Kube-batch学习(nodeorder插件使用)
AI场景跟大多数的业务不太一样的是: 网络端需要尽可能地靠近,对于大多数业务来说,为了保证其可用性,一般副本都会分散地部署在不同node,而AI业务通常伴随着海量的数据交换,一个job中的多个pod需要协同处理,如果分散在多个node上,task间的任务交换的快慢就得依赖于网络的传输的快慢,而如果是在一台node上的话,那就没有这部分的消耗,一个job中的pods如何做到尽可能地调度在同一台机器上呢, kube-batch除了能够支持poggroup外,也是能够支持的podaffinit的.
一个job中的pods如何做到尽可能地调度在同一台机器上呢, 最容易让人想到的是podAffinit,podAffinit是针对于在集群中已经存在的pod,其它的pod可以通过podAffinit来让他们部署在一起,这里有个很大的问题在于, 如果同时使用了podgroup,也就是说在podgroup中的pod在绑定节点之前在集群中是不存在的,也就是办法通过labelsector找到这些pod,那要怎么办呢?
为解决这个问题,kube-batch进行了详细的issue讨论,为此,kube-batch引入了一个全新的plugins, 最开始叫Prioritize,后改名为nodeorder.
假使kube-batch使用以下的配置:
1 | actions: "allocate, backfill" |
之前提到过,actions指定了kube-batch在调度时需要执行的操作,同时,这些操作会关联一些plugins(简单来说就是一些算法)来实现相关功能,比如说,actions是allocate,allocate意为分配资源,但是在分配资源时有时也会有一些要求,比如优先级高的先分配,或者把某个任务当成一个整体进行分配(gang)等等,同时,不同的actions可能关联同一个plugins,比如对于资源回收时,也可能存在先回收优先级低的pod的资源,这就是actions及plugins之间的关系
这里将nodeorder放在靠前的位置,同时启用gang插件.
nodeorder的流程如下:
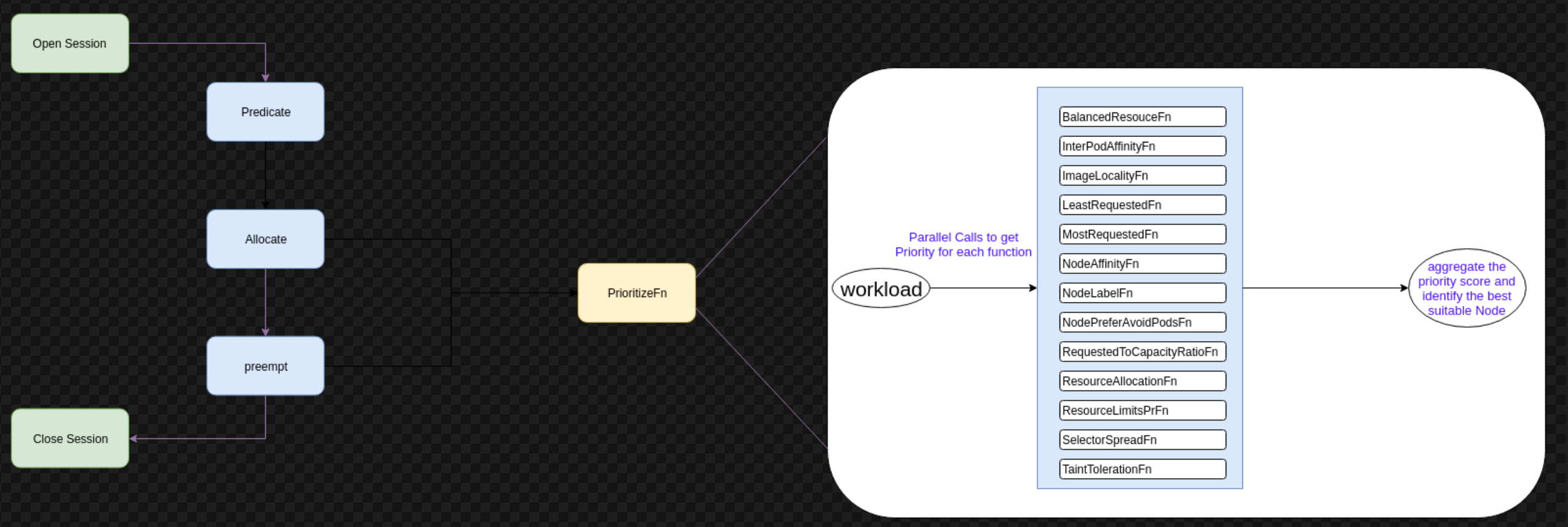
从图中可看出Prioritize只发生在Allocate及Preempt actions中, 上面的配置中只启用了Allocate,当kube-batch从所有机器中筛选出所有符合条件的node列表后,在Allocate中开始执行Prioritize的function,详细流程:
- 并行地在筛选出来的node列表中执行所有的priority functions
- 根据优先级规则是否满足工作负载调度标准对节点进行评分
- 一旦从所有优先级返回分数,则聚合分数并确定得分最高的节点
- 将最后一步中选定的节点委托给AllocateFn,以将工作负载绑定到该节点
从上图中可以看出priority functions包含interpodAffinityFn,从这个命名来看是跟podAffinity有关的,假如我的job定义了这样的podAffinity
1 | affinity: |
使用了preferredDuringSchedulingIgnoredDuringExecution,尽可能地调度到一台节点上,确实是interpodAffinityFn起了作用
Talk is cheap, show me the code
主要的逻辑代码位于kube-batch/vendor/k8s.io/kubernetes/pkg/scheduler/algorithm/priorities/interpod_affinity.go
1 | processNode := func(i int) { |
其中
pod 一个需被调度的Pod
hasAffinityConstraints “被调度的pod”是否有定义亲和配置
hasAntiAffinityConstraints “被调度的pod”是否有定义亲和配置
existingPod 一个待处理的亲和目标pod
existingPodNode 运行此“亲和目标pod”的节点–“目标Node
existingHasAffinityConstraints “亲和目标pod”是否存在亲和约束
existingHasAntiAffinityConstraints “亲和目标pod”是否存在反亲和约束
上面调用的processPod,传入的是一个existingPod,
1 | processPod := func(existingPod *v1.Pod) error { |
第一次循环的时候通过亲和性规则显然是找不到pod的
1 | func (p *podAffinityPriorityMap) processTerm(term *v1.PodAffinityTerm, podDefiningAffinityTerm, podToCheck *v1.Pod, fixedNode *v1.Node, weight float64) { |
但是第二次循环的时候就能发现第1个pod了,在整个循环期间需要计算weight值,最后得分最高的node为最终选中的node
更加详细的代码详解可参考: https://www.jianshu.com/p/a931ad4f0242