Prometheus学习(prometheus基本原理)
Prometheus做为CNCF的第二个项目,被给予厚望, 现已然成为监控系统设计的标杆. 特别是对于Kubernetes的支持,可谓天衣无缝. 使用kubernetes,很难跳过prometheus不说.
系统架构
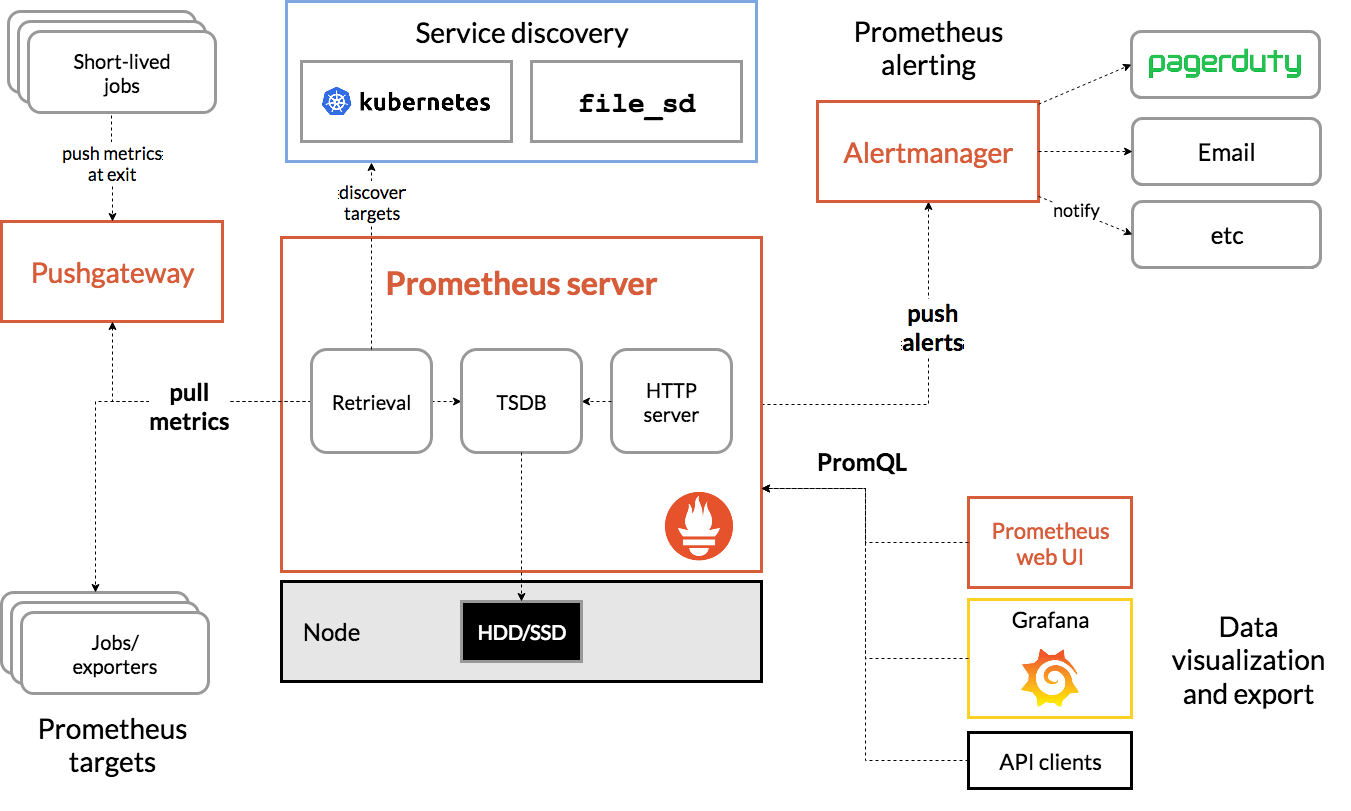
Prometheus由多个组件组成,但是其中许多组件是可选的:
- Prometheus Server: 用于抓取指标、存储时间序列数据
- Service discovery: 通过服务发现机制获取需要scrape目标
- Pushgateway: push的方式将指标数据推送到网关
- alertmanager: 处理报警的报警组件
- DataVisualization: 支持多种数据可视化UI
- PromQL: 数据查询语言
数据抓取
PULL: prometheus主动地按照配置的时间周期去需要抓取的目标对象获取metrics
PUSH: 程序按照配置的时间周期将metrics推送到pushgateway, pushgateway本地存储数据, prometheus主动去pushgateway抓取.
规则:
- 按照promethus定义的metric数据类型及规则组织数据格式.
- 暴露指定的端口供prometheus scrape且表明自己需要被scrape
metrics: key-value对
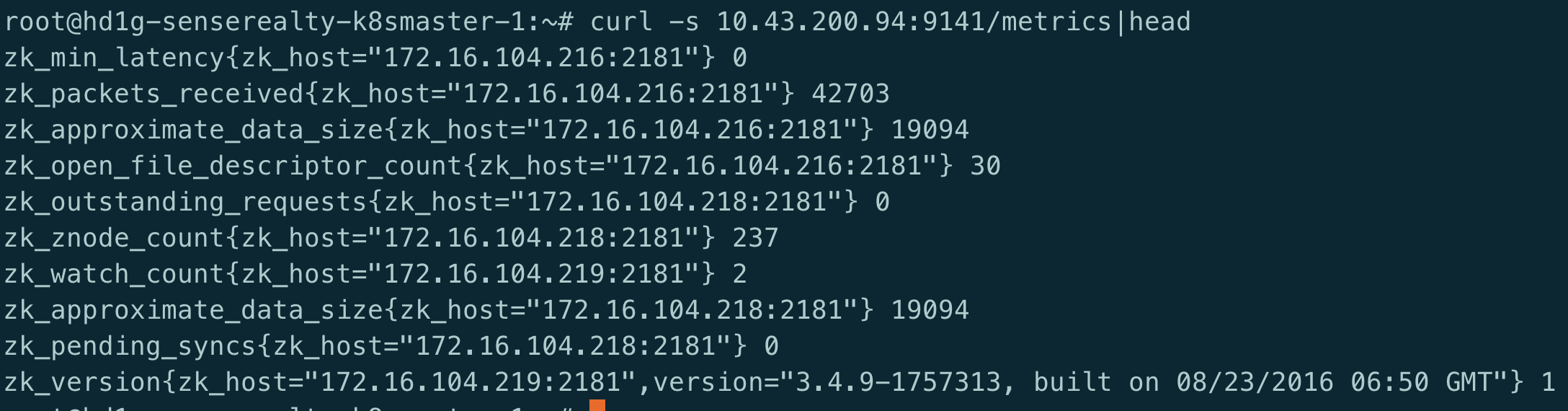
一条metrics中{}引起来的部分为label, 可用于聚合/查询条件等.
数据类型:
- counter: 只增不减,允许重置为0
- gauge: 没有规律的数值
- histogram: 用于统计一些数据分布的情况,用于计算在一定范围内的分布情况,同时还提供了度量指标值的总和
- Summary: 主要用于计算在一定时间窗口范围内度量指标对象的总数以及所有对量指标值的总和,计算过程是在client端完成,计算结果存在server。因为没有最初的metric数据,所以summary不支持数据聚合
scrape
对于scrape, 一个比较重要的指标是scrape timeout, 这个要根据具体场景来设置,过大或者过小都可能造成问题
关于如何发现scrape目标, 见ServiceDiscovery
PromSQL
prometheus中查询中使用了自有的查询语言,PromSQL,时间关系, 这节也不展开讲了,大家可参考官网
exporter
exporter是prometheus一类数据采集组件的总称, 随着prometheus逐渐流行, 并不是所有的第三方软件都支持prometheus的metric格式, 如果本身不改造的话,那无法使用prometheus进行scrapek,因此需要额外的一个东西从目标处收集数据, 将其转化为prometheus支持的格式.
服务发现
所有的监控对象(基础设施、应用、服务)都在动态的变化, 显然无法静态的定义监控目标。而对于Prometheus而言其解决方案就是引入一个中间的代理人(服务注册中心),这个代理人掌握着当前所有监控目标的访问信息,Prometheus只需要向这个代理人询问有哪些监控目标控即可, 这种模式被称为服务发现
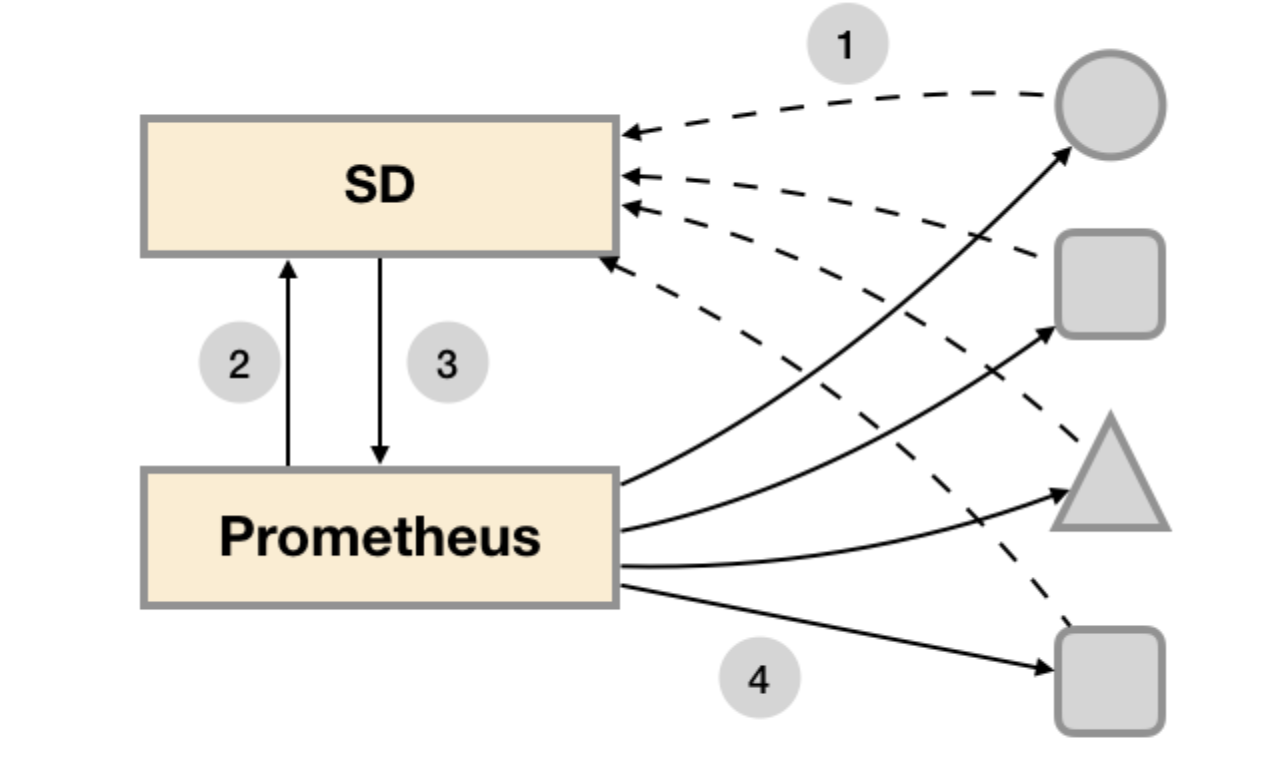
摘取prometheus配置文件部分, 完整的配置见官网:
1 | global: |
对应的service主动expose metrics:
1 | kind: Service |
一般情况下, 为避免抓取数据量太大对prometheus造成压力, 最佳实践是只抓取对监控有益的对象,
prometheus配置文件中对指定某组目标使用了relabel_configs
1 | source_labels: __meta_kubernetes_service_annotation_prometheus_io_scrape |
该场景下: 只有当prometheus能通过服务发现机制找到抓取对象且抓取对象定义了prometheus.io/scrape: "true"时, prometheus才会进行抓取.
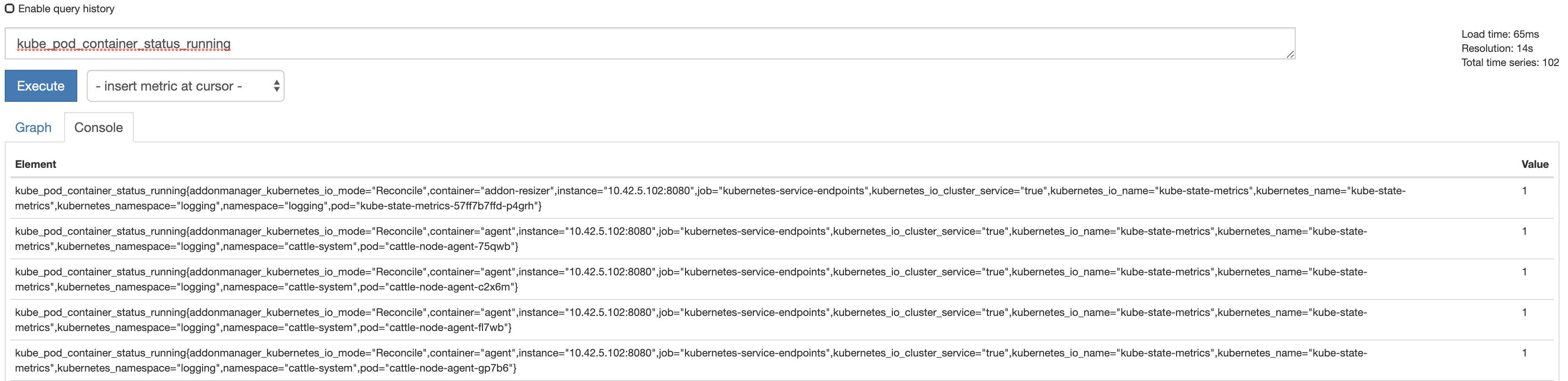
抓取的数据格式如下:
报警规则
这里举两个例子:
连续5分钟之内, 如果存在容器的启动时间一直小于180s的,则认为容器发生重启,则报警
1 | alert: container_restart |
连续5分钟之内,如果node的可用使用内存大于90%且可用内存小于2G的, 则报警
1 | alert: node_memory_usage_higher_0.9 |
报警管理
prometheus中处理metric是否符合定义的报警规则,然后通过alertmanager组件实现了, alertmanager充当中间人,后端对接多种报警介质
prometheus将异常事件发送给alertmanager, alertmanager中我们可以设置各种报警规则等
- 报警静默
- 报警抑制
- 报警分类
- 报警聚合
alertmanager的使用也相对容器, 不过Prometheus原生不支持某些实用的功能, 比如最大报警次数,因此, 如果产生报警, 如果不处理的话, prometheus会一直产生报警, prometheus开发者认为既然产生报警,那必然要尽快解决,因此觉得没必要支持设置最大报警次数,不过,可以直接通过修改prometheus的源码定制该功能.
###可视化
prometheus/alertmanager自带的webui实在是太过于丑陋, 一般只用于debug数据时使用, 数据可视化都会结合grafana进行展示
grafana支持alertmanager.