FELK学习(解决Unassigned shard)
在使用es时,如果集群的参数配置跟node节点数之间的关系没有处理好就有可能出现集群的status为yellow,下面就处理一种常见的unassigned shard的问题.
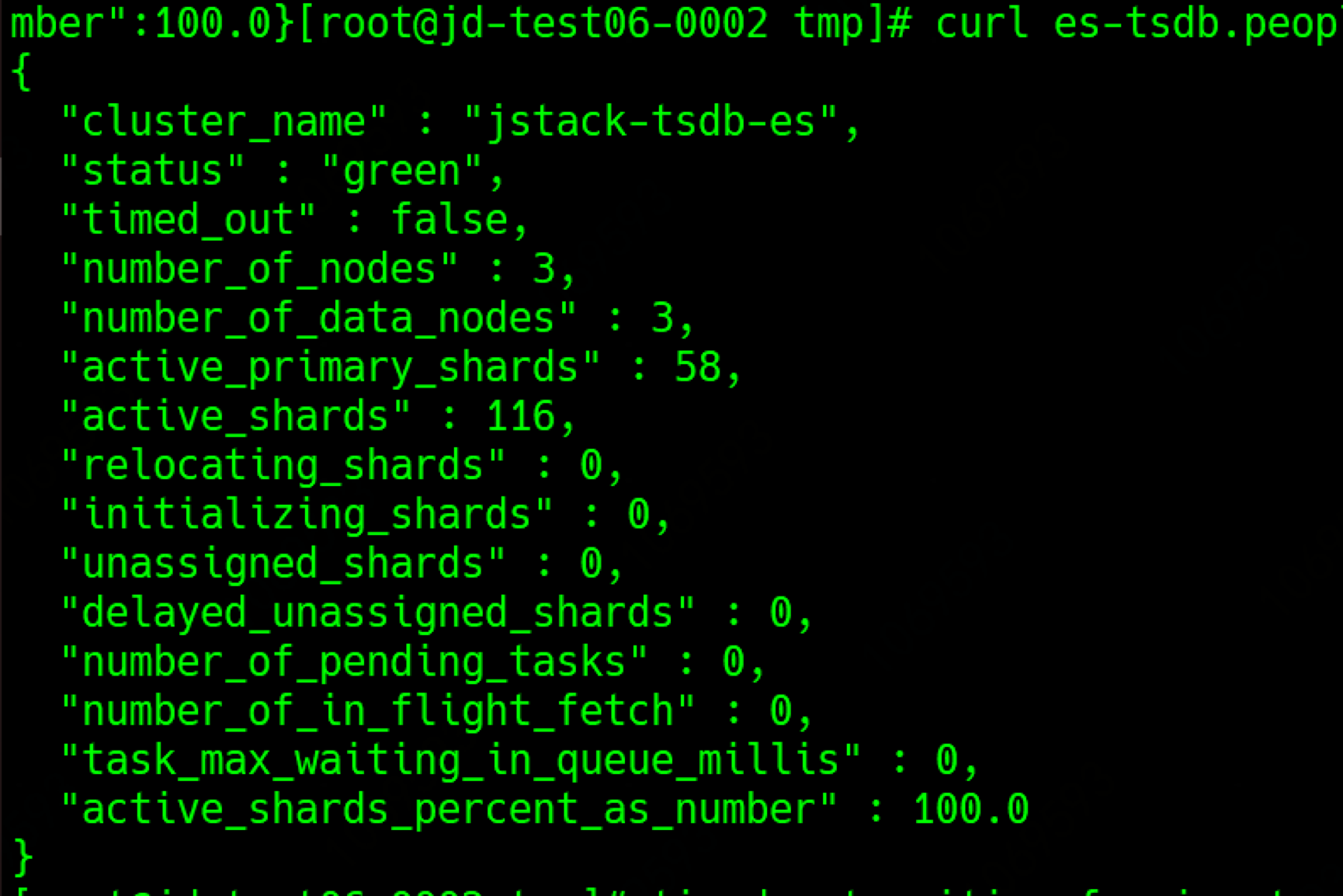
查看集群状态
1 | curl es-logstore.people.local/_cluster/health?pretty |
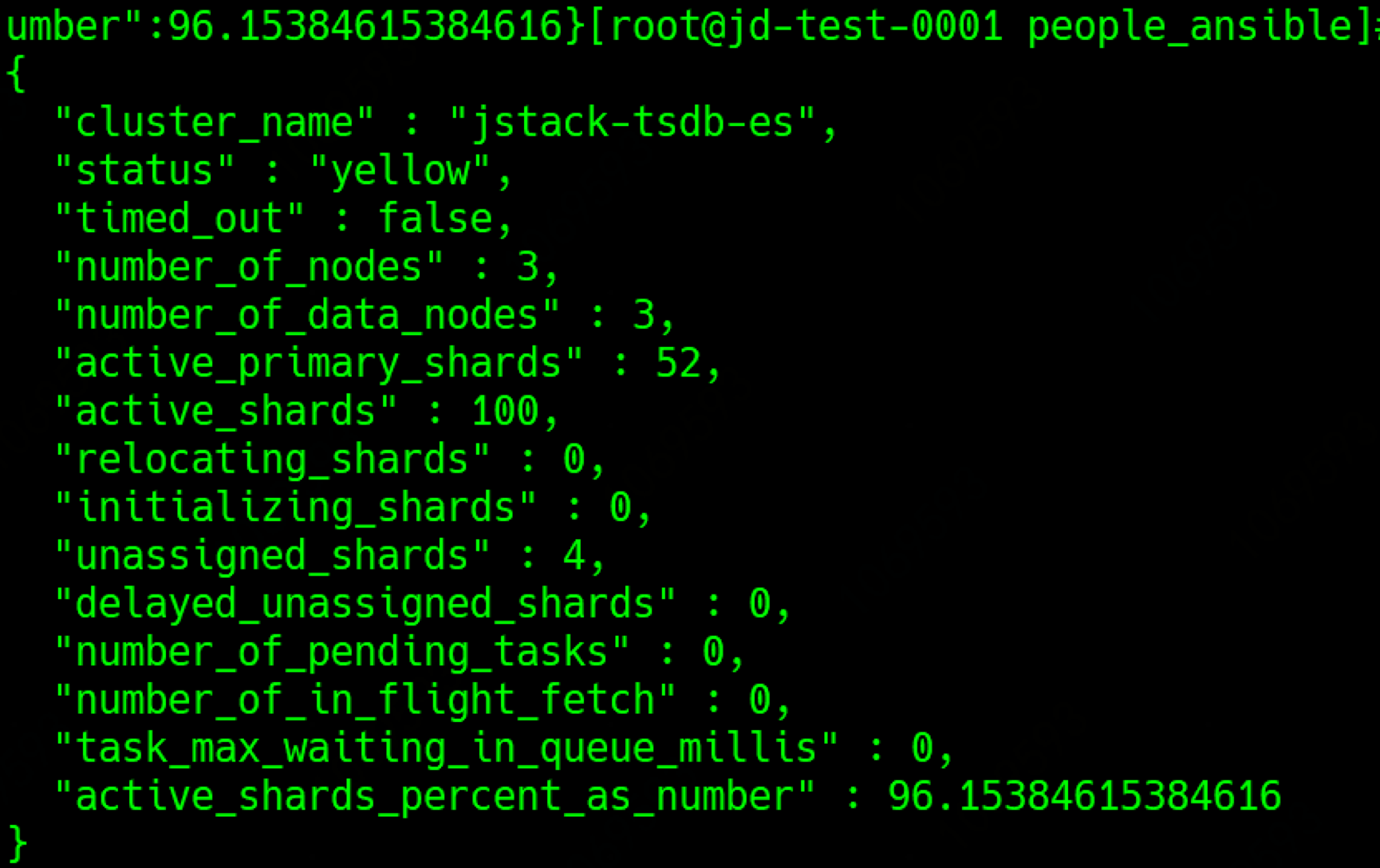
可以看到集群的状态为yellow, 从es集群的三大状态(Red, Yellow, Green)来看,yellow状态说明有索引的副本缺失
查询索引确实发现有索引状态为yellow
1 | curl es-tsdb.people.local/_cat/indices |
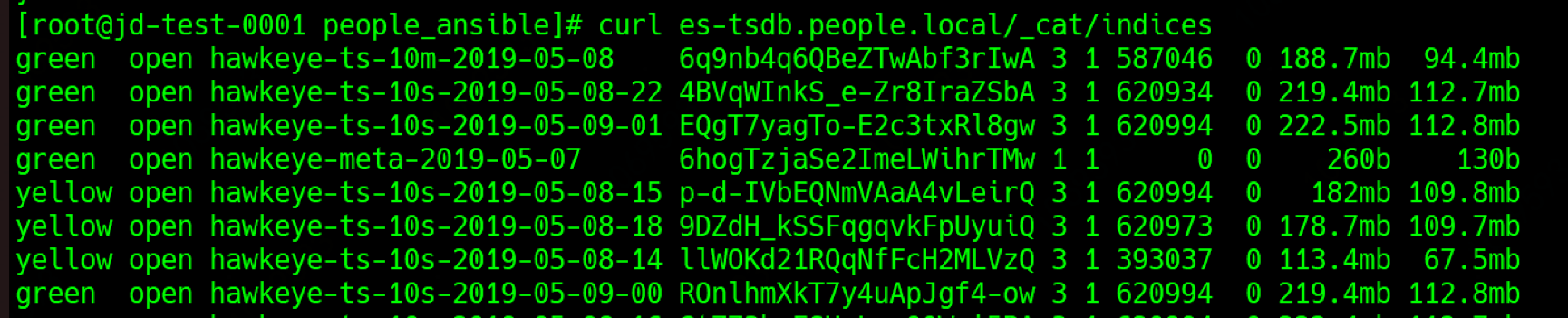
unassigned shard
查看shard的状态,是否存在unassigned的分片
1 | curl es-tsdb.people.local/_cat/shards|grep UNASSIGNED |

explain
使用explain查看具体原因:
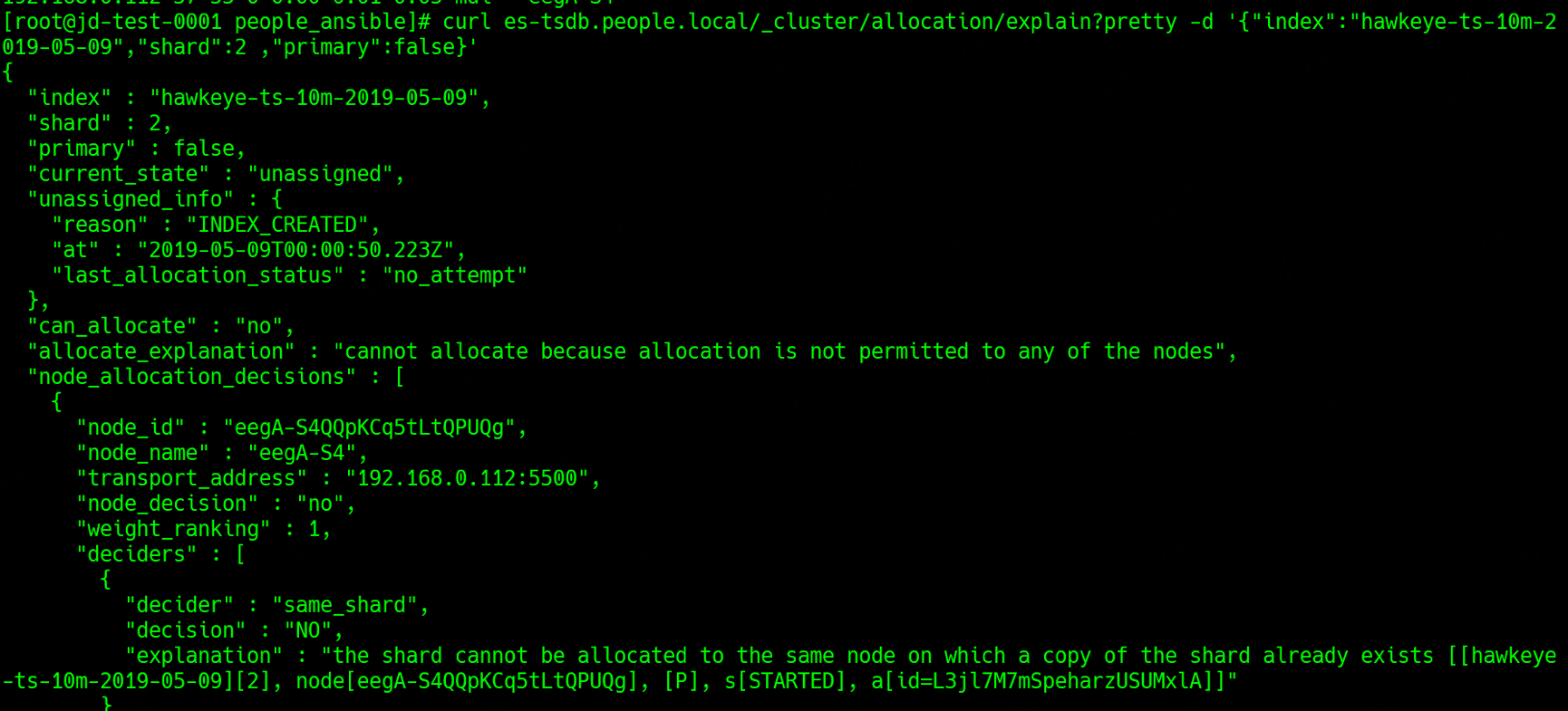
从reason中可以看出, 这个索引unassigned的原因为无法在同一个节点上保存两分副本.
也就是说,在该节点上已经存在了一个副本了.
同时另两个节点上无法保存副本的reason为:
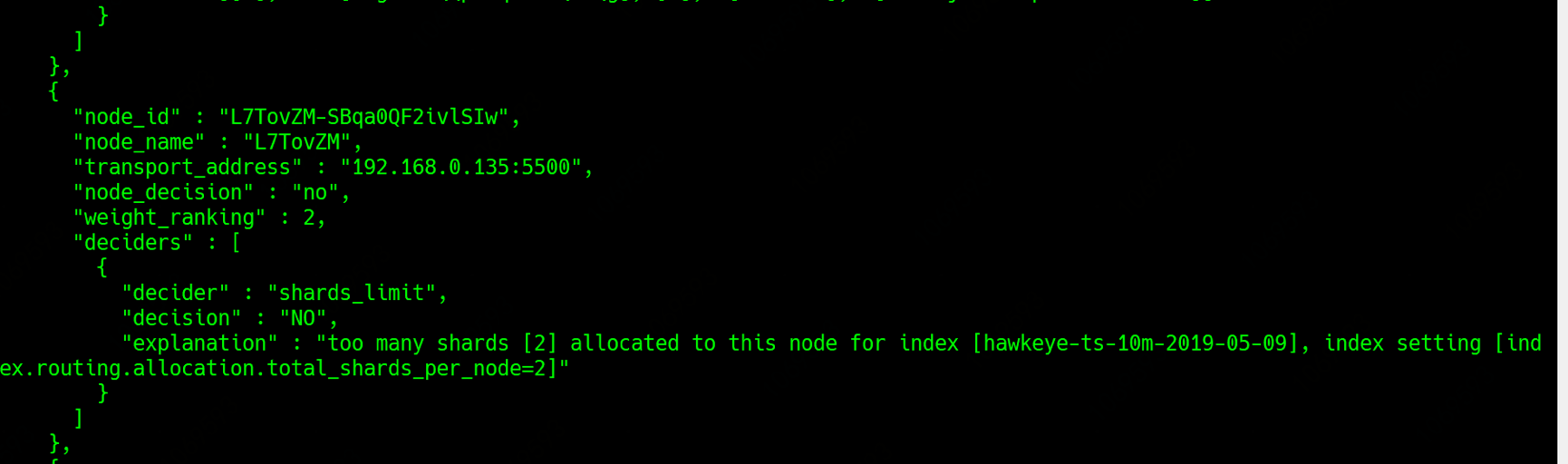
这个reason是说副本数量超时了这个节点能够存在副本的最大值,所以也没法分配。
从这里我们可以看出一个关键的参数index.routing.allocation.total_shards_per_node=2
这个参数指的是一个节点上最好能保存某个索引的最大值
假如: 一个es集群有3个数据节点,某个索引模板设置的分片数为3, 副本数为1, 那么总的分片数=主分片数+ 副分片数,也就是3+3=6个, 那么3个数据节点 则total_shards_per_node的值可以设置为6/3=2,每个节点上保存2个副本,一般情况下这是合理的.
但是如果某个时刻,es集群出现脑裂问题的话,比如说有个节点宕机,那么6个分片需要分布在两个节点上, 那么每个节点上需要保存3个副本,这大于total_shards_per_node=2,所以有可能出现以上的错误,所以一般起见, total_shards_per_node一般设置的比最小值大点。
total_shards_per_node这个值在es的配置文件中指定,同时也支持动态修改.
解决
1 | curl -XPUT 'http://es-tsdb.people.local/hawkeye-ts-10s-2019-05-08-18/_settings' -d '{"index.routing.allocation.total_shards_per_node":3}' |
修改之后,再次查看集群的状态,变回了green状态.