Prometheus学习(Prometheus基于kubernetes做服务发现)
之前学习了prometheus的架构及一些基本术语, 今天学习一下Prometheus的服务发现机制,这块的内容占据比较大的份额, 主要学习下基于kubernetes做服务发现.
服务发现
由于是opnuPrometheus的服务发现的, 但服务发现这个词不应该放到里详细地展开说它是个什么东西,
大家可以想像下DNS的机制,它就是一种服务发现方法. 详解地可参考这里
随着kubernetes被光放地用于在微服务架构下, 错综复杂的服务间调用使得对服务发现机制越来越重要,
当然, 存在服务发现那必然就有服务注册,好在kubernetes本身做了这些事情, 使得我们可以更加专注于业务.
可以有很多种方式实现服务发现, 最早使用的DNS其实就是一种,
在prometheus的官网上, 列出了目前支持的服务发现方式,图中的sd表示的 service discovery, 这里了解下最kubernetes跟file这种方式
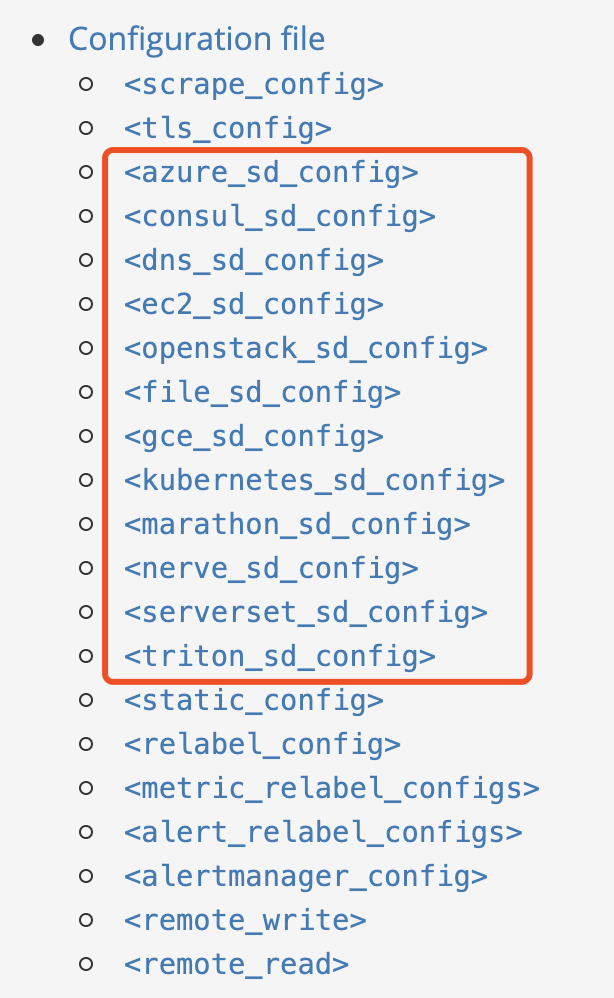
static_config
最简单的是静态配置, 这种也权当是一种服务发现吧, 就是直接在prometheus配置中直接指定需要抓取的目标
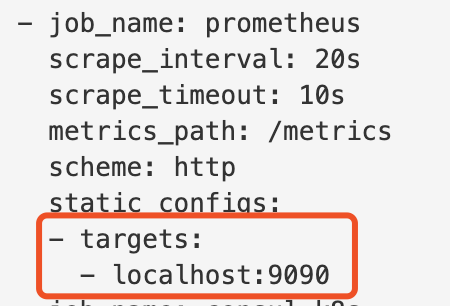
像上图那样直接在target中指定目标地址即可, 非常简单
file_sd_config
基于文件的服务发现, 可以理解通过解析文件的方式获取目标, 这种方式跟static_config差不太多
这种方式的有点是可以根据业务进行分类, 而不用全都塞到一个配置文件中,当这个yaml或者json文件内容有改变的时候,prometheus 会通过watch file的形式感知到target内容的变动
1 | - job_name: 'test_server' |
1 | cat test_server.json |
文件支持通配规则.
kubernetes_sd_config
要理解prometheus如何基于kubernetes做服务发现这个问题, 那么就需要理解kubernetes是如何做服务发现的.
这里一句话总结就是,kubernetes的服务发现机制是基于dns的,所有的service都注册到api-server最终存储到etcd中,任何组件想要访问其它服务的话都需要从api-server中获取, 因此etcd中存储有所有元数据
因此, prometheus要发现kubernetes中的服务, 只需要通过list-watch机制从api-server中获取即可, 当然获取之后prometheus是会缓存在自己的内存中.
从上面能看到prometheus知道从kube-api中获取服务, 但怎么知道具体哪些服务是真正需要获取的, 一个kubernetes集群中可能存在上千个服务, 难道所有的服务都需要吗?显然不是.
在学习使用prometheus的时候,有同学看到prometheus的配置文件时肯定会疑惑, 而且整个配置文件中对kubernetes的部分占了大半部分,这里挑监控pod的部分简单说下, 先来看下配置文件
1 | - job_name: kubernetes-pods |
这个配置文件可在这里看到,至于上面的配置文件的含义, 网上已经有人解释了,这里就不多说,感兴趣的可以看看这里
这里要说的是, 按照上面的理解, 我一定是需要指定target才行, 但是上面这段配置并没有target字段, 那又是为何呢?
秘密就在于role: pod,上面已经标注出来, 在prometheus的源码中, 可以看到对pod的具体处理
从prometheus的源码中也可以看到对kubernetes支持的role共有endpoints,ingress,node,pod,service

所以,如果role 等于其它的值是没有用的, 因此在整个prometheus的配置文件中对于Kubernetes的配置只会有上面那5种role, 可以少, 比如我集群中没有ingress, 那么是可以没有ingress的配置的
所以总结一下, prometheus通过list-watch机制来更新上面指定role资源
那另一个问题是, 对于上面pod的配置,难道所有的pod对象都会prometheus抓取吗?显然也不是的
如果kubernetes集群到达一个数据级, 全部的pod都scrape的话,那对prometheus跟kubernetes的性能都是个巨大考验, 而且一般情况下,我们只会关心想关心的应用pod,另一此不是很重要的pod其实是可以不监控的。
因此prometheus通过annotations的方式,指定哪些需要需要scrape, 哪些可以忽略.
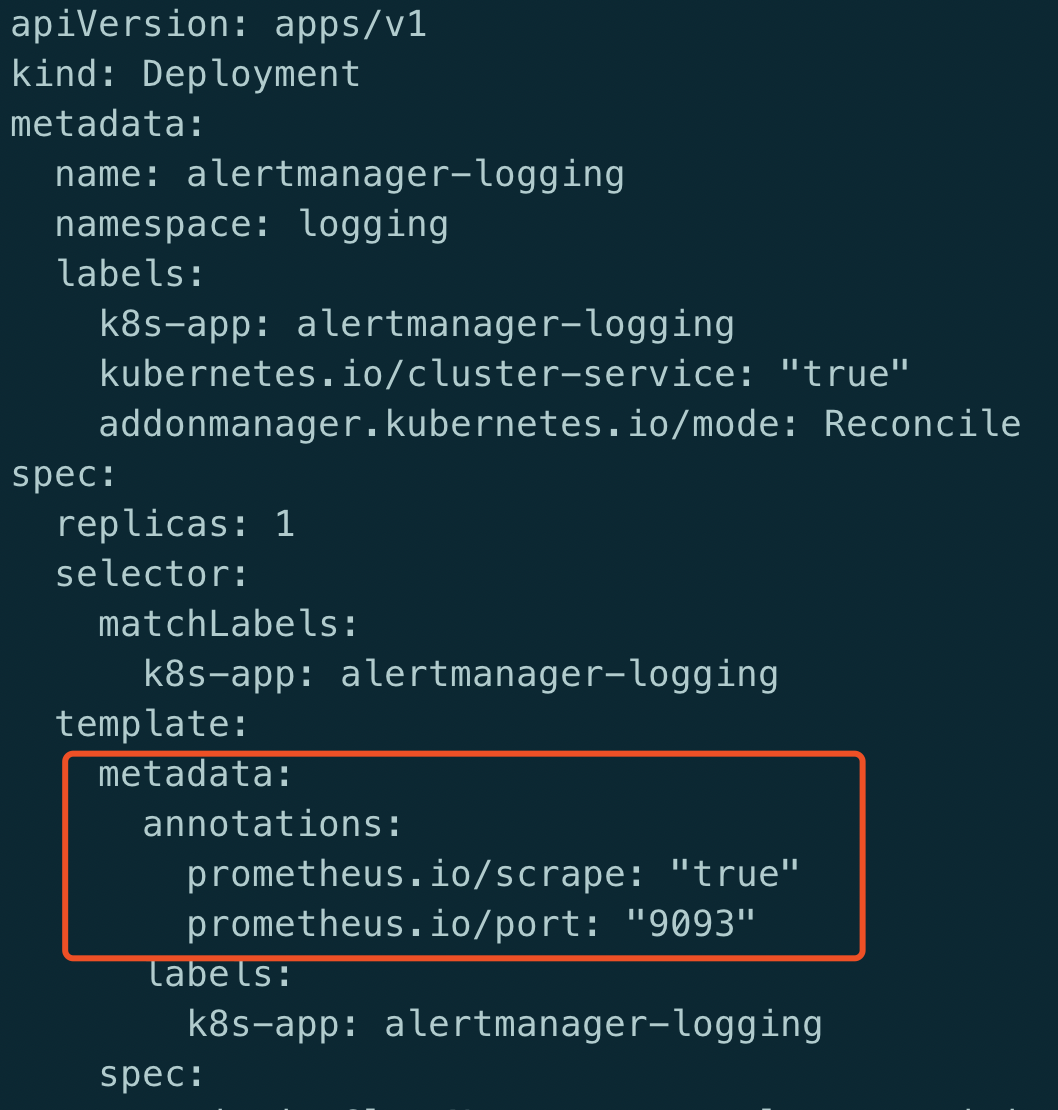
prometheus.io/scrape: 如果加上这个annotations,表示当前pod是允许prometheus抓取数据的,如不加这个annotations,prometheus就不会自动把这个pod纳入到监控中, scrape=true:允许抓取;scrape=flase:不允许抓取
prometheus.io/port: 抓取数据时使用的套接字端口, 这个端口用于暴露metric
prometheus.io/path: 当scrape=true时,再加此annotation,表示当前Pod能够输出指标数据的Url,默认为/metrics
因此, 整个annotations的完整url为 http://alertmanager-logging:9093/metrics
prometheus通过这种方式来决定哪些pod才是真正需要监控target, 同理其它role也是如此.
peometheus定时抓取target后将metrics数据存在在storge中
到此, 整个prometheus的服务发现target的流程就完了, 这里没有过多的介绍源码层面上的东西,网上有大神写的是感觉好, 大家有兴趣的话可以参考这篇
参考文章:
- https://xumc.github.io/blog/2018/09/02/promethues-discover
- https://xumc.github.io/blog/2018/09/12/promethues-scrape-source-lookup
- https://www.jianshu.com/p/1bf9a46efe7a
- https://prometheus.io/docs/prometheus/latest/configuration/configuration/
- https://blog.csdn.net/u010278923/article/details/70943506
- https://github.com/prometheus/prometheus/blob/master/documentation/examples/prometheus-kubernetes.yml