Grafana学习(在Grafana中统计物理机上容器状态分类汇总)
Kubernetes集群中的容器监控数据已经通过Prometheus采集上来,在Grafana上配置可视化的时候,发现了个很有意思的需求,即:按物理机展示各种状态下的容器占比情况
当然,是可以在Prometheus采集的时候对原始数据进行relabel,因为不好再回去做调整, 目前采集上来的数据不能直接实现上面的需求,所以只能在Prometheus上用提供的函数对数据做各种操作,最终达到效果,因为grafana直接支持prom语法,所以可以直接对prometheus的数据做sql.
展示需求
按物理机展示各种状态下的容器占比
最终要实现的效果如下:
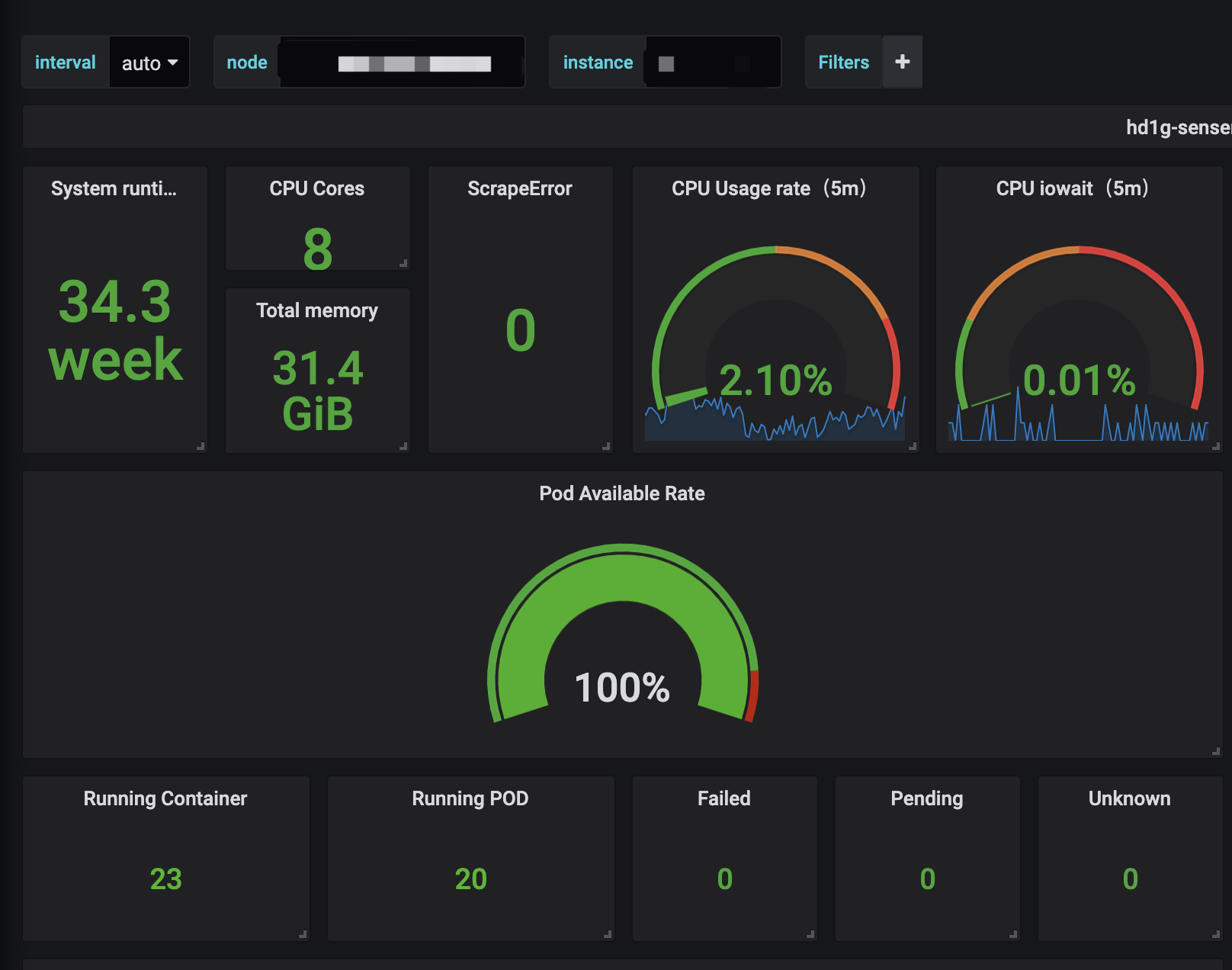
说明: 这里运行的容器数跟pod数不不一致是因为运行的容器数中包含静态pod, 所以会比pod数多.
Grafana完整语句
这里的语句跟Prometheus采集到的原始数据有很大的关系, 我只是想记录下grafana的几个比较有用的语法, 所以可能这个语句没有很大的参考性.
grafana中实现以上的效果,完整的语句如下:
1 | (sum by(node)(avg by(node,pod)(kube_pod_info{node=~"hd1g-senserealty-k8s-1"}) * on(pod) group_right(node) kube_pod_status_phase{phase="Running"}) ) |
下面进行这个语句的拆解, 主要使用到了3个promql语法,所以分为3部分来看
- avg by(node,pod)(kube_pod_info{node=~”hd1g-senserealty-k8s-1”})
- * on(pod) group_right
- Sum by
语句解析
avg by
avg by 这个语法跟常用的数据库里的语法一样,以node,pod为纬度统计出现的次数

on(xx) group_right|group_left
group_left(node)/group_right(node) 一般使用在一对多或者多对一的情况,指的是一侧的结果中的每一个向量元素可以与另一侧的多个元素匹配的情况,哪一边的向量具有更高的基数,说是如果右侧的对应多的一方,则使用group_right, 左边多则对应 group_left,Node对应label, 这个label是两边都必须具有的。
上面这个例子 kube_pod_status_phase 中并没有node这个label,所有无法使用group语句进行match, 因此需要使用label_replace添加一个node这样的label
on(pod)则表示当表1以node label映射到表2时,从映射结果中再以pod为key label,从下面的映射结果已经把 node label加到结果了.
(除了on, 还可以使用ignoring(xxx), 即除了这些lable,用剩下的labal为key)
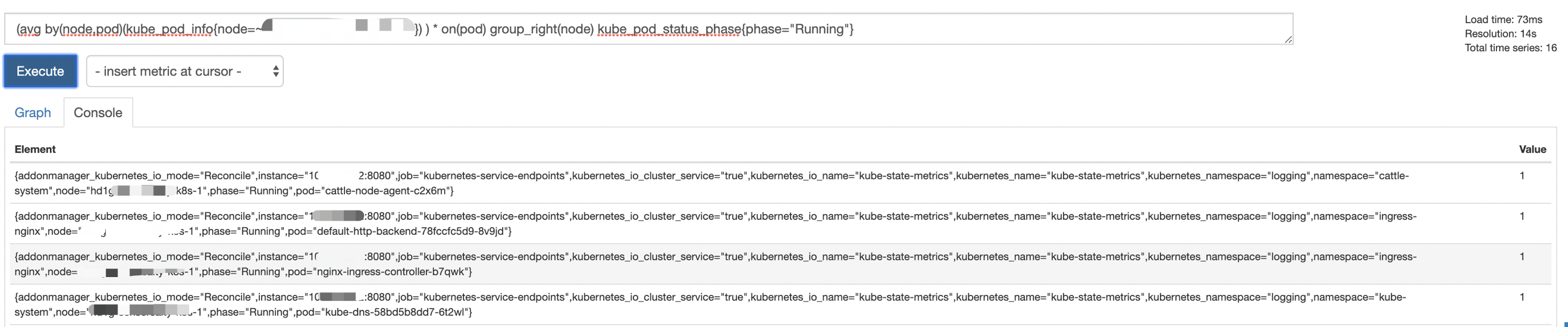
sum by
最后再以node为纬度进行sum

最终即能实现想要的效果了, 这里再说下label_replace这个函数,还是挺有用的
label_replace
1 | #label_replace用于添加/覆盖label |
比如,table的原始数据是这样

如果我想添加一个上面没有的的叫node的label,这个时候就需要使用label_replace
1 | label_replace(kubelet_running_pod_count,"node", "$1", "kubernetes_io_hostname","(.*)") |
添加一个node label

覆盖label

这里把instance给覆盖了,做打码处理了