Kong学习(解决诡异的Kong Error超时及重试问题)
现在业务使用的kong做为api gateway, 最近碰到一个的kong error超时及重试的问题,记录下排查过程
在浏览器中下载后端一个好几G的文件,会出现Kong Error错误,如下图所示

这里说一下,下载文件这个动作整个端到端的请求路径如下:
浏览器 <--> kong <--> frontend(VUE + nginx) <--> k8s service <--> backend <--> resource-factory
backend是则java,提供数据下载,然后返回给前端
frontend与backend之间是通过k8s service 进行访问的
在frontend请求下载的过程中,backend需要先从resource-factory中获取文件保存在bakend本地,这个时间会比较长,backend下载完成之后才会返回到frontend
排查过程
从kong的错误提示来看,很明显,upstream server超时(这个upstream很重要),最开始没注意,只关注到timeout这个关键字了
backend
先从backend的日志开始排查,意料之中,backend日志出现一堆的error,但是意料之外的是,在这过程中出现了每隔60s就会对文件重新下载, 总共进行了5次重新下载的操作,这个比较奇怪,正常只是在页面上点击了一次操作,为何会出现连续下载5次的流程,而且每次下载都没有下载完就进行重试,而且都是每隔60s, 像是有重试的操作,比较诡异
从日志可以肯定的是,下载文件的代码逻辑是没有问题的,因此在这里出现了两个问题:
- 下载代码没问题,但下载为何会失败
- 60s, 5次下载是怎么产生的
下面主要是在排查问题2是如何产生的,还是比较有意思
frontend
从backend没有找到最有价值的信息,那么看看frontend打印的日志中有没有什么思路,由于frontend中包含了一个nginx,大部分的请求都会被记录下来,首先将nginx的日志调整为debug
client xxx.xxx.xxx.xxx closed keepalive connectionepoll_wait() reported that client prematurely closed connection- 出现nginx 499状态码

关于第1个错误(后来被证实这不是错误)看到keepalive closed,那么是不是很自然地想到nginx中有关于keepalive的相关参数,keepalive默认情况下是75s,跟60s好像也不太符合,但是不是确实是这个值太小了呢? 因些作者还是调整了frontend中nginx的keepalive为600s, 但是问题依旧
因此转到第2个错误,网上查找了一翻发现这个跟上面两行出现代码499的原因一致,nginx 499 这个状态码可能接触地比较少,当时也不是很明白这个状态码应对的含义,如果有不清楚的可以参考nginx-499-faq
499一句话概括就是: Nginx 把请求转发上游服务器,上游服务器慢吞吞的处理,客户端等不及了主动断开链接,Nginx 就负责记录了 499, 是不是刚好跟epoll_wait那句话的意思相近。
因此出现错误499及错误2的原因就是客户端主动关闭了连接,
由于下载的文件非常大,大小在4G+, 作者还以为是nginx某些配置的timeout设置的不准确
frontend中的nginx主要调整过的配置项如下:
1 | keepalive_timeout 1200s; |
重启之后发现问题依旧, 这时作者怀疑是浏览器是不是也存在timeout不够长导致连接被断开了
因此直接使用curl的方式请求,发现问题依旧,因此可以排除浏览器的问题
这时作者想起另外一个也同样使用VUE写的前端,VUE的axios(参考)是可以设置http请求的超时时间的,那是不是会由于前端对每个http设置的timeout太短了呢,经过询问前端的同事,果然,前端配置了这个时间为60s,这明显不够,作者欣喜若狂,以为见到了曙光, 然而
** too young, too simple**
前端将60s调整为600s,问题依旧 同样提示上面的错误,同样重复下载5次
** WHAT FXXK**
同时,作者跟前端同事反复确认frontend的逻辑中会不会有重试的代码,前端同事很明确地说:NO
冷静下来
VUE的axios超时时间一定有影响,消除这部分的影响问题依旧,那一定还有别的地方存在timeout从而引起重试机制,既然对于frotend的nginx来说,是客户端主动断开了连接,除了frontend代码本身,那客户端还有谁呢?
kong
在frontend前面的就是kong了,那么它就是客户端,难道是kong这边把连接主动断开了?
为了验证是不是kong这边的问题,作者使用curl直接请求frontend,绕过了kong这一层,发现居然下载没问题了,同时,也不存在每隔60s重复下载一次的现象
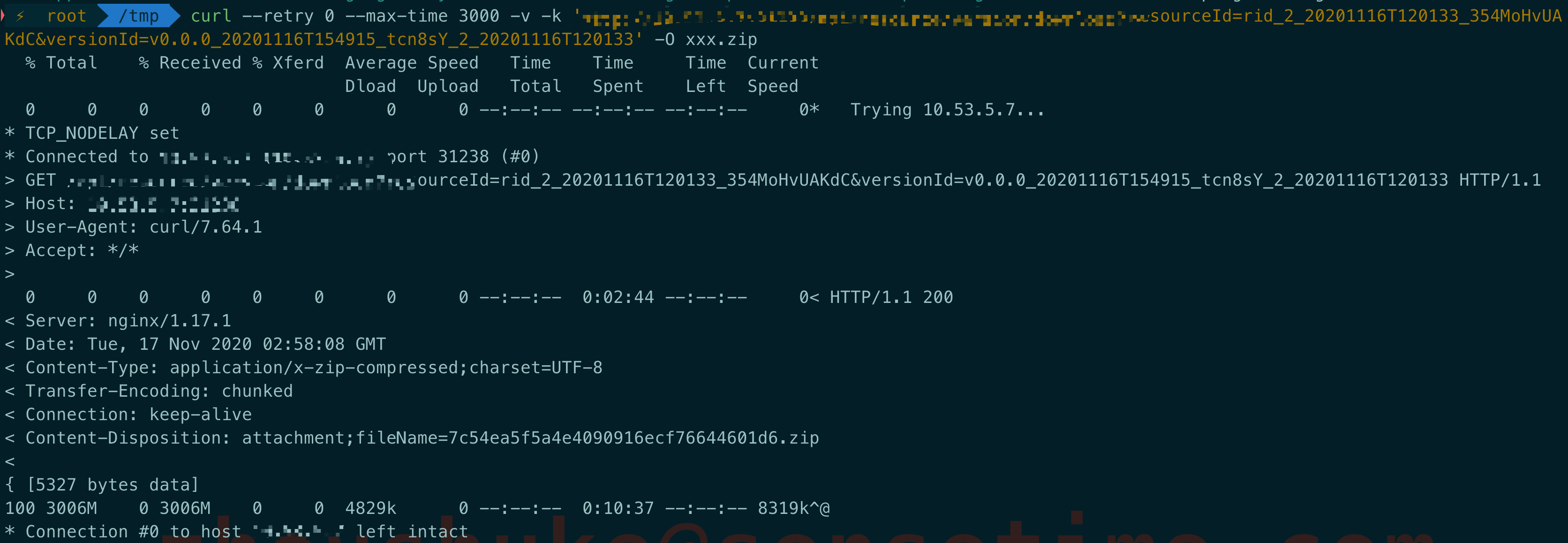
从下载的流程来看,前2分44s应该是backend向resource-factory中获取文件下载到本地的时间,果然时间比较长
后面的10分37s则是backend向frontend的nginx加传文件的时间,时间也比较长
好歹直接通过frontend可以下载文件成功.
柳暗花明又一村
截止到现在归纳一下做过的调整
- 调整了VUE的axios的超时时间,这个是对每个经过frontend的请求都生效
- 调整了frontend中nginx的timeout配置
老规矩,看kong proxy的日志如下:

也是timeout,不过这次作者终于看到了upstream这个词了
这里说的upstream不就是frontend么, 难道是当backend向resource-factory下载文件的时候,也就是2分44s这个时间内,frontend没有收到backend返回的response,frontend也就没有response返回给kong, 在一定时间内(也就是日志中出现的60s)kong无法从frontend中获取到response,出现timeout,然后开始重试,重试5次之后frontend还是没有response,最后kong将这条请求断开了.
这个猜想其实是合理的,符合看到的日志报错,同时也符合5次重试的这个现象
但是5次重启到底是怎么回事,upstream真的就是frontend
作者这里也想到kong其实openresty, 不也是nginx呢?那是不是kong也需要设置一下nginx的timeout配置呢?
嗯,加上再说
1 | - name: KONG_NGINX_PROXY_CLIENT_BODY_TIMEOUT |
按照官方文档将这些参数到容器的env中,然后重启kong
擦,问题依旧
这里看到问题没有解决,第一时间难道是加的参数都没有生效,不能使用environment,作者还特意到容器中验证了一下验证
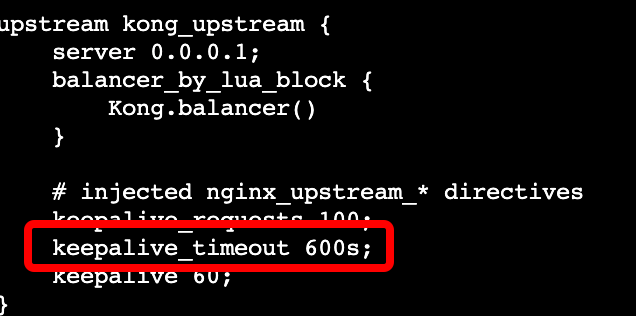
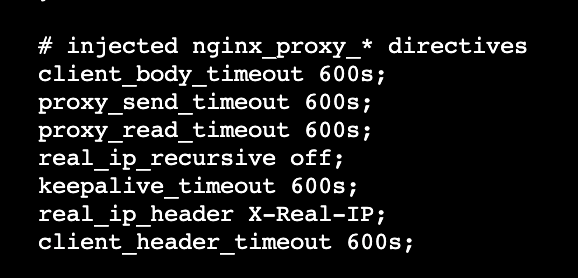
发现都是没有问题的,那为什么还是不行呢?
再次网上搜索一翻,发现kong中对于service(是kong中的service,而不是k8s中的service),还有3个timeout参数
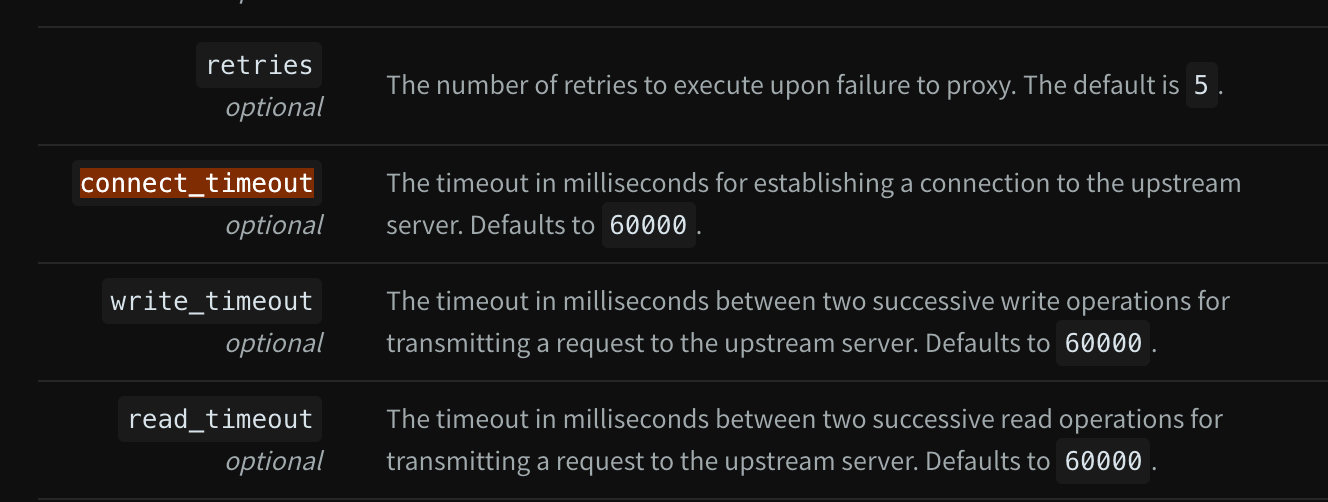
然后到kong中查看对应的service, 如下:

发现这3个timeout都是默认值,为60s, 而且,retries为5,刚好跟重试的现象对应上了
先不管,使用如下命令更新一下这个记录,将timeout改长一点
1 | curl -X PATCH --url https://127.0.0.1:8444/services/791f94ae-7971-54e5-8996-e66083af6617 \ |
发现提示下面的错误:

真是一步一个坎, 更新操作不支持,作者也试过删除操作,发现也是同样的错误
这个错误的原因在于作者使用的kong是DB-less的模式,对于db-less下是不能修改绑定在kong上的entities serivces的
那不能更新也不能删除,那么就只能重建了service了,kong中的service对应的是kongingress中的proxy,更新如下
1 |
|
这样更新之后会发现kong中serivce的记录还是不变,经过多次的实验,正确的操作如下:
- 先将ingress删除后,会发现kong中的service记录也删除掉了
- 然后将k8s中的service加上annotations指定
konghq.com/override: kongingress-resource - 再发布ingress, 同样指定
konghq.com/override: kongingress-resource
经过上面的3个操作之后,再来看kong中service的记录,更新成功

这个时候再测试页面的下载功能,就没有再出现过超时及重试的现象了,
完美
总结
对于这次诡异的timeout问题可以看出, 中间的转发层一多,因为每一层都可能超时,原因排查起来就比较费力
在排查过程中,每个错误都可能是关键信息,不要选择性忽略,对于这次作者其实就忽略了upstream这个信息
当然如果从一开始就关注到upstream,也还是要将上面的排查过程走一遍,因为确实有好几个地方都是有问题的
比如UVE的axios的超时配置,nginx的超时配置,作者在这过程中甚至还想到过k8s中service的超时机制
有用的知识又增加了一些.
参考文章:
- https://docs.konghq.com/1.1.x/configuration/
- https://docs.konghq.com/1.1.x/configuration/
- https://github.com/Kong/kubernetes-ingress-controller/issues/472
- https://github.com/Kong/kubernetes-ingress-controller/issues/905
- https://linuxops.org/blog/kong/admin.html
- https://docs.konghq.com/1.1.x/admin-api/#update-service
- https://imajinyun.xyz/2019/11/15/nginx-499-faq/
- https://lanjingling.github.io/2016/06/11/nginx-https-keepalived-youhua/
- https://luanlengli.github.io/2019/07/02/Kong-Ingress-Controller%E9%83%A8%E7%BD%B2.html
- https://blog.csdn.net/qq_36727756/article/details/93738441