Opentelemetry调研实践三(全链路追踪的TraceID与SpanID)
历史文章:
在opentelemetry架构及名词介绍 中就引出了一个问题: 无论在数据平面如何做流量劫持,如何透传信息,以及如何生成或者继承Span,入口流量和出口流量之间的链路都存在无法串联的问题, 这个问题要解决还是需服务来埋点透传,将链路信息透传到下一次请求当中去
一个最简单的golang的例子
Main of ServiceA – > FuncionA of ServiceA – > FunctionB of ServiceA – > Main of ServiceB
调用从主函数Main of ServiceA(入口流量)到调用Main of ServiceB(出口流量)的中间的这段调用,对于大多数的APM都无法捕捉得到,原因是APM不能理解业务逻辑,现在大热的Istio也做不到,它本质上还是通过劫持入口及出口流量,对于方法级的调用也无法实现追踪(这里不考虑java使用字节码技术实现),如果想知道这层调用关系,则需要:
- 生成一个ID1: 使用该ID可以将所有经过的节点串连起来,按时间排序就是timeline
- 生成一个ID2:可以通过该ID体现父子关系,串起来就是调用栈
这在分布式链路跟踪中刚好对应两个重要的概念:跟踪(trace)和 跨度( span)
trace 是请求在分布式系统中的整个链路视图,span 则代表整个链路中不同服务内部的视图(有向无环图,DAG)
一个span代表系统中具有开始时间和执行时长的逻辑运行单元, 所有span 组合在一起就是整个 trace 的视图
这就是Trace要解决的问题, 对于ID1,一般称之为TraceID, 对于ID2,一般称之为Span
TraceID
这个很好理解,如果要标记一次请求经过的所有路径,那么给这条请求经过的所有节点都使用同一个标记即可,那么反过来,通过这个标志即可得到这条请求经过的所有节点。
所以一般情况下,都会在网关处给每次请求都生成一个全局唯一的ID做为TraceID,将该TraceID放在Header中向后传递下去,后面的服务都使用该ID
SpanID
很多人不理解为什么需要SpanID?
既然有了TraceID,如果再加上节点的被调用的时间,是不是也可以还原出整个请求的调用链路视图呢?
答案是可行的,但是使用调用时间远不如SpanID方便。
当请求到达每个服务后,服务都会为请求生成spanid,第一个spanid称之为root span,而随请求一起从上游传过来的上游服务的 spanid 会被记录成parent-spanid或者叫 pspanid。当前服务生成的 spanid 随着请求一起再传到下游服务时,这个spanid 又会被下游服务当做 pspanid 记录
所以,SpanID本身就已经形成了父子关系,而使用调用时间的话,还需要进行时间戳的比对,这在一定量级的场景下对性能是个考验。
1 | type Span struct { |
调用链
先来看一张经典图:
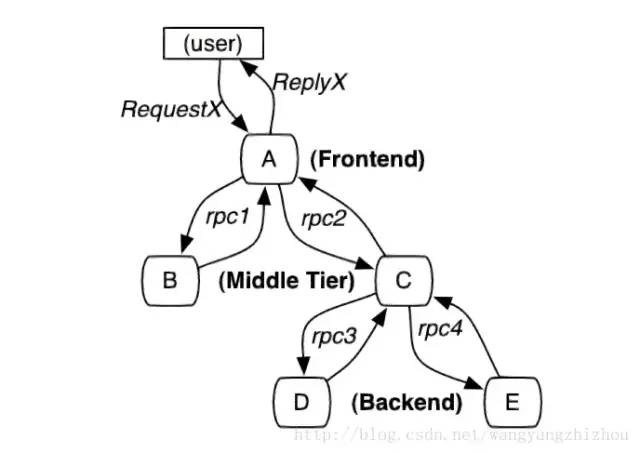
当用户发起一个请求时,首先到达前端A服务,然后分别对B服务和C服务进行RPC调用;B服务处理完给A做出响应,但是C服务还需要和后端的D服务和E服务交互之后再返还给A服务,最后由A服务来响应用户的请求
整个调用过程追踪
请求到来生成一个全局TraceID,通过TraceID可以串联起整个调用链,一个TraceID代表一次请求。
除了TraceID外,还需要SpanID用于记录调用父子关系。每个服务会记录下parent id和span id,通过他们可以组织一次完整调用链的父子关系。
一个没有parent id的span成为root span,可以看成调用链入口。
所有这些ID可用全局唯一的64位整数表示;
整个调用过程中每个请求都要透传TraceID和SpanID。
每个服务将该次请求附带的TraceID和附带的SpanID作为parent id记录下,并且将自己生成的SpanID也记录下。
要查看某次完整的调用则 只要根据TraceID查出所有调用记录,然后通过parent id和span id组织起整个调用父子关系。
调用链核心工作
- 调用链数据生成,对整个调用过程的所有应用进行埋点并输出日志。
- 调用链数据采集,对各个应用中的日志数据进行采集。
- 调用链数据存储及查询,对采集到的数据进行存储,由于日志数据量一般都很大,不仅要能对其存储,还需要能提供快速查询。
- 指标运算、存储及查询,对采集到的日志数据进行各种指标运算,将运算结果保存起来。
- 告警功能,提供各种阀值警告功能。
目前大部分的全链路追踪实现都是基于Google的Dapper实现
下面介绍几种可做为ID的方案.
nginx生成TraceID
nginx为每一条请求都生成一个唯一的ID,这个ID由nginx本身保证了唯一性,天然是个做为TraceID的好方案,只需要在nginx的配置中开启以下参数即可
1 | upstream app_server { |
参考application-tracing-nginx-plus
后端代码可直接从http header中获取相应的X-Request-ID的值做为ctx传递即可
kong生成TraceID
kong做为ingress controller的场景下,可通过correlation-id插件来生成uuid做为traceID
可以定义全局使用(全局的plugins不需要手工在ingress中进行绑定)
1 | apiVersion: configuration.konghq.com/v1 |
header_name指定header名字
generator指定使用uuid生产ID
echo_downstream指定将header返回给调用方
如果不是全局的,可在ingress中进行绑定
1 | apiVersion: extensions/v1beta1 |
对于已经存在相同名字的header,correlation-id会进行忽略,不进行任何操作
opentelemetry生成TraceID
1 | // IDGenerator allows custom generators for TraceID and SpanID. |
上述是opentelemetry默认生成TraceID跟SpanID的方法,同时,opentelemetry支持使用自定义算法去生成,只需要生写上述的NewIDs及NewSpanID即可,比如:
1 | // 自定义ID生成规则 |