pod的状态出现UnexpectedAdmissionError是什么鬼?
今天在排查集群一个问题时,发现相关的pod的状态为UnexpectedAdmissionError,在这之前从未没遇到过pod还有这种状态的,一脸好奇,在解决问题的过程中,发现越挖越深, 里面涉及到的信息也是相当的多,特此记录一下.
集群信息
k8s版本为K8s v1.15.5, 3 master + N node的形式,由于业务特殊,集群中同时存在的node有amd64及arm64两种异构节点,但这些都不重要,重要的一点是,集群中同时存在2种scheduler:
default scheduler: 这个不用多说,k8s默认的调度器,本质上来说,是个串行的调度器x-scheduler: 自定义调度器, 用于批量去调度资源,如果有任一请求的资源不满足,其它的资源也不会调度,pod处于一直Pending状态,直到资源都满足- 在不同的业务中会使用不现的调度器,以实现资源的合理分配,记住,集群中有两个调度器, 这个是本次问题的关键
同时还要说明一点的是,这次引起问题的资源是nvidia.com/gpu,涉及到kubelet对于device是如何管理的,这部分是本次的重点内容
下述出现的资源,device,其实是一个意思,资源可能在日常中使用的较多,而官方都把资源比较是一种device
慢慢道来…
问题现象
问题现象就是工作流(这里不展开细说,简单理解就是运行完就销毁的pod吧)的pod出现了如下图的状态

在作者多年丰富的工作(自吹)经验中,pod的状态从未出现UnexpectedAdmissionError这种状态,甚至作者都不知道除了常见的那几种状态外还有其它的状态,看到这作者还是有点高兴的,因为作者知道,嗯,应该会挖出个盲区
另外,工作流控制器返回的信息为:
Pod Update plugin resources failed due to requested number of devices unavailable for nvidia.com/gpu. Requested: 1, Available: 0, which is unexpected
该报错在kubelet的日志中也有出现
另外,经过作者的多次尝试,发现上述问题并不总是存在,也有成功的时候
排查过程
看到上述的报错message,翻译一下:
pod更新Plugin资源失败, 失败的原因是由于请求的nvidia.com/gpu资源需要1个,但现在只有0个
报错意思很明显,但作者第一时间想到的是以下3个问题:
- 正常来讲不会出现因为资源不够而调度的情况,如果资源不够,是不应该被调度的,但从上面的报错来看,已经过了调度那个环节,因为已经配置到了
node上 - 如果忽略问题1,就算是资源不够,也应该是
Pending状态,而不应该是UnexpectedAdmissionError这种状态 pod去更新plugin的什么资源,为什么需要更新?
问题1跟问题2应该是同一个问题,就放一起排查吧
作者的猜测: 由于集群中同时存在2种调度器,对于同一device(比如nvidia.com/gpu)就可能会发生竞争关系,比如以下场景:
某一node上nvidia.com/gpu资源只有1个
Pod1,使用了default-scheduler,消耗了nvidia.com/gpu=1,此时,nvidia.com/gpu为0
Pod2,使用了default-scheduler,请求了nvidia.com/gpu=1,状态Pending
Pod3,使用了x-scheduler,请求了nvidia.com/gpu=1,状态Pending
在特定的场景下,存在pod2,pod3都调度到这个node上的可能,那么在pod1执行完成之后,就有可能出现default-scheduler与x-scheduler同时拿到nvidia.com/gpu=1,对Pod2及Pod3从Pending状态唤醒,但是在接下来的某一时候,只会有一个Pod创建成功,另一个Pod就有可能会出现UnexpectedAdmissionError
如果这样的Pod越多的话,发生的可能性就越大
因为是race,所以也不一定总是会发生,这也解释了【问题现】中提到的问题并不总是存在的问题
从后续的排查情况来看,也证实了上述猜想,开发侧对调度器引用不当,对于nvidia.com/gpu的资源,应该使用x-scheduler,但有些被调整成了default-scheduler也就是说,如果上面的场景,所有请求同一资源的pod,使用相同的scheduler那么就不会出现这种问题,因为相同的scheduler内部的加锁机制是相同的.
解决也很简单,对同一资源的请求,schedulerName设成一致即可
问题虽然解决,但依然没有解决很多疑惑,比如:
UnexpectedAdmissionError状态怎么来的- pod去更新plugin的什么资源,什么时候更新等?
没办法,只能去查源码了
源码分析
首先,从kubelet中看到了相关的报错信息,那么就从kubelet开始吧, 由于环境中的kubelet的日志级别不高,先调整成--v 4,代表debug日志,发现以下日志:
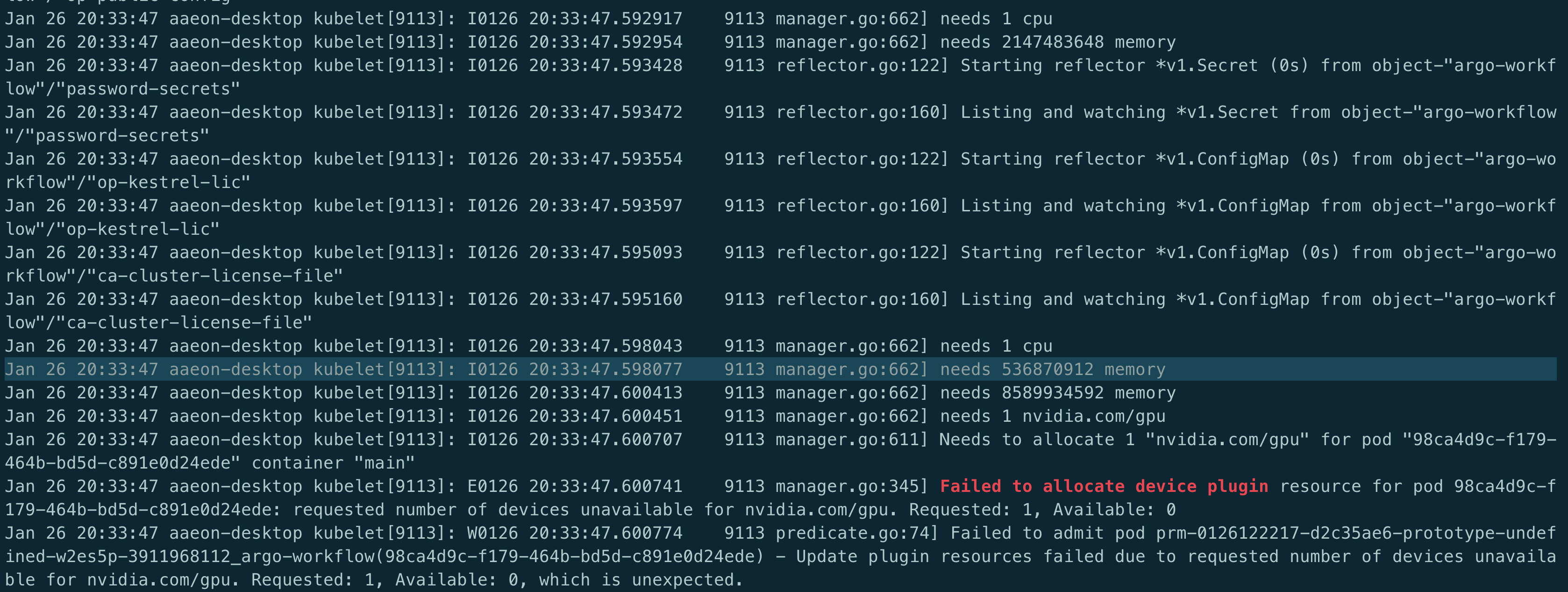
结合kubelet侧关于cm(containermanager的缩写)代码,大体的调用过程: scheduler(predicate.go) --> kubelet(predicate.go) --> manager.go
predictate.go中也确认存在UnexpectedAdmissionError
1 | func (w *predicateAdmitHandler) Admit(attrs *PodAdmitAttributes) PodAdmitResult { |
跟上面kubelet中打印出来的日志是吻合的,经过摸排发现,调用路径主要集中在manager.go如下:
1 | Allocate --> allocatePodResources --> allocateContainerResources --> devicesToAllocate |
最终在devicesToAllocate中报出requested number of devices unavailable for 的错误一直按上述路径返向传回给Allocate,也就是上图中红色的部分
同时又可以知道,predictate一般属于调度相关,因此,应该是从scheduler传过来的, 从Allocate函数定义就可以看出
1 | func (m *ManagerImpl) Allocate(node *schedulernodeinfo.NodeInfo, attrs *lifecycle.PodAdmitAttributes) |
再根据node *schedulernodeinfo.NodeInfo就可一层层追到scheduler的代码中,由于篇幅原因,就不在这里贴了
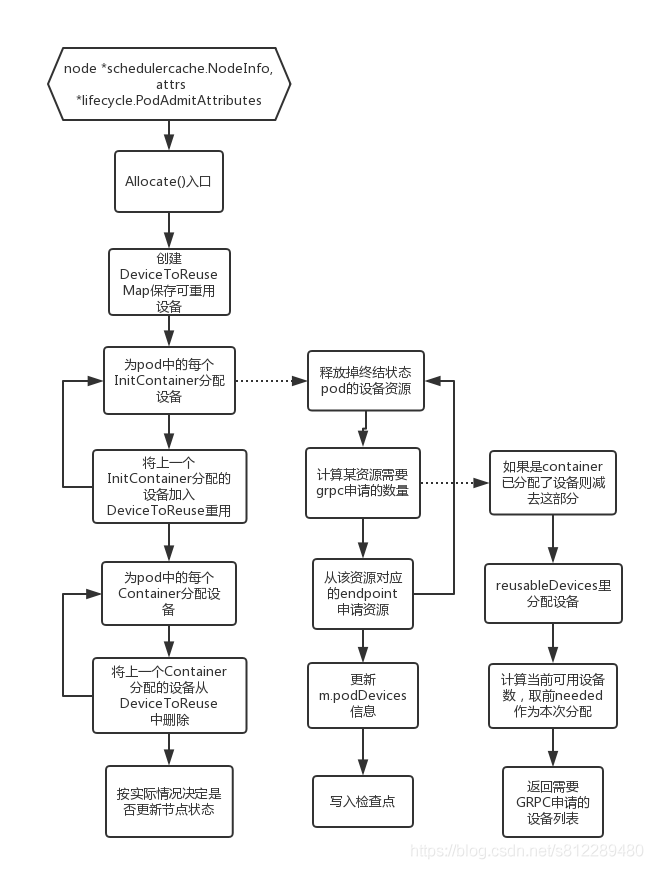
Allocate()方法作用是根据scheduler传来的条件为某pod分配device,而device则是根据resource.limit做为条件进行计算
1 | func (m *ManagerImpl) allocateContainerResources(pod *v1.Pod, container *v1.Container, devicesToReuse map[string]sets.String) error { |
这里面有个有意思的对象:deviceToReuse,可重用的设备, Allocate调了的allocatePodResources
1 | func (m *ManagerImpl) allocatePodResources(pod *v1.Pod) error { |
原因是k8s中有initContainer,initContainer可以有多个,先于container执行,每个initContainer按顺序依次执行完毕后container才会开始创建,而在为container或initContainer分配设备的时候会优先利用deviceToReuse的设备,这样可避免资源浪费
还有一些比较重要的功能,比如:
updateAllocatedDevices函数的功能是从podDevices中删除所有处于终结状态的pod,并回收其占用的资源,所以有时会在kubelet的日志中看到pods to be removed:xxxx字样
devicesToAllocate用来生成需要向plugin请求的设备列表,如果可重用设备已经够用或者没有设备需求时则不向plugin请求分配新的设备,否则调用grpc向plugin申请分配新的设备。
设备分配的逻辑是首先看container中是否已经分配了设备,如果设备够用则返回nil,否则查看reusableDevices,取出里面的设备分配,否则根据最终缺少的设备量返回healthdevice - inusedevice(m.allocatedDevices[resource]),中的前needed个,这便是其分配设备的策略
1 | func (m *ManagerImpl) devicesToAllocate(podUID, contName, resource string, required int, reusableDevices sets.String) (sets.String, error) { |
因此,报错的最终原因也是在这里,因为pod此时已经分配到了node上,但node上的可用device小于pod申请的device,导致在启动container时predicate.go报错返回
device的predicate过程会执行二次,第一次是对scheduler对node进行筛选的时候,第二次kubelet在container启动之前会再次进行device的确认,而上述报错则是出现在kubelet
最后除一张牛人的manager.go中代码调用图吧,非常清晰,原图地址在这里
到这里,其实第2个问题还是没有讲的很清楚,即kubelet怎么去管理devie-plugin资源,device-plugin注册、跟api-server同步等
这个主要涉及到kubelet是如何管理device的,即device-plugin是实现原理,做为下次作业吧
参考文章:
- http://www.dockone.io/article/8653
- https://www.kubernetes.org.cn/4391.html
- https://www.cnblogs.com/oolo/p/11672720.html#dm-%E8%B0%83%E7%94%A8-dp-listandwatch-%E7%9A%84%E6%97%B6%E6%9C%BA
- https://github.com/kubernetes/kubernetes/issues/60176
- https://blog.csdn.net/s812289480/article/details/84314239
- https://zwforrest.github.io/post/devicemanager%E5%8E%9F%E7%90%86%E5%8F%8A%E5%88%86%E6%9E%90/#allocate%E5%88%86%E9%85%8D%E8%B5%84%E6%BA%90
- https://github.com/kubernetes-sigs/kube-batch/issues/931
- https://sourcegraph.com/github.com/kubernetes/kubernetes/-/blob/pkg/kubelet/lifecycle/predicate.go
- https://github.com/kubernetes/kubernetes/blob/v1.15.9/pkg/kubelet/cm/devicemanager/manager.go