Kubernetes学习(service机制)
service在kubernetes是一个比较核心的概念, 得益于service机制,才让业务可以don’t care后端real pod的IP 可动态变化. 可以说,service是一组具有提供相同能力pod的代理.
在分析流量如何转发之前还是需要稍微带一下kubernetes的service基本概念
基本概念
- Service: 解决容器IP动态属性, 实为一个代理服务.
- Endpoint( Endpoint Controller): 是k8s集群中的一个资源对象,存储在etcd中,用来记录一个service对应的所有pod的访问地址
- 负责生成和维护所有endpoint对象的控制器
- 负责监听service和对应pod的变化
- 监听到service被删除,则删除和该service同名的endpoint对象
- 监听到新的service被创建,则根据新建service信息获取相关pod列表,然后创建对应endpoint对象
- 监听到service被更新,则根据更新后的service信息获取相关pod列表,然后更新对应endpoint对象
- 监听到pod事件,则更新对应的service的endpoint对象,将podIP记录到endpoint中
- Kube-proxy:
- kube-proxy负责service的实现,即实现了k8s内部从pod<==>service和外部从node port到service的访问。
- kube-proxy采用iptables的方式配置负载均衡,基于iptables的kube-proxy的主要职责包括两大块
- 一块是侦听service更新事件,并更新service相关的iptables规则,
- 一块是侦听endpoint更新事件,更新endpoint相关的iptables规则(如 KUBE-SVC-链中的规则),然后将包请求转入endpoint对应的Pod。
- 如果某个service尚没有Pod创建,那么针对此service的请求将会被drop掉
endpoint只是维护service到pod列表的映射关系,而这种映射关系的访问链路是通过 kube-proxy实现的.
目前业务中用到了以下几种svc.
服务类型
ClusterIP
这是最常用的一种svc, Yaml文件如下:
1 | apiVersion: v1 |
kubectl apply -f svc.yaml后, kubernetes会为这个svc分配一个clusterIP的地址, 地址的范围从kube-apiserver的参数service-cluster-ip-range获取.
ClusterIP因为是个虚IP(没有实际的网卡), 所以无法ping通,也无法单独使用,必须要跟端口一起使用
type默认为ClusterIP, 这种service只能在集群内部访问.
无label selector
这种场景一般用在服务搭建在kubernetes集群外,但是需要在集群内部访问(前提要网络可达)如数据库,中间件等.
Yaml文件如下:
1 |
|
由于consul服务是部署在集群外的, 所以这类的svc是不会自动创建endpoint对象(也就没法通过label选择后端应用),所以需要手工create endpoint对象, 使svc跟ep配对,这样,从svc进来的请求即会路由到consul服务.
ExternalName
这种场景一般用在服务搭建在kubernetes集群外,但是需要在集群内部访问(前提要网络可达).
ExternalName目的是构造一条dns记录,即通过svc访问的请求直接通过dns转发到目的服务.
Yaml文件如下:
1 |
|
服务发现
目前kubernetes支持两种服务发现: 环境变量, DNS
环境变量
通过在资源对象中注入环境变量的方式,使应用能够感知对端应用.
不推荐
DNS
LabelSelector机制解决对象的关联关系,而DNS机制则解决服务路由问题.
每个集群中都会部署dns服务,用于集群内部的域名解析.
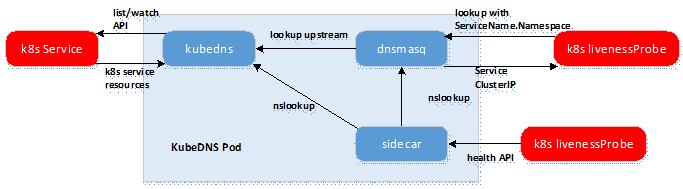
Kube-dns由3个容器组成:
kubedns:kubedns进程监视 Kubernetes master 中的 Service 和 Endpoint 的变化,并维护内存查找结构来服务DNS请求dnsmasq:dnsmasq容器添加 DNS 缓存以提高性能, 参数中指定upstream为kubednssidecar:sidecar容器在执行双重健康检查(针对 dnsmasq 和 kubedns)时提供单个健康检查端点(监听在10054端口)
kubernetes的新版本中,已经使用了coreDNS代替了kube-dns做为集群默认的dns, coredns在效率方面比kube-dns更高
具体dns如何做服务发现的呢?
每个node上运行的kube-proxy是实现service的载体,而kube-proxy则是创建一系列iptables规则实现代理
路由分析
为何在应用中使用nginx-deployment:8008就能够访问某个应用?
首先了解一下nginx-deployment
nginx-deployment在kubernetes集群中其实是个域名, 完整的域名应该是
nginx-deployment.default.svc.cluster.local
集群中所说的服务发现一般是对于service来说的, service的域名规则如下:
service-name.namespace.svc.cluster.local
集群在部署时会要求给定一个静态的ip做为dns服务对外暴露的ip(也是个ClusterIP, 不是真实的dns容器ip)
同时会定义好集群默认域名后缀: cluster.local, 默认地对于service类型的资源来说就是svc.cluster.local
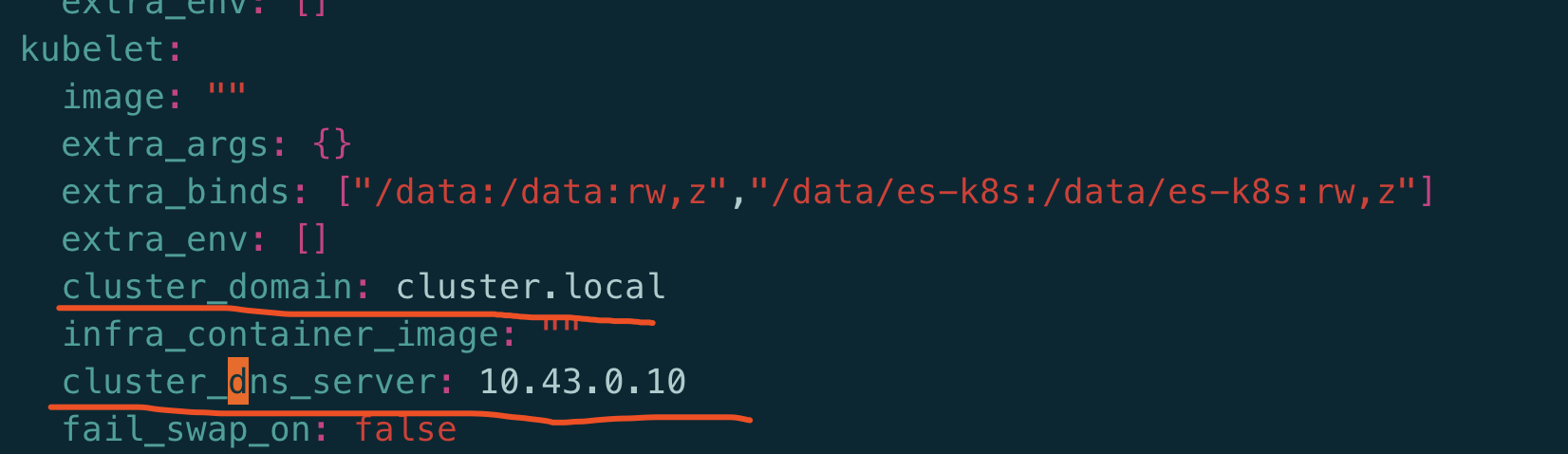
部署时会把这两个当成是kubelet的启动命令的参数传入, 这样每次有新pod的创建请求时都会把这两个参数传入pod中, 这样会把dns的ip写在容器/etc/resolv.conf

除了写了nameserver之外,还有search domain: 简单来讲就是通过这个列表把短域名拼接成完整域名的规则.
因此,如果调用对端服务的容器跟对端服务是在一个namespace时, 是可以不指定namespace
而如果是在不同的namespace时,则必须使用service-xxx.namespace-xxx的形式,不然无法找到改域名.
域名解析流程如下:
- 当我们在容器内部使用
nginx-deployment时,从/etc/resolv.conf文件内的规则被dns resolver拼接成了nginx-deployment.default.svc.cluster.local- 然后再将
nginx-deployment.default.svc.cluster.local交由10.96.0.10进行解析10.96.0.10将域名解析转到kube-dns容器, 因为kube-dns内缓存了所有service与ip的映射关系,返回service的ip, 这里是ClusterIP.
接下来的流程就是 ClusterIP如何将流量转向real pod了.
假设有如下的svc, nginx:
svc name: nginx-deployment.k8s-test.cluster.local
clusterIP: 10.108.141.150
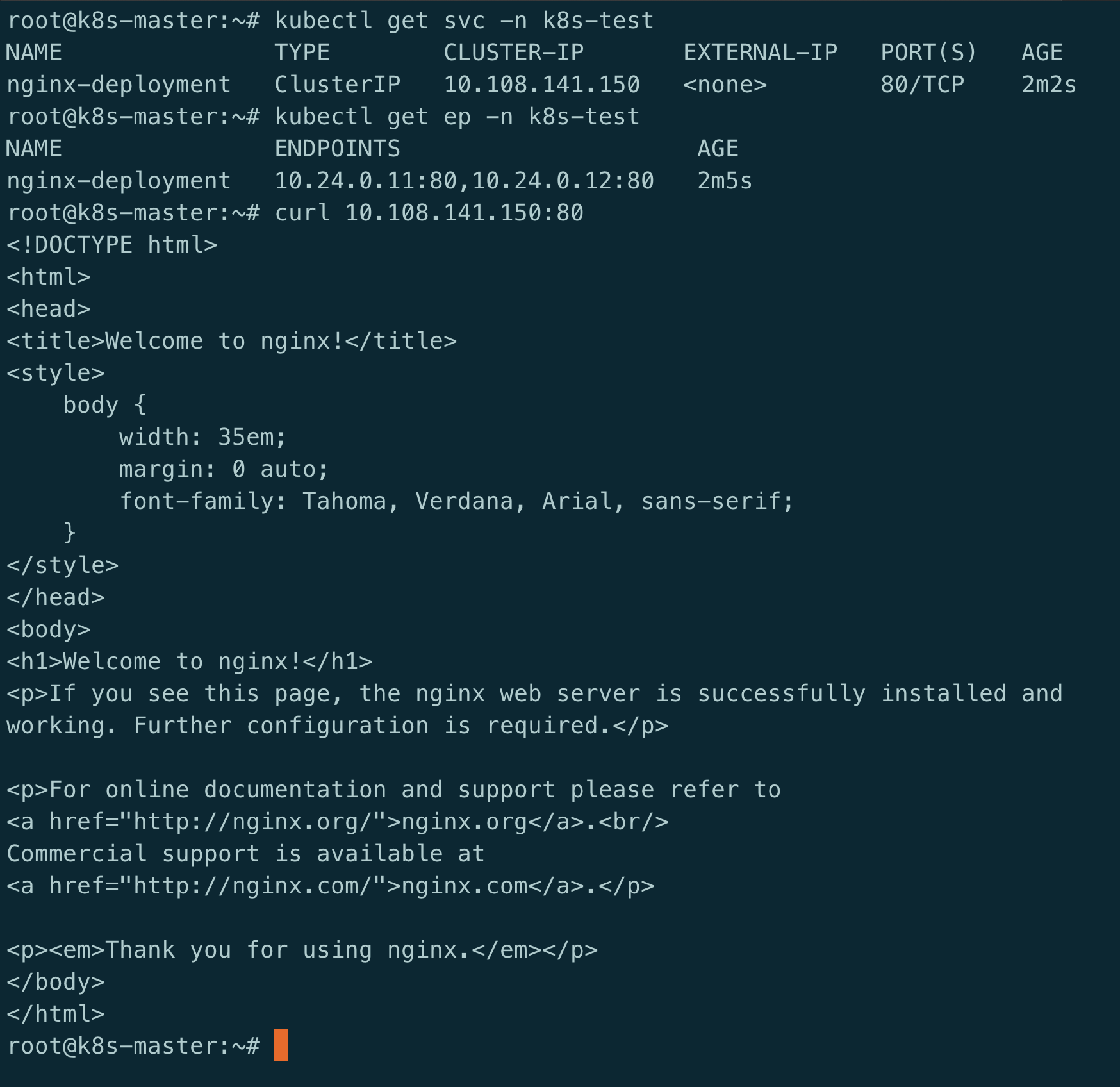
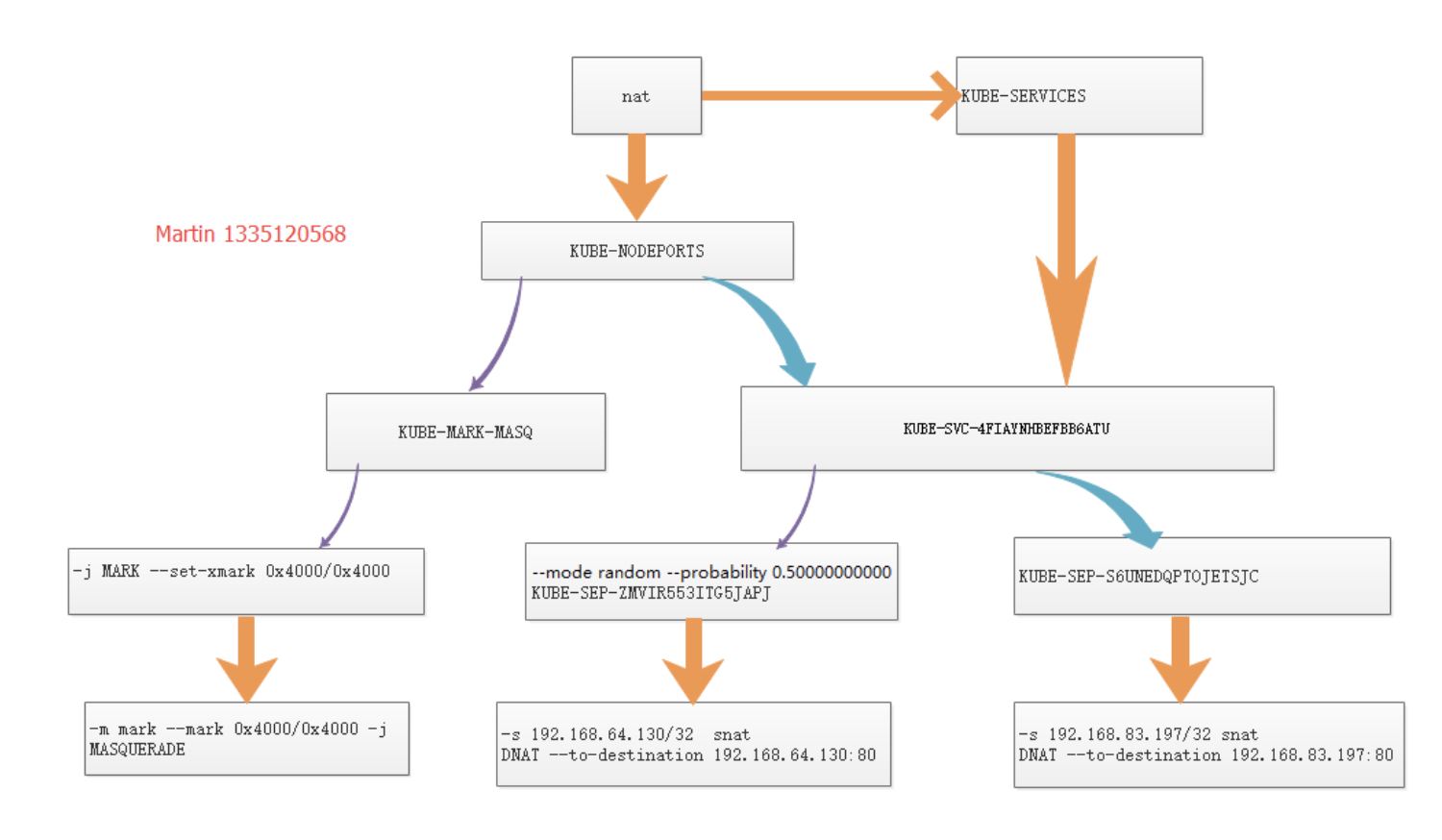
根据ClusterIP查看iptables规则(iptables系列讲解):

可以看到,目的地址为CLUSTER-IP、目的端口为80的数据包,会被转发到KUBE-MARK-MASQ与KUBE-SVC-Y7T6WNKYLXPYVSY3链上。
其中,KUBE-MARK-MASQ链的作用是给数据包打上特定的标记,以及后续对这些标记的数据做SNAT, 可以无视.
每个KUBE-SERVICES 说明是一条service, KUBE-SVC-xxx则是具体的svc规则.
重点来看下KUBE-SVC-Y7T6WNKYLXPYVSY3链:

从图中可以看到KUBE-SVC-Y7T6WNKYLXPYVSY3按照等概率地(--mode random --probability 0.500000000)把请求转发给KUBE-SEP-L665HS3BZVTLMHTG及KUBE-SEP-BWQQW4YACEFQQND7从这里也可以看到, 第一次转发的链名称是KUBE-SVC-xxx,第二次转发给具体pod的链名称是KUBE-SEP-xxx,这里的SEP实际指的是kubernetes的endpoint对象
看下SEP链:
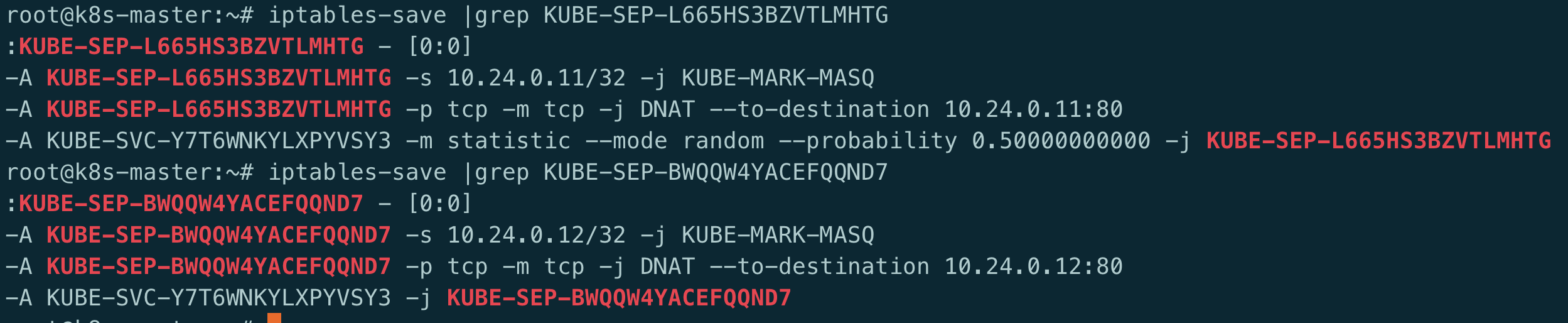
可以看到最终这两条规则转发到了CLusterIP后的某个pod的ip及端口上.
这样就完成了整个service name到readl pod的查找,后续如何将请求转发到pod内,这部分工作是由容器网络完成的,由于容器网络跟特定使用的组件有关,不同的容器网络机制大多不同,时间关系,这里不展开讨论.
Service默认是轮询选择后端, 到达kube-proxy则是使用–mode random –probability来设置pod承载的流量
我们也可以在service中指定会话保持.让同一个client的请求访问同一个backend. 只需要在service YAML中指即可,路由规则与上述原理类似.
1 | sessionAffinity: ClientIP |
网上抄图总结一下: