Prometheus学习(MetricTypes)
在学习prometheus的时候,相信大家也会对prometheus里的各种数据类型及内置函数有很多疑惑, 为了加深印象来记录下工作中常用到的函数,在这之前, 先来温故下prometheus中的4种metric types.
数据模型
prometheus中所有的数据都是时序流, 我们在prometheus的ui中看到的数据虽然没有看到时间戳, 但在prometheus底层存储中是存在时间戳与之对应, 简单来说, prometheus的数据模型就是Metrics+labels+timestamp

alertmanager_alerts为metrics key
instance、job等这些都是labels,可以理解为查询时的条件
value为这条metric的值
注意: 在prometheus中value只能是float类型的数值, 不可以是其它值
监控项类型
虽然prometheus的value只能是float类型的数值, 但是这个value是有一种数据类型与之对应的, prometheus中存在4种监控项类型, 官方文档在这里
gauge
gauge表示可以任意波动的单一值, 没有规律, 直观的例子就是可以表示机器的网卡流量, 因为你无法预料在下一秒的有多少入口流量 或多或少.

counter
counter为计数器,只增不减 用于只增不减的场合,直观的例子机器的开机时t、长nginx的请求数等, 在某个时刻之后, 这个数只会一直增长而不会减少, 但是可以允许被重置为0

上面两个类型比较好理解, 难理解的histogram与summary.
histogram
histogram表示累积直方图, 主要用于表示一段时间范围内对数据进行采样(通常是请求持续时间或响应大小),并将其计入可配置的存储桶(bucket)中,并能够对其指定区间以及总数进行统计
所以, 在很多的metric key中如果看到xxx_bucket时, 大部分表示这条记录的类型为histogram.
很直观的一个例子, 统计ingress_nginx中请求的响应时间(单位:秒)
nginx_ingress_controller_response_duration_seconds_bucket
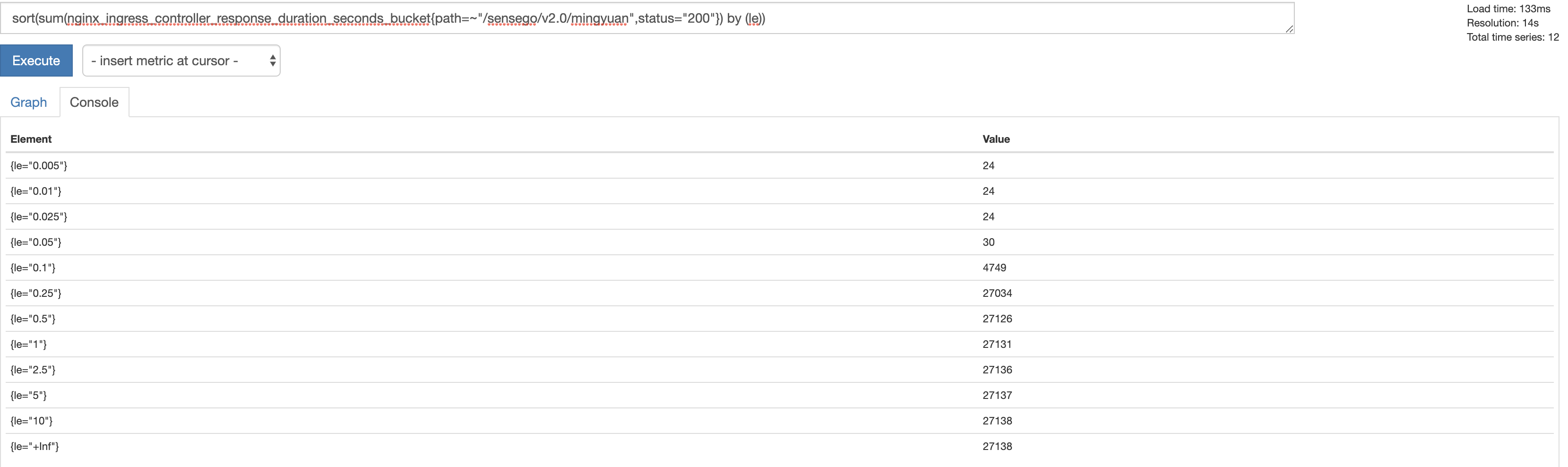
看到这可能会有人问, 这个结果是不是有问题, 这个le是什么意思?
首先说一下这个le,它并不是一个单位,而是表示bucket的一个区间, 这个le是在ingress_nginx的代码中定义的.
另一个要明白的是, histogram是累积直方图
因此上图就很容易理解了
Ingress_nginx代码中定义了所有bucket的区间值(当然,作者可以随便定义), 所有请求产生的响应时间都会落在这些区间之内。
- 响应时间<0.005的请求个数为24
- 响应时间<0.01的请求个数为24, 包括<0.005,也就是说没有请求的响应时间在 0.005与0.01之间
- 响应时间<0.025的请求个数为24,包含<0.01的区间, 也就是说没有请求的响应时间在0.01与0.025之间
- 响应时间<0.05的请求个数为30, 包含<0.025的区间, 也就是说请求的响应时间有6个落在0.025与0.05之间
- …
- 响应时间<0.25的请求个数为27034, 包含<0.1的区间
- …
从这个过程就可以知道为什么叫累积直方图了, 从上面的例子来总结,大部分的请求都落在0.1s到0.25s之间
这里要注意一下le=+lnf这条记录, 这个其实表示所有的记录, lnf表示最大的bucket的往上, 这里是10s以上的记录,从上图可以看到, 不存在响应时间大于10s, 正常也不应该有
同时histogram也提供<basename>_sum,<basename>_count这两个指标
总结来就:
<basename>_count就是一个计数器, 它只会增加,表示次数
<basename>_sum也可以是一个计数器,它表示监控项对应的值的总和
先来看一下nginx_ingress_controller_response_duration_seconds_count

会发现这3条记录value之和与le={+lnf}的值是相等的, 因此count表示对采样点的次数累计和,这里也就是请求总数
而``nginx_ingress_controller_response_duration_seconds_sum`

sum表示的是所有value的总和,这个很好理解
因此,如果想计算最近5分钟内的平均请求持续时间
可以使用以下表达式:
1 | rate(nginx_ingress_controller_response_duration_seconds_sum[5m]) / rate(nginx_ingress_controller_response_duration_seconds_count[5m]) |
同时 histogram也是可以计算分位数, 使用histogram_quantile
Prometheus 通过 histogram_quantile 函数来计算分位数(quantile),而且是一个预估值,并不完全准确,因为这个函数是假定每个区间内的样本分布是线性分布来计算结果值的。预估的准确度取决于 bucket 区间划分的粒度,粒度越大,准确度越低
histogram_quantile(φ float, b instant-vector)
假如,要计算95%的响应时间落在哪个区间可以使用以下命令
histogram_quantile(0.95, sum(rate(nginx_ingress_controller_response_duration_seconds_bucket{path=~"/sensego/v2.0/mingyuan",status="200"}[1800m])) by (le))

会发现大约在0.23s
注意: 在数据量大的情况下,histogram_quantile计算可能会消耗大量CPU, 因为它是在服务端实时计算的.
这个函数的源码在这里
summary
summary表示摘要数据, 这个跟histogram比较想像, 反映的都是统计类数据
summary主要用于表示一段时间内数据采样结果(通常是请求持续时间或响应大小),它直接存储了 quantile 数据,而不是根据统计区间计算出来的。
prometheus_target_interval_length_seconds表示目标抓取所用时间

很大的一个区别是quantile, 翻译过来就是分位数, 这个区间也是在源码里定义
上面的图表示的含义是:
- 有1%的目标抓取时间为19.936946996
- 有5%的目标抓取时间为19.999956628
- 有50%的目标抓取时间为20.000021361
- 有90%的目标抓取时间为20.00006137
- 有99%的目标抓取时间为20.071892568
从这里可以看出,99%的时间都是20s内, 跟设置的interval=20s基本符合.
同时summary也提供<basename>_sum,<basename>_count这两个指标,这个跟histogram差不多
prometheus_target_interval_length_seconds_sum

prometheus_target_interval_length_seconds_count

需要注意的是: 不能对Summary产生的quantile值进行aggregation运算(例如sum, avg等)
summary与histogram区别
从上面可以发现Summary和histogram是比较类似,在使用上要如何区分呢?prometheus上有篇post专门解释了这两个的区别, 详情
首先要明白是Summary的quantile计算是在数据上报的时候(简单来说就是在客户端就计算好的)就已经计算好的,需要在定义数据指标的时候就指定quantile的值,因为是数据上报计算的quantile,所以不支持包含数据过滤和聚合的quantile计算
因此对于分位数的计算而言,Summary在通过PromQL进行查询时有更好的性能表现,而Histogram则会消耗更多的资源。反之对于客户端而言Histogram消耗的资源更少。在选择这两种方式时用户应该按照自己的实际场景进行选择. Summary 结构有频繁的全局锁操作,对高并发程序性能存在一定影响。histogram仅仅是给每个桶做一个原子变量的计数就可以了,而summary要每次执行算法计算出最新的X分位value是多少,算法需要并发保护。会占用客户端的cpu和内存
histogram不能得到精确的分为数,设置的bucket不合理的话,误差会非常大
两条经验法则:
- 如果需要汇总,请选择直方图。
- 否则,如果您对将要观察的值的范围和分布有所了解,请选择直方图。无论值的范围和分布如何,如果需要准确的分位数,请选择摘要