Kubernetes学习(Operator)
官方定义
An Operator is a method of packaging, deploying and managing a Kubernetes application.
旨在简化复杂有状态应用管理的框架,它是一个感知应用状态的控制器,通过扩展Kubernetes API来自动创建、管理和配置应用实例.
车库故事
诞生于车库, Kubernetes API 与 Operator,不为人知的开发者战争
operator的初衷是为开发者解决运维工作
先从kubernetes说起
两大重要特性:
- 声明式API: 我们提交一个定义好的API对象来”声明”我所期望的状态是什么样子
- 控制器模式: 无条件的, 无限循环的watch每个api对象,确保每个集群的状态与声明的状态一致
- 标签选择器: 通过标签确认资源之间的联系
流程可概括如下:

为什么kubernetes会有ReplicSet, Deployment, statefulSet, Operator等多种api资源?
应用情景
- 无状态:
- 有状态: mysq, redis…
- 分布式: etcd, zookeeper…
StatefulSet与Operator
statefulSet为kubernetes运行有状态应用的资源类型, 一般都搭配共享存储来持久化
StatefulSet 的核心原理,其实是对分布式应用的两种状态进行了保持:
- 分布式应用的拓扑状态, 或者说,节点之间的启动顺序;
- 分布式应用的存储状态, 或者说,每个节点依赖的持久化数据(比如容器 re-scheduler到另一node上,重新加载他的网络存储以及其中的数据)
打个比方: 如果想部署一个3节点的etcd集群
- 直接使用deployment方式很难维护各节点之间的启动顺序
- 使用statefulSet部署一个etcd集群, statefulSet可以保证etcd节点的启动顺序按照yaml期望的方式部署, 但是还是需要指定各节点之间的连接关系
如果使用operator的话, 则只需要告诉operator, 这是一个3节点的etcd集群, etcd的版本是xxxx即可, 其它的工作都交由operator控制器去完成. operator声明的api对象不再是单体应用的描述,而是整个分布式应用集群的动态逻辑
operator是在分布式应用领域发力,使用户自己定义kuberenetes的控制器来完成业务逻辑.
那openrator是如何做到对分布式应用如此清晰快捷?
TPR/CRD
TPR: Thrid Part Resousrce 第三方资源
CRD:Custom Resource Definition 资源自定义
在kubernetes 1.7之后,TPR升级为CRD, 总结来说,用户可自己编写任何的资源类型,同时实现对该资源类型的控制器
本质上,CRD做为kubernetes的特殊资源,它的工作方式如下:
Operator的工作方式
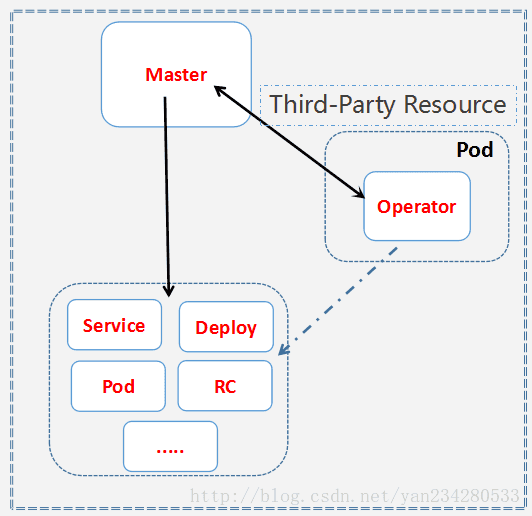
一个operator案例应该实现以下特性:
- Operator自身以deployment的方式部署
- Operator自动创建一个CRD资源类型,用户可以用该类型创建CR
- Operator利用Kubernetes内置的Serivce/ReplicaSet等API管理应用
- Operator应该向后兼容,并且在Operator自身退出或删除时不影响应用的状态
- Operator应该支持应用版本更新
使用Operator部署etcd集群
- 搭建一个kubernetes集群,这里使用的是kubeadm搭建
- 下载官方维护的etcd-operator-git
- 创建RBAC规则,主要声明对哪些资源有操作权限
- kubectl apply -f etcd-operator-deployment.yaml
- 指定etcd的节点数及版本
- kubectl apply -f example-etcd-cluster.yaml
这样一个 etcd集群就部署完成,这些操作具体发生了什么?
1 | 当执行完etcd-operator-deployment.yaml后,启动一个容器,容器的entrypoing为etcd-operator |
查看etcd的pod数是不是与预期相符

进容器查看etcd启动状态

大家一定很好奇,etcd启动命令里为什么不是etcd节点ip, 而且一大串的像域名一样的字符?
这是因为etcd的启动命令是在pod启动之前就已经生成好的,这个时候pod还没启动,也是没有分配ip,所以使用域名的形式
这个域名又是如何产生的,通过这个域名又是如何找到pod的呢?
其实在生成etcd集群的同时etcd-operator会自动生成一个与example-etcd-cluster同名的headless service资源
service类型的资源会分配一个vip(可指定),访问service时由该vip转到后端某个pod上
headless service(spec.clusterIP为None)类型资源不会分配vip, 访问该service直接返回所有后端pod列表
查看生成的headless service与endpoints


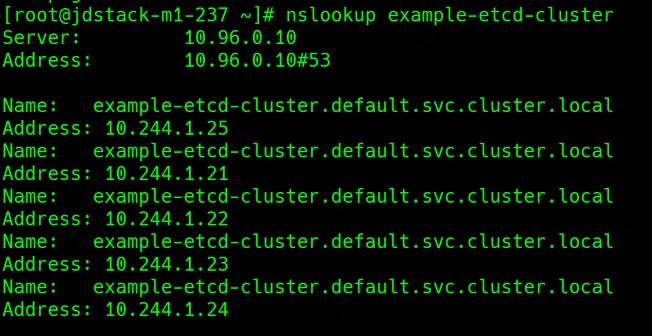
当创建了一个headless service的资源时,它所代理的所有pod的ip地址都会绑定DNS记录,格式如下
比如: example-etcd-cluster-6n7hb78tkm.example-etcd-cluster.default.svc
尊崇以下规则 : pod名.service名.namespaces.svc
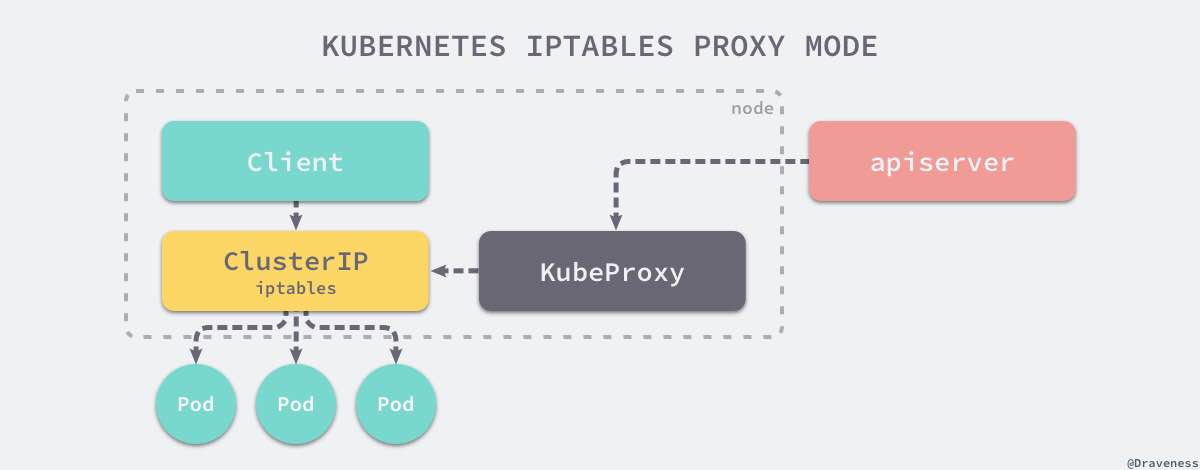
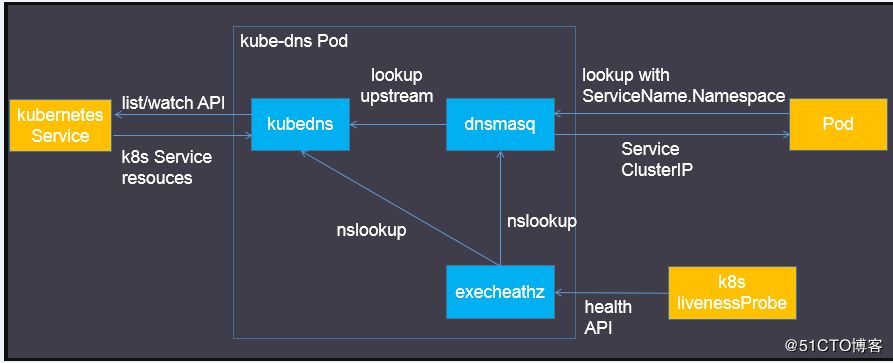
域名解析由kube-dns负责, endpoints由kube-proxy管理,kube-proxy会订阅所有service的变更从而更新iptalbes规则,endpointscontroller会订阅pod跟service对象的变更,并根据当前集群中的对象生成endpoint对象将service跟pod关联
关于kube-proxy与kube-dns,篇幅有限,可参考这两篇文章:
整个服务发现流程:
etcd-operator常用命令
扩缩容
1 | 当前的节点数为3, 版本为3.2.13 |


版本升级
1 | 版本为3.2.13 |

节点宕机
1 | 删除一个etcd pod, 这里删除种子节点 |

etcd-operator会创建一个新节点出来
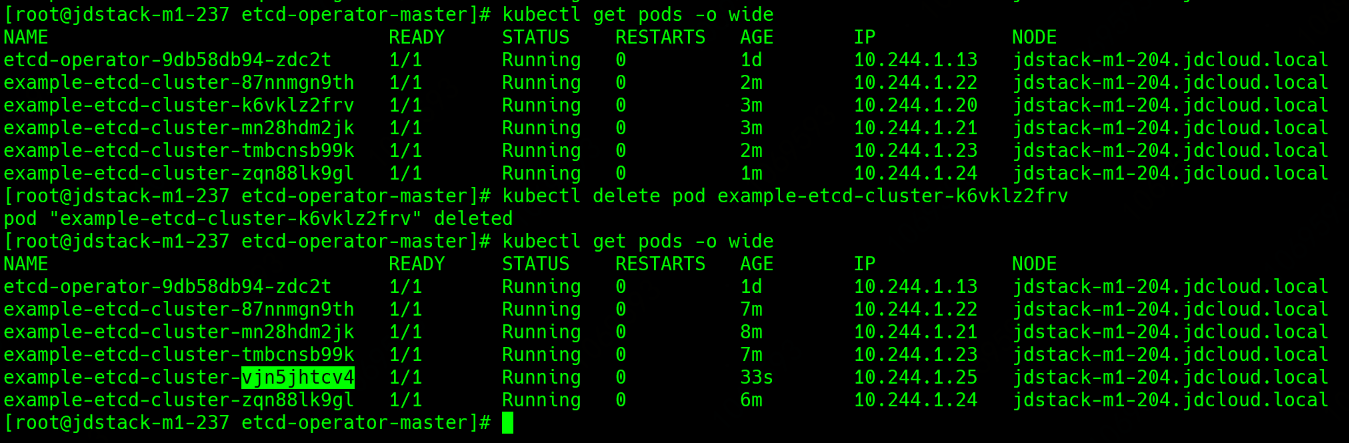
在原etcd容器中已无法ping通被删除pod

而新生成的etcd节点的启动命令则不会包含被删除的节点

查看etcd member list, 旧节点已删除,新节点加入

备份还原
目前官方维护了etcd-backup-operator,支持远程备份到AWS S3/ Azure Blob Service (ABS)/Google Cloud Storage (GCS)
或者从上述几个远程存储上还原etcd数据,etcd-restore-operator
同时官方维护了一个定时备份任务