种方式。这仅与下面描述的预启动和预连接代理有关。
此组件提供可伸缩的通信机制, 而与系统的规模无关 (例如, 基于IB或MX)。I/O Demux Engine
这基本上是一个便利组件,不同的组件可以“注册”它们的文件描述符,并且 demux 引擎可以等待这些描述符中的任何一个上的事件。这提供了一个集中的事件管理机制;所以我们不需要让不同的线程阻塞不同的事件。I/O 解复用引擎使用同步回调机制。也就是说,对于每个文件描述符,调用进程都会提供一个函数指针,指向在描述符上发生事件时必须调用的函数。demux 引擎阻塞所有已注册文件描述符上的事件,并在有事件时调用适当的回调。该组件在实现中非常有用,但在架构本身中并不起关键作用
这里RMK、PB、I/O Demux Engine都比较复杂,可以不用关心是什么.
PM跟PMP从名字上来看也比较容易理解,PMP可以理解为是PM在每个计算节点上负责管理的代理人角色
另外要重点说一下Bootstrap,确切来说是Bootstrap Server
大多数场景下远程启动进程都是使用默认的ssh launcher,意思是mpiexec.hydra通过ssh的方式登录计算节点来启动mpi_proxy程序,但是在ssh的过程中是不能有输入密码操作的,因此需要事先配置好ssh免密
比如最简单的程度
1 | # user interface端 |
如果没有指定-launcher(有些实现可能是-bootstrap),则使用默认值ssh
新版本(好像是在2.1之后)的mpiexec.hydra支持launcher manual, 即mpi_proxy的启动可通过人工的方式,这在docker场景下比较有用,在用docker做为计算节点时可以不用配置ssh免密,在启动docker时通过entrypoint直接启动mpi_proxy,这个时候就需要指定launcher为manual了.
1 | # user interface端 |
这样就需要两端自行启动相关进程了.
关于mpi的架构这块,能理清楚那几个组件的作用就可以了.
上面的命令行支持非常多的参数,本身也没有什么说明性,至于对应在计算节点上的proxy启动命令为什么是那样的、节点与节点间是如何通信的等问题。
都值得再更.
参考文章:
- https://zhuanlan.zhihu.com/p/69497154
- https://www.cxyzjd.com/article/wgbljl/24038539
- https://blog.csdn.net/wgbljl/article/details/24038539
- http://cali2.unilim.fr/intel-mpi/doc/Reference_Manual.pdf
- https://wiki.mpich.org/mpich/index.php/Developer_Documentations
- https://wiki.mpich.org/mpich/index.php/Hydra_Process_Management_Framework