FELK学习(踩坑记)
各种各样的问题大部分都可以为是业务日志不规范的, 当然这个是不可避免的, 规范不是一天建立起来的.
在没有建立起来之前, 只能像打补丁一样修复
在这里记录下运维EFK踩过的坑, 不定期更新
日志流
[Kubernetes/LB/...] --> fluentd --> kafka --> logstash --> es
type不覆盖
最近就发现存在小部分的日志丢失了, 经过层层debug, 终于发现原来是因为源日志中就存在type这个字段,
因为logstash环节一般都会根据业务添加一个type来进行区别, 然后根据不同的type输出到不同的存储,
平时很少会关注日志本身的字段, 导致这个问题花了差不多一天的时间定位.
如果源日志中就存在有type字段, 而在logstash中又指定了type, 那么这个type不会覆盖源日志中的type(后来想想其实也可以理解, 业务数据为王嘛)
官方有说明, 这个有点巧, 刚好在页面的最下面, 都不怎么会看到
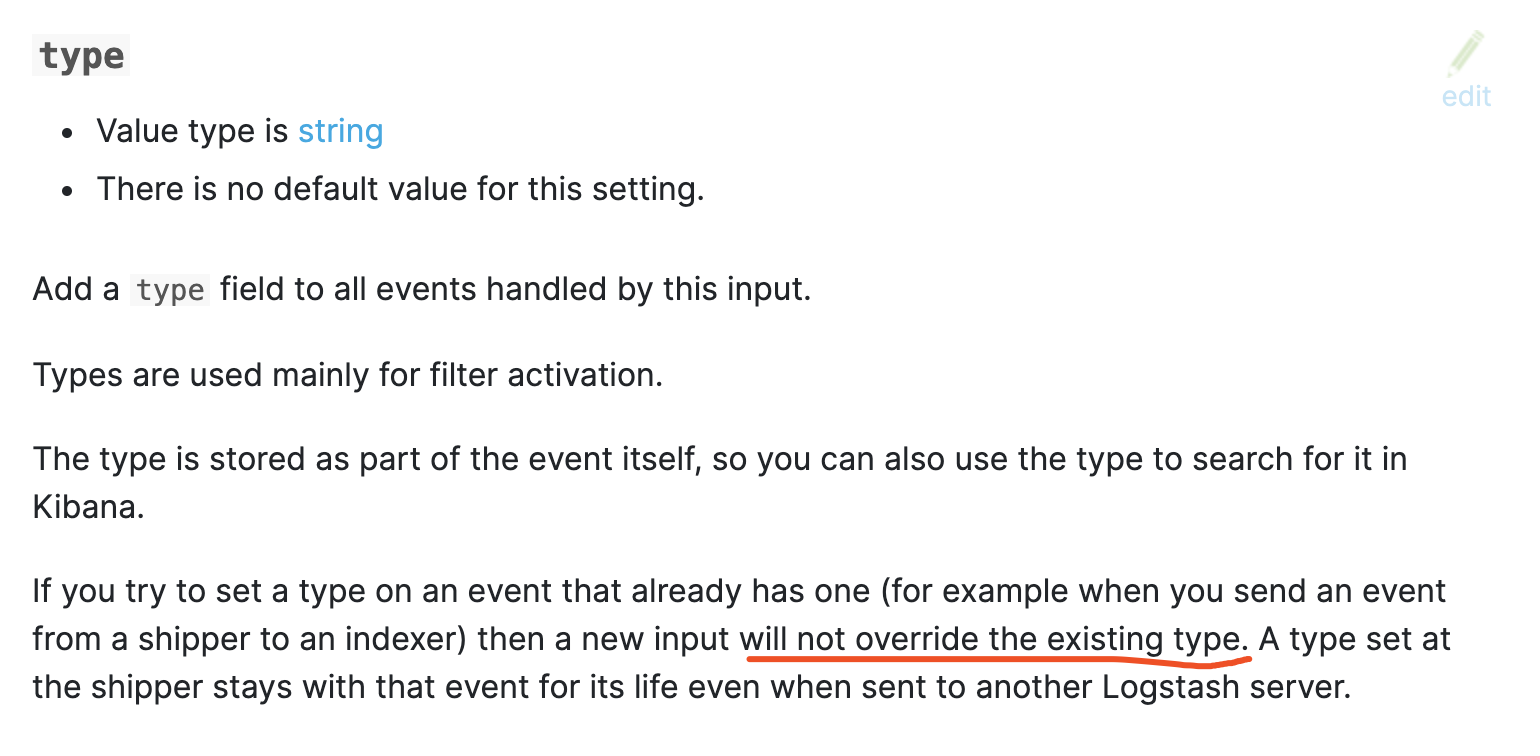
因此在output中出现使用type来做为判断条件的那就会被丢弃掉, 因此此时的type是你源日志中的type.
1 | output { |
找到问题解决办法也就容易多了, 直接在fluentd上把这个字段进行重命名, 就是add一个字段然后再把type字段remove
1 | <filter kubernetes.**> |
这个问题也反映出本人对logstash用的不是很熟.
字段类型转换
由于后端的存储使用的es, es中有个 Dynamic Mapping, 默认情况下是开启状态, 这个特性能够根据文档的字段动态地进行填充, 也就是说新增字段会自动地添加mapping, 但是无法对已经存在的字段进行修改
一般情况下, 索引都是按天进行分隔, 也就是在零点的时候会自动生成新的索引,然后这个索引的mapping以第一条进来的文档为准, 假如有个字段, 比如下面的call_db_dynamic_response.score这个field, 这个表示对比的一个得分(代码中的float64),假如第一个文档中的这个score为1, 那么这个在es中的类型为long类型, 那么就不能改变,
但是score可能会再传过来0.99,那么这个时候就会出现以下报错, 这条数据是无法进入es的,es中long与float是不一样的类型

那么解决办法, 有以下几种方式:
- 直接从源代码中修改, 代码中本身就是float类型, 而且这个值是底层SDK传过来的, 在业务层做判断不是很友好, 毕竟每次都将多一层判断, 影响性能
- 可以在logstash中对改字段进行类型转换
- 在创建索引时使用自定义的template
这里我采取的是第2种办法, 没有采用第1种办法是因为代码中本身就是float类型, 而且这个值是底层SDK传过来的, 在业务层做判断不是很友好, 毕竟每次都将多一层该值判断, 影响性能,把这个操作移步到日志系统中,毕竟日志系统只是做为一个排查工具, 不需要那么实时
在logstash中进行类型转换用到了filter的mutate,当然这里最好也对索引做个判断
1 | if [tag] == "yourindex" { |
这样的话, score就永远都是float类型了.
这里没有使用自定义的template,理论上这种方法是性能最高的, 因为不需要每条日志都判断一下是否存在这个score字段, 不过本人还是觉得第2种方法更容易, 效果还行.
字段多种类型
这个报错的原因跟上面的类似, 都是因为es对field的类型不支持多个, 如果是个object,那你就无法把一个值写进去,不然会提示以下错误

这个问题曾经引起过一次线上es的启机, 有兴趣的可以看这里的分析
kafka版本不匹配

这是本人遇到过的最坑爹的问题
由于有个环境需要下线, 在迁移的过程中使用了一个新版本的fluentd, 但是却无法对接这个kafka
fluentd使用了一个fluent-plugin-kafka, 比较坑的是里面有个ruby_kafka的client, 如果kafka的版本太旧而fluentd的版本又太新的话, 就会造成ruby_kafka_client无法适配旧版的kafka, 折腾半天无果后果断放弃, 由于这个kafka无法直接升级,最后只能重新搭建了一个新版本的kafka, 问题解决
fluentd的tag
在使用fluentd中大家看fluentd的配置文件,开始的时候一定会对tag的使用有点懵
1 | <source> |
这是一段收集kubernetes容器日志的经典配置
在source中使用了tail指定了path,tag, 那么这个时候的tag到底是什么?
先看下官方的说明
1 | #* can be used as a placeholder that expands to the actual file path, replacing '/' with '.'. For example, if you have the following configuration |
意思就是说, tag是由tag+path一起组成,如上面,
path=/var/log/containers/*.log
tag=kubernetes.*
那么在filter时使用了kubernetes.**来表示匹配所有以kubernetes开头的tag
每一个容器的tag为kubernetes.var.log.containers.xxxxx.log
xxxxx指/var/log/containers/目录下容器的信息
注意:
.*跟.**是有区别的, 引入官方文档
The following match patterns can be used in and tags.
*matches a single tag part.For example, the pattern
a.*matchesa.b, but does not matchaora.b.c
**matches zero or more tag parts.- For example, the pattern
a.**matchesa,a.banda.b.c
- For example, the pattern
{X,Y,Z}matches X, Y, or Z, where X, Y, and Z are match patterns.- For example, the pattern
{a,b}matchesaandb, but does not matchc - This can be used in combination with the
*or**patterns. Examples includea.{b,c}.*anda.{b,c.**}
- For example, the pattern
#{...}evaluates the string inside brackets as a Ruby expression (See the section “Embedding Ruby Expressions” below)When multiple patterns are listed inside a single tag (delimited by one or more whitespaces), it matches any of the listed patterns. For example:
- The patterns `` match
aandb. - The patterns `` match
a,a.b,a.b.c(from the first pattern) andb.d(from the second pattern).
- The patterns `` match
所以,这个tag还是非常长的, 因此最后都会将tag改成故名知义, 比如改成服务名.
1 | <match kubernetes.**> |
The connection might have been closed. Sleeping for 64 seconds

原因: 从grafana上来看,fluentd的cpu会出现周期性的突升,同时,在apiserver会出现大量的watch pod调用
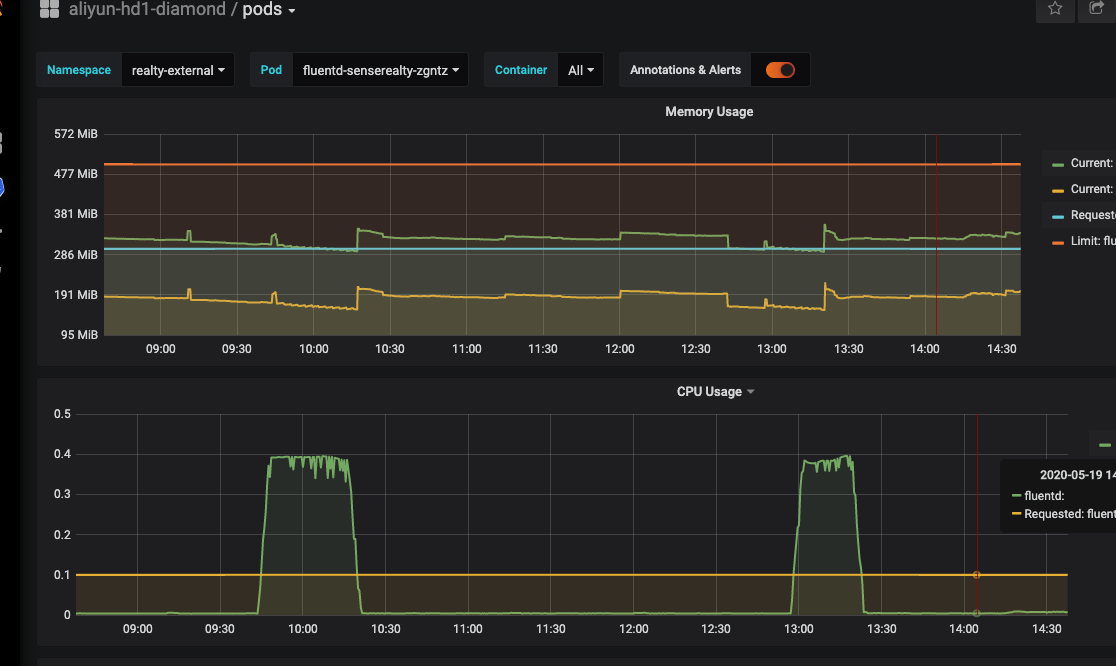
解决: 增大fluentd的cpu使用,同时在配置文件中修改插件filter_kubernetes_metadata,
增加watch false,减少频繁地去请求apiserver
1 | # Enriches records with Kubernetes metadata |
使用wildcard查询时无记录
经常,会使用wildcard来查询某个时间段内的某个字段包含某个值的记录, 假如现在要筛选出15钟之内的msg中包含unaryInterceptor的记录
假如doc字段如下:
1 | { |
那么相应的会使用以下的查询语句:
1 | curl -H 'Content-Type: application/json' -XGET 'http://localhost:9200/demo-*/_search?pretty&_source_include=%2A%2C%40timestamp&ignore_unavailable=true&scroll=30s&size=10' -d '{ |
执行之后会发现,得到的结果为空,百思不得其解.
1 | { |
但是从kibana上查看,在指定的时间段内是存在记录的, 原因就在于**msg字段本身是analyzed的,elasticsearch对于analyzed的字段会将字段按空格进行分隔, 而且会所有的大写字母转换成小写字母**, 因此,在上面使用的通配符中有大写字母就无法匹配上了,这也是为何结果无记录的原因,那么解决方案有两个
- 通配符里直接使用小写
- 对于
analyzed的字段可直接使用内置的keyword, 比如上面可改成"msg.keyword": "*unaryInterceptor*",那么这样的话原始的字符就可以匹配上了,参考github
排查技巧
fluentd
fluentd的一个排查技巧就是debug模块, 只需要在fluentd的启动参数中指定级别

当然在各类的output插件中, 也支持开启debug模块, 这个大家可以查看官方文档
kafka
kafka除了上次遇到过的版本问题也没出现过有问题是因为kafka造成的,但是有几条命令还是比较有用的, 毕竟数据经过它, 看看数据有时还是有必要
1 | # 查看消费者 |
后面那个命令可以看到数据进kafka是否符合预期, 当然这个数据可以直接在fluentd中看到, 是一样的
这里要注意一个问题就是, 版本不同的kafka, 上面两条命令有所不同, 有时可能会需要使用–zookeeper.
logstash
1 | output { |
logstash定位日志时可以打印到console或者文件中
在个grok在线debug的[工具][https://grokdebug.herokuapp.com/
es
1 | # 查看索引 |
未完待续
参考文章:
- https://izsk.me/2019/10/06/ES-FGC-Fix/
- https://docs.fluentd.org/
- https://github.com/fluent/fluent-plugin-kafka
- https://grokdebug.herokuapp.com/
- https://docs.fluentd.org/input/tail#tag
- https://docs.fluentd.org/configuration/config-file
- https://www.matviichuk.com/2016/07/08/nested-json-in-logstash
- https://www.elastic.co/guide/en/logstash/current/plugins-inputs-kafka.html#plugins-inputs-kafka-type
- https://www.elastic.co/guide/cn/elasticsearch/guide/current/dynamic-mapping.html
- https://stackoverflow.com/questions/51849598/elasticsearch-wild-card-query-not-working