CockRoachDB学习(架构)
项目中需要一个分布式数据库用于存储业务的KV数据, 在前期项目调研结合业务比对了业界常用的KV数据库模型后, 最后选择了CockRoachDB(CRDB).
选择CRDB主要基于以下几点考虑:
- 目前项目的主要开发语言为Golang,而CRDB就是Golang实现的
- 分布式, 高开发、高性能、高可用
- 运维成本简单,上手容易
CRDB开源以来, 业界很多大公司都在用, 百度还将CRDB的技术文档进行了翻译, 有兴趣的可以看这里
目前CRDB的源码托管在github上
CRDB特性
CockroachDB is a distributed SQL database. The primary design goals are scalability, strong consistency and survivability (hence the name). CockroachDB aims to tolerate disk, machine, rack, and even datacenter failures with minimal latency disruption and no manual intervention. CockroachDB nodes are symmetric; a design goal is homogeneous deployment (one binary) with minimal configuration and no required external dependencies.
CockroachDB是一个分布式的数据库,主要设计目标是可扩展,强一致和高可用 。CockroachDB旨在无人为干预情况下,以极短的中断时间容忍磁盘、主机、机架甚至整个数据中心的故障 。 CockroachDB采用完全去中心化架构,集群中各个节点的地位完全对等,同时所有功能封装在一个二进制文件中,可以做到尽量不依赖配置文件直接部署
从这段官文可以看到几个很显眼的字段: 分布式、可扩展、强一致、高可靠、去中心化、不依赖
从这些字眼来看,完全符合项目需要,但是也需要认真地学习下CRDB的原理
分布式
现在搞个数据库, 不做成分布式都不好意思了, 这个没啥好说的.
可扩展
CRDB支持横向地增加节点到集群中来提升整个集群的存储容量, 理论上最大可以支撑4EB的数据存储, 理论上单集群支持10K节点规模,节点之间通过Gossip协议来同步状态.
查询以分布式任务的方式在各个数据节点并发执行,可以通过增加节点数来提升单个查询的性能
强一致性
CRDB Range的副本数据同步是基于Raft协议来保证强一致性的, 所有一致性状态都存储在RocksDB中
对range内的数据所做的任何更改都依赖于一致性算法,以确保其大多数副本同意提交后才能返回给客户端,.
当写入未达成共识时,转发程序将停止以保持集群内的一致性
副本同步复制跟异常复制:
同步复制要求所有写入传播到法定数量的数据副本之后,才能提交。 为了确保与数据的一致性,这是CockroachDB使用的复制类型
异步复制只需要一个节点来接收写入来被认为已提交; 之后它会传播到每个数据副本。 这或多或少等同于NoSQL数据库推广的“最终一致性”。 这种复制方法可能会导致异常和数据丢失
高可用
将Range副本分布在一个数据中心,可以确保低延迟复制,同时能容忍磁盘或机器故障。如果将副本分布在不同机架,即使某些网络交换机故障,CockroachDB仍可提供服务
Range副本可以跨数据中心和跨地域分布,以应对来自数据中心电源中断或网络中断,以及区域电力故障等问题
例如,一个Range包含三个副本,每个副本可以位于不同的位置:
- 如果副本分布于同一台服务器上的多块磁盘,可以容忍单块磁盘故障。
- 如果副本分布于同一机架上的不同服务器,可以容忍单台服务器故障。
- 如果副本分布于同一个数据中心不同机架,可以容忍单个机架电源和网络故障。
- 如果副本分布于不同数据中心,可以容忍大规模网络中断或断电。
N为总副本数,F为可容忍故障副本数,则N=2F+1。(例如,三副本可以容忍一个副本故障,五副本则可以容忍两个副本故障,以此类推)
去中心化
集群中所有的节点角色都是对等的, 客户端的查询请求可以发送到集群任意节点,且每个查询可独立并发执行(无论有无冲突),意味着集群的吞吐能力可以随着节点数的增加线性提升.
如果一个节点接收到一个它无法直接服务的读或写请求,它会找到能够处理该请求的节点,并与它进行通信。这样你不需要知道数据位于哪里,CockroachDB会为你跟踪数据,并为每个节点启用对称行为(symmetric behavior)
不依赖
CRDB所有功能都在一个编译好的二进制中, 不需要依赖其它组件, 运维部署都非常方便.
高性能
CRDB单集群支持10K节点的规模, 能够存储的数据最大为4EB, 性能可谓是强悍, 当然一般业务很难达到这个规模.
当然CRDB由于支持强一致性又想要高性能, 架构设计自然是花费了很多功夫, 这个就是后话了.
CRDB术语
了解CRDB之前, 需要了解下CRDB里常见的几个术语
| 术语 | 定义 |
|---|---|
| Cluster(集群) | 你部署的CockroachDB集群,它包含一个或多个数据库,对外则像一个逻辑应用程序一样提供服务。 |
| Node(节点) | 运行CockroachDB的单个机器。 许多节点连接在一起以创建你的集群。 |
| Store (存储) | 真正KV数据的存储,一个节点可以启用多个Store, 一个Store包含多个Range. |
| Range (数据分片) | 集群中一组连续的已排序的数据,每个Range分片默认为64M。 |
| Replicas(副本) | range的副本,存储在至少3个节点上,以确保可用性。 |
| Range Lease(range租约) | 对于每个range,其中的一个replicas持有“range lease“,该replicas(称为leaseholder)是接收和协调该range的所有读写请求的replicas |
看多了这种分布式数据库你会发现, 每种数据库都有自己的各种概念, 其实原理上很相近
CRDB架构
分层架构图
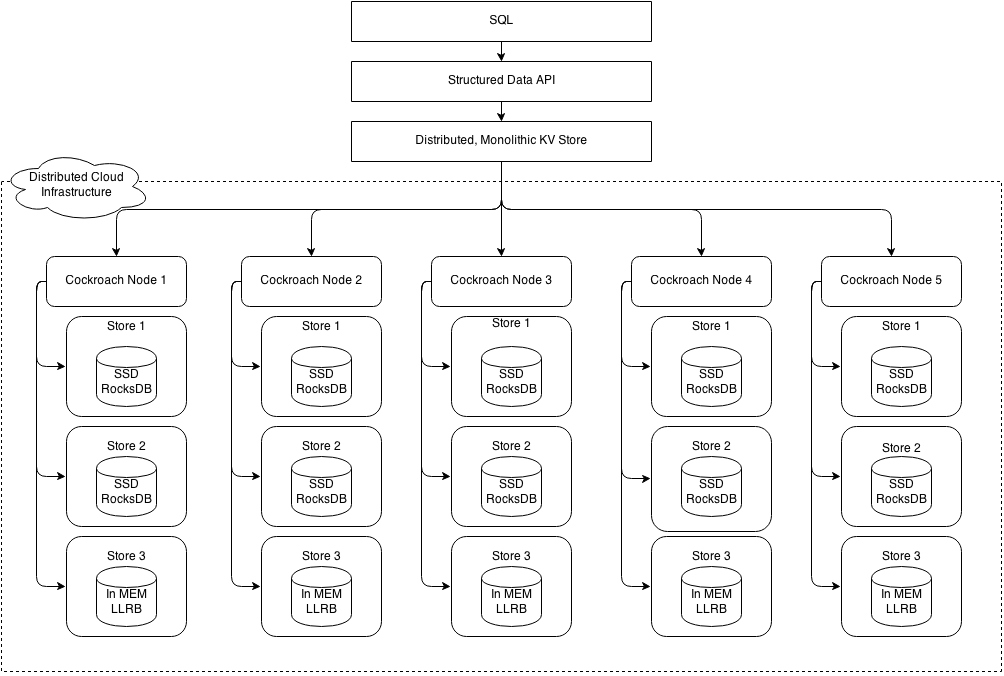
CRDB的分为以下几层,这些层直接与在它上面和下面的层交互,提供相对不透明的服务,详细可看这里
| 层 | 顺序 | 目的 |
|---|---|---|
| SQL | 1 | 将客户端SQL查询转换为KV操作。 |
| Transactional | 2 | 允许对多个KV条目进行原子性改变。 |
| Distribution | 3 | 将复制的KV range作为单个实体。 |
| Replication | 4 | 跨越多节点的一致性和同步复制KV range。此层还允许通过租约实现一致的读取。 |
| Storage | 5 | 在磁盘上写入和读取KV数据 |
CRDB做为一个数据库, 其实也是分层的结构,在最上层是提供给使用人员的是SQL层, 使用人员可直接使用如Mysql数据库一样的sql语句结构来操作CRDB
CRDB本质是个KV数据库, 那直接也存在从SQL –> KV的转换, 这一系列操作由SQL层进行处理, 既然CRDB是个数据库, 那自然也少不了比如SQL语句的解析、执行计划、执行器等一系列过程, 具体过程可查看这里
Store架构图
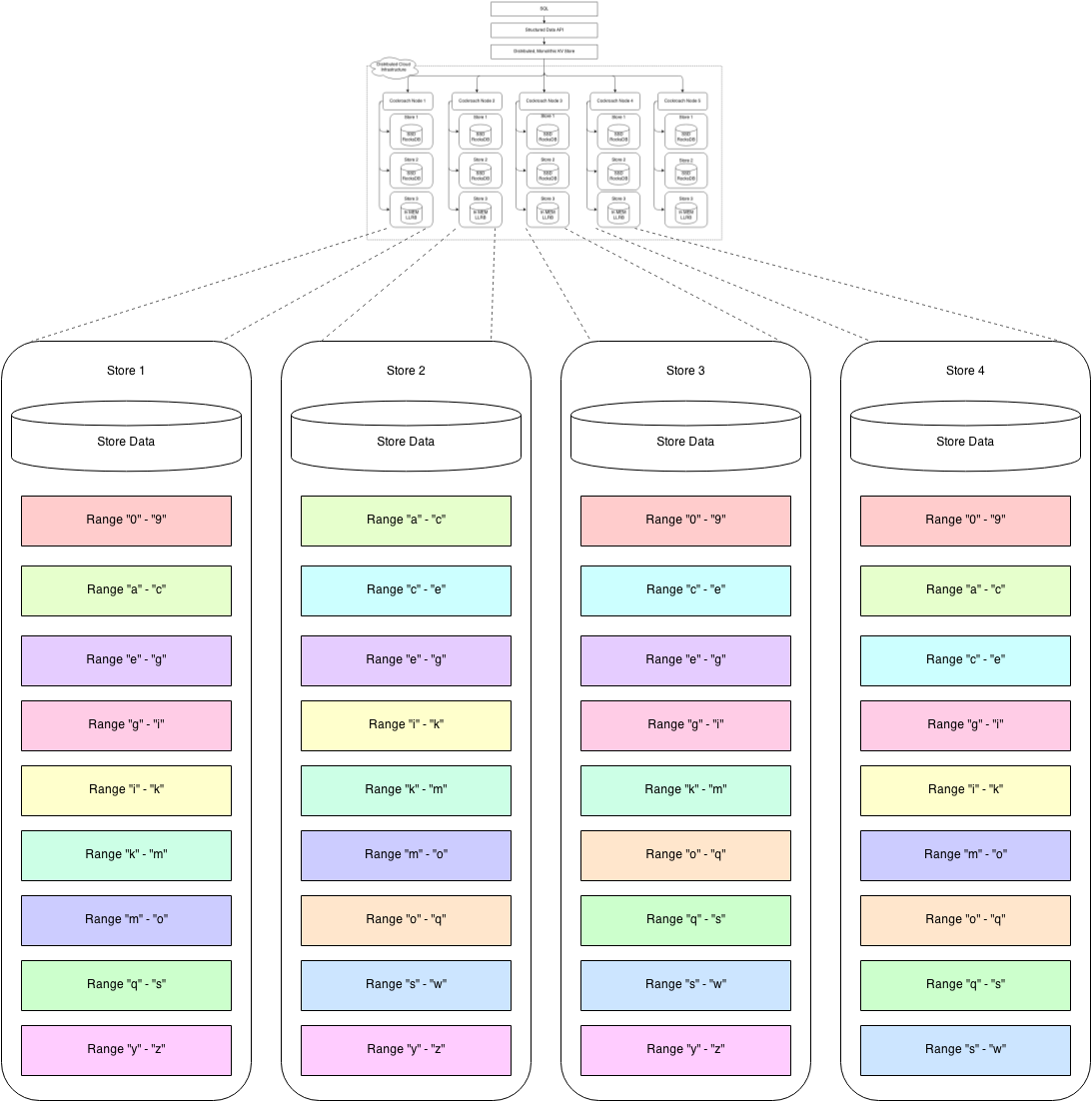
每个Store包含多个Range,Range为KV层数据管理的最小单元,每个Range的多个副本之间使用Raft协议进行同步。如下图所示,每个Range有3个副本,同一Range的副本用相同颜色标识,副本之间使用Raft协议同步