Grafana学习(Loki日志系统初试)
基于kubernetes为容器平台的业种中, 对于日志的收集,使用最多的是FEK, 不过有时候,FEK在架构上会略显重, ES的查询及全文检索功能其实使用的不是很多.LoKi做为日志架构的新面孔, 由grafana开源, 使用了与Prometheus同样的label理念, 同时摒弃了全文检索的能力, 因此比较轻便, 非常具有潜力
like Prometheus, but for logs
Loki是 Grafana Labs 团队最新的开源项目,是一个水平可扩展,高可用性,多租户的日志聚合系统。它的设计非常经济高效且易于操作,因为它不会为日志内容编制索引,而是为每个日志流编制一组标签。项目受 Prometheus 启发,官方的介绍就是:Like Prometheus, but for logs,类似于 Prometheus 的日志系统
与其他日志聚合系统相比,Loki具有下面的一些特性:
- 不对日志进行全文索引。通过存储压缩非结构化日志和仅索引元数据,Loki 操作起来会更简单,更省成本。
- 通过使用与 Prometheus 相同的标签记录流对日志进行索引和分组,这使得日志的扩展和操作效率更高。
- 特别适合储存 Kubernetes Pod 日志; 诸如 Pod 标签之类的元数据会被自动删除和编入索引。
- 受 Grafana 原生支持。
Loki 由以下3个部分组成:
loki是主服务器,负责存储日志和处理查询。promtail是代理,负责收集日志并将其发送给 loki,当然也支持其它的收集端如fluentd等Grafana用于 UI 展示
同时Loki也提示了command line工具,通过这个工具可以使用http的方式与loki进行交互,这个后面说
架构
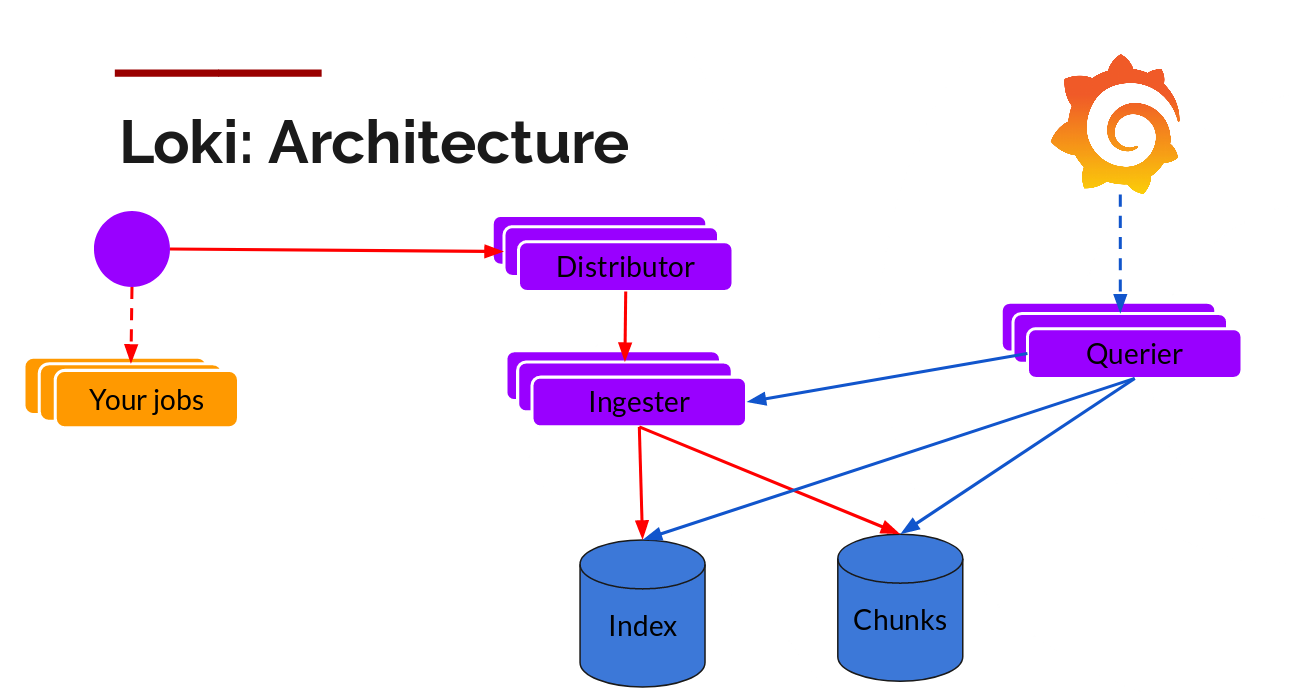
安装
官方提供了多种的部署方式, 这里选择使用helm, 如果只是想试用的话则非常简单, 直接参考helm即可run起来,这里就不做搬运工了
1 | helm repo add loki https://grafana.github.io/loki/charts |
配置
对于loki来说,loki端的配置相对来说会比较简单, 采集端由于可以使用pipeline, 因此会稍复杂点,但是如果接触过prometheus,那其它会觉得还是挺情切.
先来看服务端loki的配置
loki.yaml
1 | auth_enabled: false |
loki服务端主要定义了数据到达控制面之后的一些策略, 比如ingester size大小, 存储路径等的信息,最好使用SSD.
再看看采集端配置
promtail
prometail同时充当服务端及客户端
server
1 | server: |
promtail做为服务端, 可同时提供http及grpc能力,而需要进行数据发送到loki时,promtail则为客户端
client
1 | client: |
当做为client时, promtail做为日志的收集端,然后发送到loki实例
backoff_config 参数指定了当发送日志到loki实例失败时采取的重试策略
external_labels则可以在所有的日志发送到loki实例前加入k-v的labels.
1 | # WARNING: If one of the remote Loki servers fails to respond or responds |
target_config
控制从发现的日志文件中读取行为,比如多久读取一次
1 | target_config: |
scrape_configs
1 | scrape_configs: |
上面是最重要的一个配置, 会发现跟prometheus的配置文件很像, 这里不对上述配置语法进行细说, 感兴趣的可以参考prometheus文档, 这里使用了跟prometheus相同的服务发现机制, 同时也是基于lable进行一系列的增删改的操作, 最终实现一条日志上存在多个label,我们可以基于这些label来查询日志
这个是直接使用官方提供的example, 可以根据实际情况进行修改.
pipeline
可以看到上面的配置中出现一个pipeline的选项,这个是用于指定采集到日志后可以进行的操作, 以stage为单位, 目前支持4种stage.
- 解析阶段:解析当前日志行并从中提取数据。然后,提取的数据可供其他阶段使用。
- 转换阶段:转换从先前阶段提取的数据。
- 行动阶段:从先前阶段中提取数据并对其进行处理。在日志行中添加或修改现有标签 更改日志行的时间戳 更改日志行的内容 根据提取的数据创建指标等
- 筛选阶段:可以根据某些条件选择应用阶段的子集或丢弃条目
同时每个stage又有一些预设的可直接供使用的操作.
比如上面指定的docker,就属于解析阶段, 它的作用是通过使用标准Docker格式解析日志行来提取数据
这对于直接将应用日志输出到console,然后通过docker的格式打印出来的情况下非常方便. 这也是最常见场景
官方的说明
使用
- 选择数据源

- 填写URL
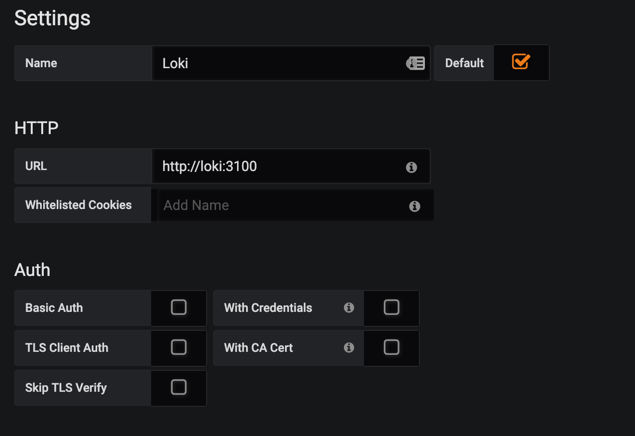
- 切换到
Explore --> 选择Loki
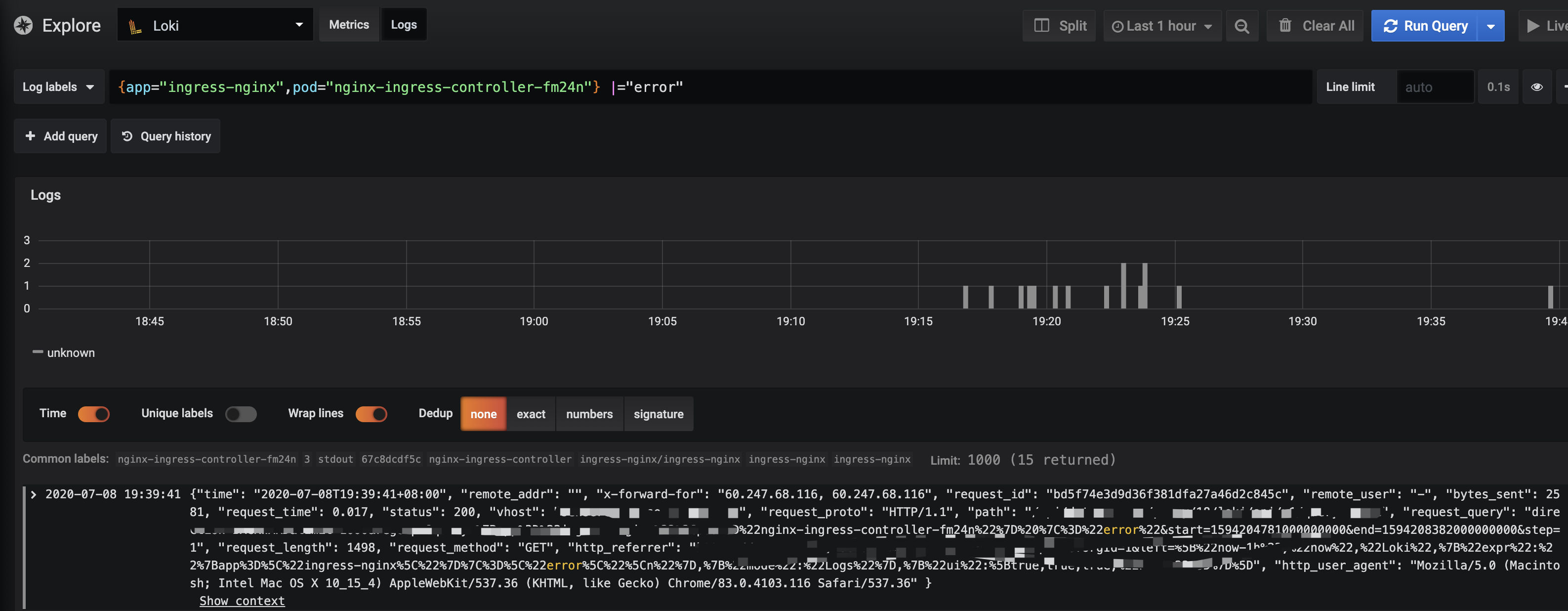
Log labels下拉框中可以下拉选择通过上述服务发现生成的的日志labels, 中间则可以使用label语法进行筛选
1 | {app="ingress-nginx", pod="nginx-ingress-controller-fm24n"} |="error" |
前半部分很好理解, 后面的|="error"则是在前半部分筛选出来的结果中再次grep出存在error的日志
这里使用的是LogQL语法, 见下文
- 添加dashboard
LogQL
Loki 使用一种称为 LogQL 的语法来进行日志检索,语法类似 PromQL
Log Stream Selector
也是使用大括号进行条件的筛选, 同时支持正则
1 | {app="mysql",name=~"mysql-backup.+"} |
=: exactly equal.!=: not equal.=~: regex matches.!~: regex does not match.
Filter Expression
1 | {instance=~"kafka-[23]",name="kafka"} != "kafka.server:type=ReplicaManager" |
|=: Log line contains string.!=: Log line does not contain string.|~: Log line matches regular expression.!~: Log line does not match regular expression.
Metric Queries
这个其实就跟prometheus中的很想像了.
1 | rate({job="mysql"} |= "error" != "timeout" [5m]) |
rate: calculates the number of entries per secondcount_over_time: counts the entries for each log stream within the given range.bytes_rate: calculates the number of bytes per second for each stream.bytes_over_time: counts the amount of bytes used by each log stream for a given range.
Aggregation operators
当然还支持一些聚合操作,比如
1 | avg(rate(({job="nginx"} |= "GET")[10s])) by (region) |
sum: Calculate sum over labelsmin: Select minimum over labelsmax: Select maximum over labelsavg: Calculate the average over labelsstddev: Calculate the population standard deviation over labelsstdvar: Calculate the population standard variance over labelscount: Count number of elements in the vectorbottomk: Select smallest k elements by sample valuetopk: Select largest k elements by sample value
还有很多比如’and, or’的操作都是支持, 就不一一搬运了
logcli
logcli做为一个命令行工具, 可以直接与loki进行交互, 目前grafana是不支持对loki进行告警, 可以通过logcli写脚本的方式进行,也是种办法
性能
要知道es产生的索引可能跟日志本身一样大, loki最大的特点就是同一类型的日志带有相同的label,这样的话产生的索引就会压缩几个数量级,这就不需要像es查询一样将索引放入内存中, 从而可以使内存加载更大的日志量, 另一方面, loki实现了类型于分布式的grep,会将查询分解成较小的shard并行处理, 因为不需要全文检索,因此速度上会更快.
关于性能方面也局限于官方的说法, 还没有做过性能测试,目前还没有在生产上使用loki, 但是在QA/DEV环境中使用,体验还是不错的, 不用在grafana/kibana来回切换了.