这篇主要学习下golang中的数组及slice(切片)及常规操作, 主要是slice, 但是并不会涉及slice的底层原理, 这个范围比较大, 有必要单独拎出来.
数组(array)
定义
数组是内置(build-in)类型,是一组同类型数据的集合,它是值类型,通过从0开始的下标索引访问元素值。在初始化后长度是固定的,无法修改其长度, 数组的大小是类型的一部分。因此[5]int和[25]int是不同的类型
数组的大小必须是常量表达式, 也就是说长度需要在编译阶段能够确认.
1
2
3
4
5
6
7
8
9
10
11
12
13
|
func ArrayDemo() {
aRray := [...]int{1, 3, 5, 7}
bRray := [2]int{1, 2}
cRray := [3]int{1:10, 2:20}
dRray := [3]int{1, 2}
eRray := [2]int{1, 2, 3}
fmt.Println(aRray, bRray, cRray, dRray)
}
[1 3 5 7] [1 2] [0 10 20] [1 2 0]
|
简单来说就是, 在定义数组时需要为数组指定长度, 或者使用[…], 如果未指定的即为slice
访问
1
2
3
| aRray := [...]int{1, 3, 5, 7}
aRray[0]
aRray[5]
|
比较
数组的大小是类型的一部分。因此[5]int和[25]int是不同的类型,只有在当数据的长度及类型完全一样时,该数据组才能比较
1
2
3
4
5
6
7
8
9
| aRray := [...]int{1, 3, 5, 7}
bRray := [...]int{1, 2, 3, 4}
cRray := [4]int{1, 3, 5, 7}
dRray := [4]string{"1", "3", "5", "7"}
fmt.Println(aRray == bRray)
fmt.Println(aRray == cRray)
fmt.Println(aRray == dRray)
fmt.Println(aRray == bRray)
fmt.Printf("%p, %p", &aRray, &cRray)
|
只有在当数组的长度及类型及元素值完全一样时,该数组才相等, 注意,相等并不相同.
遍历
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| aRray := [...]int{1, 3, 5, 7}
l := len(array)
for i := 0; i < l; i++ {
fmt.Println(array[i])
}
for k, v := range aRray {
fmt.Printf("k=%d, v=%d\n", k, v)
}
|
slice
slice表示一个拥有相同类型元素的可变长度的序列,slice是一种轻量的数据结构, 可以用来访问数组的部分或者全部元素,而这个元素称为slice的底层数组, 这里先只学习slice的常用操作,slice 底层结构原理会单独记录.
现在可以简单这样理解: slice是底层数组的一层view.
**slice是由三部分组成: 第1个参数是指向底层数组的指针(ptr),这个指针指向真正存储数据的块, 第2个参数是长度(len), 第三个参数是容量(cap)
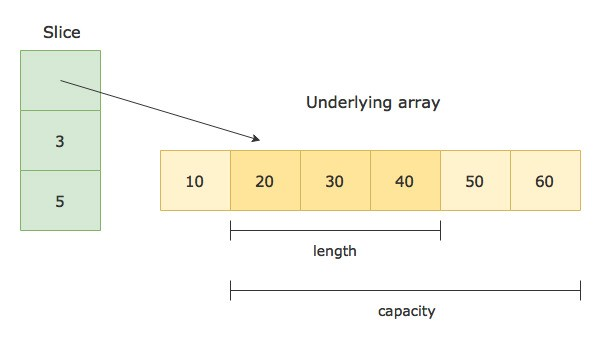
定义
1
2
3
4
5
6
|
var aSlice = []int{1, 2, 3}
bSlice := []string{"a", "b"}
cSlice := make([]int, 2, 10)
|
访问
1
2
3
4
|
aSlice = []int{1, 2, 3}
aSlice[0]
aSlice[10]
|
遍历
1
2
3
4
5
6
7
8
9
10
11
12
13
|
aSlice := []int{1, 2, 3}
l := len(aSlice)
for i := 0; i < l; i++ {
fmt.Println(aSlice[i])
}
for k, v := range aSlice {
fmt.Printf("k=%d, v=%d\n", k, v)
}
|
方法
1
2
3
4
| eSlice := [10]int{1, 2, 3, 4, 5}
hSlice := eSlice[:]
len(hSlice)
cap(hSlice)
|
Reslice
1
2
3
4
5
6
7
8
9
|
eSlice := [10]int{1, 2, 3, 4, 5}
fSlice := eSlice[2:4]
gSlice := fSlice[3]
gSlice := fSlice[1:5]
|
gSlice := fSlice[1:5]为何会输出[4 5 0 0 ]呢, gSlice的值为[3 4 ], 压根就没有[1: 5],那它为何没有提示越界访问呢?这个其实就是对slice是底层数组的一层view的说明
slice是支持向后扩展的, eSlice其实就是fSlice跟gSlice的底层数组, 只要不超过底层数组的cap,就可以反应在slice上,这也是fSlice[1:5]不报错的原因
fSlice[1:10]是由于gSlice本身有了2个元素, 整个只有8个元素,因此越界.
append
向slice追加元素的时候需要注意存在修改底层数组及扩容的问题.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
eSlice := [10]int{1, 2, 3, 4, 5}
hSlice := eSlice[3:5]
fmt.Println(eSlice, hSlice, len(hSlice), cap(hSlice))
fmt.Printf("%p\n", &hSlice)
iSlice := append(hSlice, 100)
fmt.Println(eSlice, iSlice)
fmt.Printf("%p\n", &iSlice)
hSlice = append(hSlice, 11, 12, 13, 14, 15, 16, 17, 18)
fmt.Println(eSlice, hSlice)
fmt.Printf("%p\n", &hSlice)
hSlice = append([]int{0}, hSlice...)
|
delete/insert/replace
1
2
3
4
5
6
7
8
9
|
hSlice := []int{0, 4, 5, 11, 12, 13, 14, 15, 16, 17, 18}
hSlice = append(hSlice[:2], hSlice[2+1:]...)
hSlice = append(hSlice[:3], append([]int{10}, hSlice[3:]...)...)
hSlice = append(hSlice[:3], append([]int{10}, hSlice[4:]...)...)
|
copy
内置函数 copy() 可以将一个数组切片复制到另一个数组切片中,如果加入的两个数组切片不一样大,就会按照其中较小的那个数组切片的元素个数进行复制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
hSlice := []int{4, 5, 11, 12, 13, 14, 15, 16, 17, 18}
jSlice := hSlice
hSlice[5] = 1000
fmt.Println(hSlice, jSlice)
fmt.Printf("%p, %p\n", &hSlice, &jSlice)
jSlice = append(jSlice, 20000)
fmt.Println(hSlice, jSlice)
fmt.Println(hSlice[10], jSlice[10])
hSlice := []int{4, 5, 11, 12, 13, 1000, 15, 16, 17, 18, 2000}
jSlice := make([]int, 1)
n := copy(jSlice, hSlice)
kSlice := make([]int, len(hSlice))
n := copy(jSlice, hSlice)
lSlice := make([]int, 15)
n := copy(jSlice, hSlice)
|
上面所有的例子都跟slice的底层数据结构有很大的关系, 后续会对slice底层原理写一个详文.
参考文章: