Kube-batch学习(核心模块)
接上篇,主要介绍了kube-batch中两个重要的对象,queue及podgroup,这次主要讲讲kube-batch的核心的几个模块
默认配置
以下是kube-batch默认的配置,如下:
1 | actions: "allocate, backfill" |
可以看到分为actions及tiers,其中actions指定了kube-batch在调度时需要执行的操作,同时,这些操作会关联一些plugins(简单来说就是一些算法)来实现相关功能,比如说,actions是allocate,allocate意为分配资源,但是在分配资源时有时也会有一些要求,比如优先级高的先分配,或者把某个任务当成一个整体进行分配(gang)等等,同时,不同的actions可能关联同一个plugins,比如对于资源回收时,也可能存在先回收优先级低的pod的资源,这就是actions及plugins之间的关系
kube-batch支持多种的actions及plugins,这个则需要根据实际的情况按需选择
列表如下:
- actions
- allocate
- backfill
- preempt
- reclaim
- plugins
- conformance
- drf
- gang
- nodeorder
- predicates
- priority
- proportion
要注意的是,配置文件中actions及plugins的指定顺序非常重要,kube-batch不会考虑action及plugins列表之间的顺序是不是合理,它只会按照指定的顺序依次执行,因此,要根据实际情况谨慎、实操地对配置进行优化,最后才能达到合理效果
tiers下的plugins是列表结构,对于actions来说,如果遇到了优先级更高的plugins,则不会再进行应用低优先级的plugins,比如上面的配置中,如果一个优先级高的跟一个优先级低的任务同时到来,则优先级高的获取到它需要的所有资源,而不会再考虑其它的plugins,如果两者优先级一样且都是以podgroup存在,则就会按drf plugins进行处理.
这张图很形象地说明kube-batch的工作原因
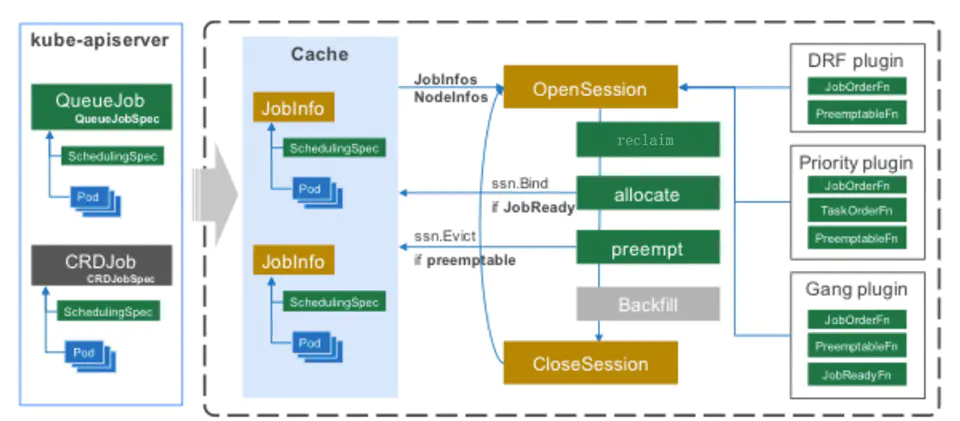
它通过 list-watch 监听 Pod, Queue, PodGroup 和 Node 等资源,在本地维护一份集群资源的全局缓存,依次通过如下的策略(reclaim, allocate, preemption,predict) 完成资源的调度
cache
Cache模块封装了对API Server的节点、容器等对象的数据同步逻辑。Kubernetes的数据保存在分布式存储etcd中,所有对数据的查询和操作都通过调用API Server的接口,而非直接操作etcd。在调度时,需要集群中的节点和容器的使用资源和状态等信息。Cache模块通过调用Kubernetes的SDK,通过watch机制监听集群中的节点、容器的状态变化,将信息同步到自己的数据结构中。
Cache模块还封装了对API server的接口的调用。比如Cache.Bind这个接口,会去调用API Server的Bind接口,将容器绑定到指定的节点上。在kube-batch中只有cache模块需要和API Server交互,其他模块只需要调用Cache模块的接口,一方面减少api-server的压力,另一方面加快kube-batch本身的调度性能
session
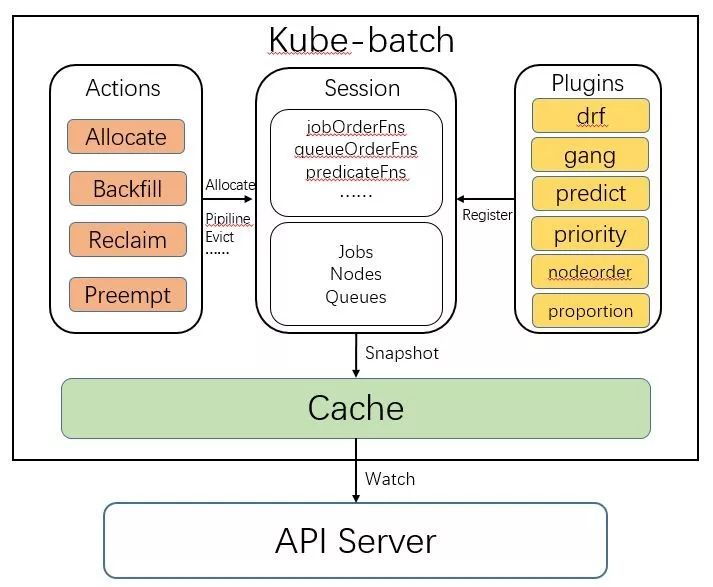
Session模块是将其他三个模块串联起来的一个模块。Kube-batch在每个调度周期开始时,都会新建一个Session对象,这个Session的初始化时,会做以下操作:
- 调用Cache.Snapshot接口,将Cache中节点、任务和队列的信息拷贝一份副本,之后在这个调度周期中使用这份副本进行调度。因为Cache的数据会不断变化,为了保持同个调度周期中的数据一致性,在一开始就拷贝了一份副本。
- 将配置中的各个Plugin初始化,然后调用plugin的OnSessionOpen接口。Plugin在OnSessionOpen中,会初始化自己需要的数据,并将一些回调函数注册到session中。Plugin可以向Session中注册的函数是:
- jobOrderFns: 决定哪个训练任务优先被处理(调度、回收、抢占)
- queueOrderFns:决定哪个训练队列优先被处理
- taskOrderFns:决定任务中哪个容器优先被处理
- predicateFns: 判断某个节点是否满足容器的基本调度要求。比如容器中指定的节点的标签
- nodeOrderFns: 当多个节点满足容器的调度要求时,优先选择哪个节点
- preemptableFns: 决定某个容器是否可以被抢占
- reclaimableFns :决定某个容器是否可以被回收
- overusedFns: 决定某个队列使用的资源是否超过限额,是的话不再调度对队列中的任务
- jobReadyFns:判断某个任务是否已经准备好,可以调用API Server的接口将任务的容器调度到节点
- jobPipelinedFns : 判断某个任务是否处于Pipelined状态
- jobValidFns: 判断某个任务是否有效
注意Plugin不需要注册上面所有的函数,而是可以根据自己的需要,注册某几个函数。比如Predict plugin就只注册了predicateFns这个函数到Session中。
初始化成功后,Kube-batch会依次调用不同的Action的Execute方法,并将Session对象作为参数传入。在Execute中,会调用Session的各种方法。这些方法,有些最终会调用到Cache的方法, 有些是调用Plugin注册的方法。
actions
因为业务中只使用到了默认的action,因此就简单说下allocate跟backfill这两个,其它的如reclaim跟preempt可参考这里
allocate
allocate用于将有明确资源需求的pod(task)分配到某个节点,在k8s对象中,pod或者container有没有指定request及limit,对应不同的Qos,Qos表示为服务质量,在这里不展开说明,感兴趣的可参考这里,对于明确指定了requests跟limit且相等的这类pod,对应的Qos为guaranteed,同等情况下会被优先保障资源。
如果不额外配置,allocate在kube-batch是默认的选项
那如果有pod没有指定资源怎么办呢?
backfill
这个时候就需要靠backfill(回填)这个action来处理了,这个模块主要实现当podgroup中有pod没有被绑定成功时,其它的绑定的pod的资源会释放,在podgroup中非常关键.
Plugins
gang
gang翻译成中文是帮派的意思,电影中的帮派大多都是共进退的,因为gang插件实现的就是帮派调度,gang-scheduler是podgroup中的核心,实现All or Nothing的效果
那么Kube-batch如何Gang-Scheduler,逻辑如下:
- 增加一个PodGruop的CRD。调度以PodGroup为单位。同时对应还有一个PodGroupController进行PodGroup的管理
- 整个调度过程采用延迟创建Pod的过程。只有当PodGroup中的所有Pod都有合适的Node绑定时,才开始创建
- c. 定义了一种新的Action-BackFill.当PodGroup还有Pod没绑定时,之前绑定Pod的资源会释放
gang注册3个function,分别是:
preemptableFn为避免gang的策略被preempt和reclaim干扰,定义了preemptableFn,排除那些还未准备就绪的job,避免其被抢占。(虽然实际上这些job未真正调度到node上去,但是确实从逻辑上把资源分配给它了)jobOrderFn为让已经就绪的job尽快被调度到节点,定义了jobOrderFn ,让已经就绪的job拥有更高的优先级jobReadyFn用来判断一个job是否已经就绪。jobReady会调用所有注册了的 plugin的Ready判定函数,只有都判定为ready ,才返回true
DRF
实现了Dominant Resouce Fairenss算法,这个算法能够有效对多种资源(CPU、Memory、GPU)进行调度
Drf目的是尽量避免集群内某一类资源使用比例偏高,而其他类型资源使用比例却很低的不良状态。在调度时,让具有最低资源占用比例的任务具有高优先级,主要关注onSessionOpen函数:
- 统计集群中所有node可分配资源总量
- 统计Job资源申请,计算资源占比(资源申请/资源总量)
- 注册Job排序函数,根据资源占比进行排序,主要资源占比越低job优先级越高
- 注册事件处理函数,包括分配函数以及驱逐函数,函数实现比较简单,就是当task发生变化时,增加(分配)/减少(驱逐)Job资源申请总量,并且更新资源占比。
drf注册2个function,分别是:
jobOrderFn是job的排序函数,会让share值越小的job排在最前面,即拥有最高的优先级,这个是实现drf的关键。preemptableFn返回可抢占的job列表,job的筛选规则是:如果待选job的share值大于将被调度的job的share值,则选中该待选job
kub-batch的session跟cache机制是固定的,主要通过action跟plugins机制来实现多样化调度算法.
虽然目前业务上运行的很ok,但根据本人的实践情况来看,不太建议生产使用,原因如下:
本人因为历史原因,接入kube-batch是目前最好的选择,由于kube-batch项目基本已不再维护,其中的有些bug已经有人提issue,但并没有在kube-batch这个项目中fix,而是直接在volcano的fix列表中了,所以如果需要fix,还需要从volcano中cherry-pick过来,但是虽说volcano是基于kube-batch而来,但volcano的版本迭代非常快,真的很难判断cherry-pick过来之后会不会有其它问题,如果有问题再来看volcano,如没有特殊原因还不如直接从一开始就使用上volcano,多快好省.