使用crash查看Linux系统异常重启原因
最近有一台物理机间歇性的发生重启, 本以为是偶发事件就没多在意,今天又给重启了, 因此决定探探究竟
首先看一下kdump服务是否开启, kdump主要用于内核发生crash时记录相关上下文的. 用来转储运行内存的一个工具
简言之: 系统一旦崩溃,内核就没法正常工作了,这个时候将由kdump提供一个用于捕获当前运行信息的内核,
该内核会将此时内存中的所有运行状态和数据信息收集到一个dump core文件中以便之后分析崩溃原因
之后系统便会重启.
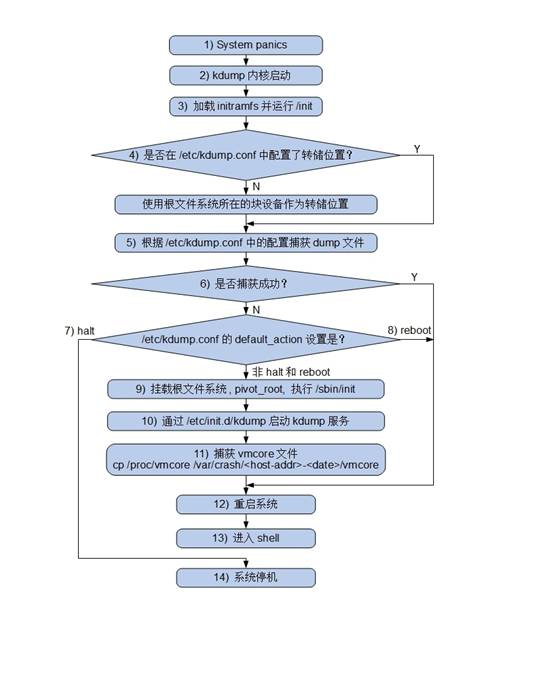
关于kdump在内核已经崩溃的前提下还能够捕获到异常信息, 原理可参考
这里引用一张图
要分析core文件,可以使用crash工具,首先是安装:
注意, 要安装与当前内核对应的版本, 要不然crash无法使用.
1 | wget http://debuginfo.centos.org/7/x86_64/kernel-debuginfo-common-x86_64-3.10.0-693.el7.x86_64.rpm |
通常, 内核crash后保存的core文件保存在/var/crash目录下,在该目录下找到最近一次crash的时间,使用以下命令启动crash分析dump.
1 | crash vmcore /usr/lib/debug/lib/modules/3.10.0-693.el7.x86_64/vmlinux |
启动之后就进入到了crash命令行,很明显地显示出crash的原因,如下图红框所示:
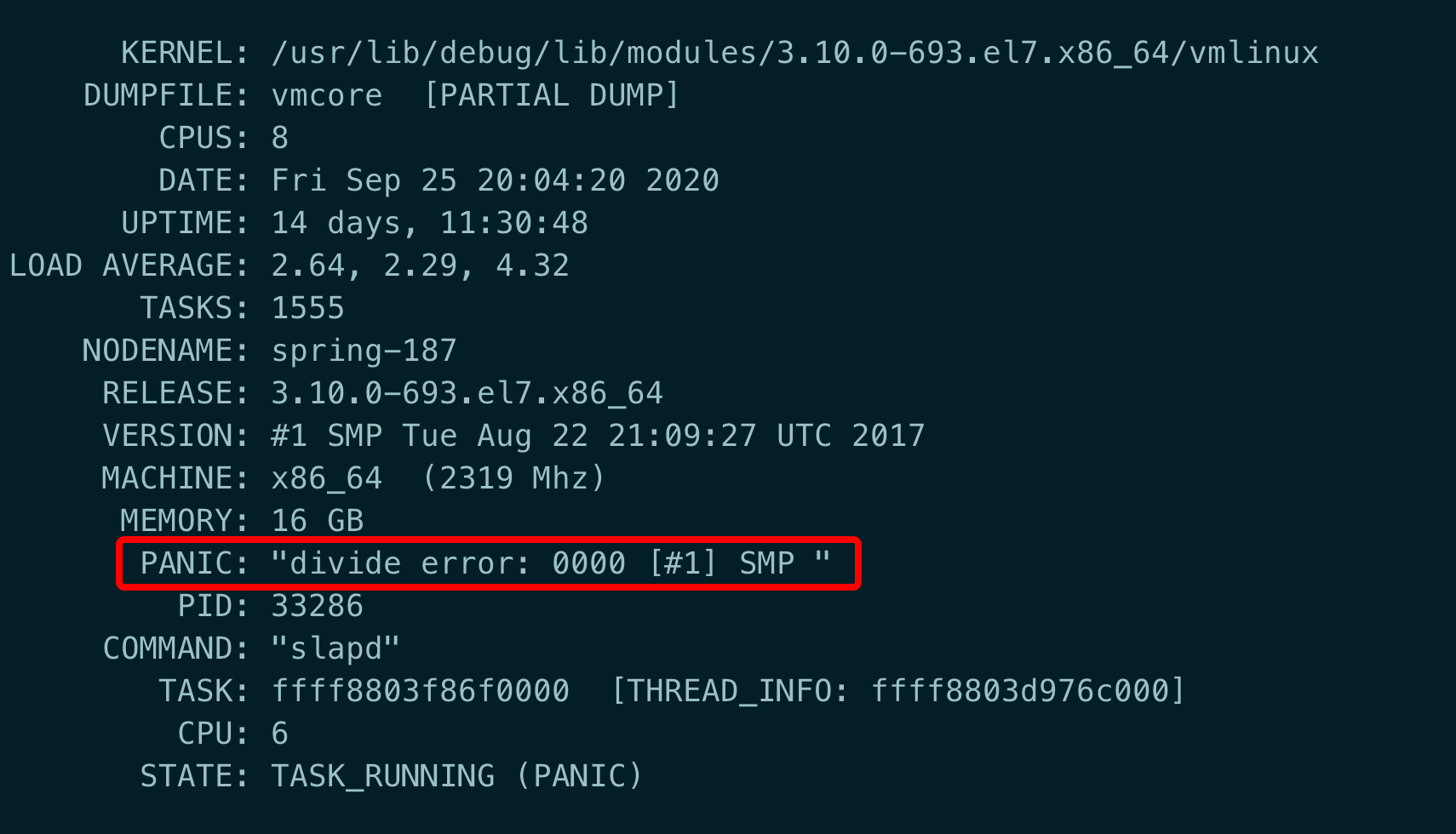
这里简要地反应出内核crash时的一些内存信息快照,包含一些物理信息, tasks数量,最重要的就是导致crash的command与panic的原因
这里可直接使用ps查看进程的相关信息,跟linux 命令行下的ps功能相似
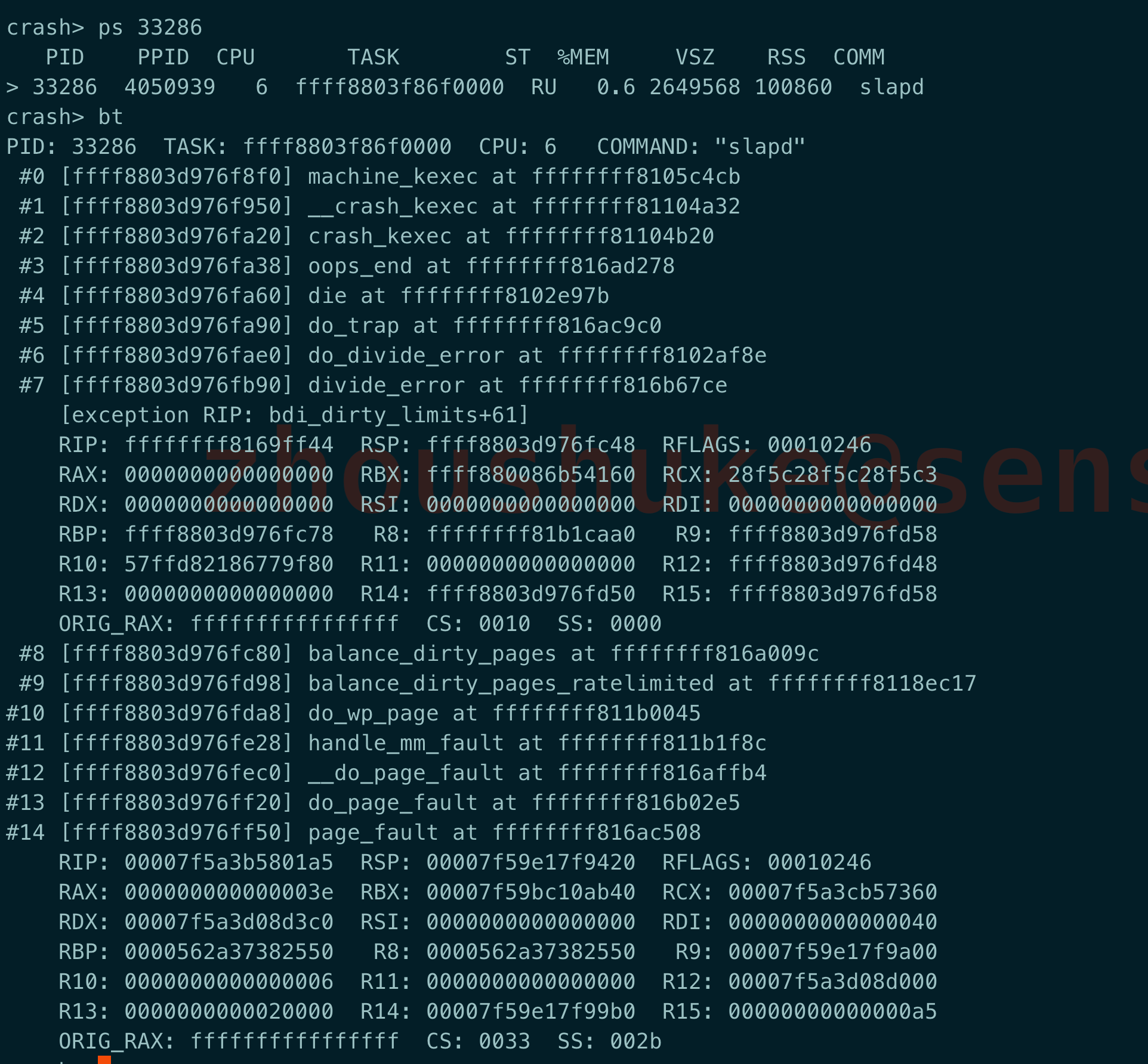
还可以使用bt命令来查看trace信息, 当然都是一些汇编层的内容,需要有一定的专业知识,理解起来比较困难.
从上面已经知道了panic的原因后就可对症下药.
另外crash支持很多的子命令,大家可使用man crash查看,比较常用的为
1 | crash ps # 查看进程 |