Kubernetes学习(etcd)
WHAT etcd
- go language, open-source
- distributed,highly-available key-value store
- shared configuration
- service discovery
WHY etcd
- API based on HTTP+JSON
- support SSL/TLS Auth
- 1000 request/s/n
- high performance,highly-available high-consistency
CAP理论
谈到分布式系统,不得不提CAP理论,先从两张经典的照片说起:
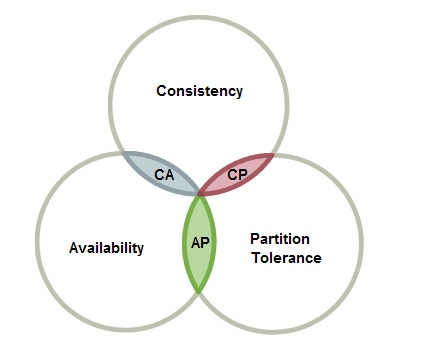
名词解析:
- Partition Tolerance:分区容错性,在分布式系统中,可能会出现分区之间无法通信
- Consistency: 一致性:同一个数据在集群中的所有节点,同一时刻是否都是同样的值
- Availability: 可用性:集群中一部分节点故障后,集群整体是否还能处理客户端的请求

CAP理论:对于分布式系统,C,A,P无法同时满足
- 分区容错(P)是基本要求,C跟A不能同时满足,CAP理论的C指的是强一致性
- 强一致性: 当更新操作完成之后,任何多个后续进程的访问都会返回最新的更新过的值.这种是对用户最友好的,就是用户上一次写什么,下一次就保证能读到什么.根据 CAP 理论,这种实现需要牺牲可用性
- 弱一致性: 系统并不保证后续进程访问都会返回最新的更新过的值.系统在数据写入成功之后,不承诺立即可以读到最新写入的值,也不会具体的承诺多久之后可以读到.
- 最终一致性: 弱一致性的特定形式,即系统保证在没有后续更新的前提下,经过一个时间窗口后能访问到更新后的数据
一致性问题是由并发问题产生的
CAP无法同时满足是由网络分区产生的
etcd是如何保证强一致性同时可用性也很高的呢?
etcd架构
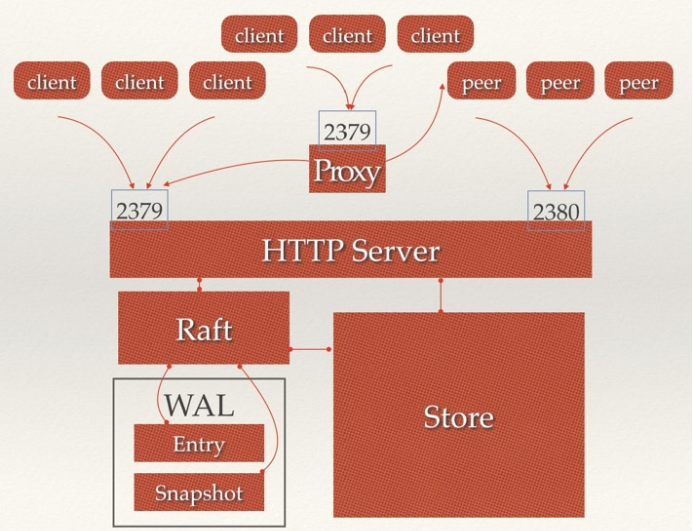
- HTTP Server: 用于接收用户发送的API请求及心跳请求转发到具体模块.
- Raft: etcd数据强一致性算法的具体实现.
- WAL: etcd的数据存储方式.
- Store: 用于处理etcd支持的各类功能的事务,包括数据索引、节点状态变更、监控与反馈、事件处理与执行等等,是etcd 对用户提供的大多数API功能的具体实现.
etcd角色
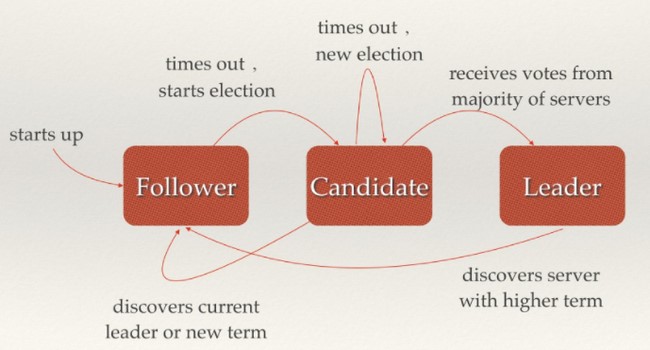
工作原理
etcd通常做为一个分布式系统,由多个节点相互通信构成整体对外服务,任意时刻至多存在一个有效的Leader节点,同时每个etcd节点都维护了一个状态机,每个节点都存储了完整的数据.
主节点处理所有来自客户端写操作,每次写请求都需要集群中大多数据节点投票能过后Leader节点才能将修改内部状态机,并返回将结果返回给客户端
follower节点只响应来自领导人和候选人的请求.领导人来处理所有来自客户端的请求(默认设置下,如果一个客户端与追随者进行通信,追随者会将信息发送给领导人)
通过Raft协议保证集群所有节点的数据是一致的
etcd选举
当集群初始化时候,每个节点都是Follower角色,集群中存在至多1个有效的主节点,通过心跳与其他节点同步数据,心跳周期默认为100ms.
当Follower在一定时间内没有收到来自主节点的心跳,会将自己角色改变为Candidate,并发起一次选主投票;当收到包括自己在内超过半数节点赞成后,选举成功(选举为Leader的节点一定包含所有已提交的日志),当收到票数不足半数选举失败,或者选举超时,(默认选举时间为1000ms).若本轮未选出主节点,将进行下一轮选举(出现这种情况,是由于多个节点同时选举,所有节点均为获得过半选票,为了避免陷入选主失败循环,每个节点未收到心跳发起选举的时间是一定范围内的随机值,这样能够避免2个节点同时发起选主).
Candidate节点收到来自主节点的信息后,会立即终止选举过程,进入Follower角色.
通过RAFT协议保证在符合条件的下一定能够选主成功
RAFT协议
关于Raft的几个重要的结论:
- RAFT充分利用了go语言的并发模型,使得etcd性能强悍.
- 节点数据一致性通过日志复制(wal, Write Ahead Log,预写日志)实现,每次有数据更新的时候产生二阶段提交(two-phase commit),第一阶段先提交日志,通过heartbeat把该日志广播给其它follow,如果超过半数的follower都成功写了log,那么leader开始第二阶段的提交:正式写入数据,然后同样广播给follower,follower也根据自身情况选择写入或者不写入并返回结果给leader。leader先写自己的数据,然后告诉follower也开始持久化数据.这两阶段中如果任意一个都有超过半数的follower返回false或者根本没有返回,那么这个分布式事务是不成功的.
- 领导人完全原则(Leader Completeness Property):被选举为领导人的节点一定拥有所有已经被提交的日志条目,读写请求只向主节点发送(v2版本),以此保证一致性,(v3版本中,支持在客户端指定读请求方式,默认为etcdctl –consistency=’l’,说明使用线性读,=’s’则使用串行读,这种方式读可以落到集群任一节点上,该节点直接从本地读取结束返回给客户端,不再需要把请求转给leader, 但可能会返回脏数据).
- 默认配置下,领导人在处理只读的请求之前必须检查自己是否还是Leader(如果一个更新的领导人被选举出来,它自己的信息就已经过期了).
日志复制
etcd的数据一致性是通过raft的日志复制实现的,在etcd/member/目录中有两个子目录,snap和wal.那么为什么Etcd会有snap目录呢?
主要有两个原因:
- snapshot是wal快照,wal一直在追加日志占用资源大,为了节约磁盘空间,当wal文件达到一定数据,就会对之前的数据进行压缩,形成快照,但对于etcd来说,snapshot是一种昂贵的操作,默认情况下,每10000次变更会生成一次,可通过api修改,etcd –snapshot-count=5000
- 当新的节点加入到集群中,为了同步数据,就会把snapshot发送到新节点,这样能够节约传输数据(生成的快照文件比wal文件要小很多,5倍左右),使之尽快加入到集群中
etcd在云翼中的使用
现阶段云翼中使用到的etcd有hubor(hubor正逐渐实现用mysql替换etcd),captain.balloon中借用k8s向etcd写入deployment数据.captain中使用etcd存储网段信息,最后容器在node上启动之后通过cni调用captain获取容器ip.
每个机房部署一个k8s-master,3个etcd组成一个集群,各机房集群独立,etcd服务相对稳定,加上日常的定时备份机制,同时出现两个节点都契机的可能性很小,万一出现整个机房故障的话,master都挂了,etcd也无法服务.
同时,etcd的raft机制不太合适跨机房部署, 网络延迟高的话,很容易重新选举,两个机房部署一套集群,如果一个机房整体故障,别一个机房还是无法正常工作.而如果采用两个机房部署两套集群,再通过其它工具在这两个集群之间同步数据,则受网络因素影响较大.
etcd的接口分为v2,v3接口,默认使用v2接口,v3接口中存留了k8s的包括deployment,servcice等元信息,而在v2保留有pod的业务数据
从上面也可看出,etcd做为配置共享的k-v系统,key跟value的值不能太大,官方建议value大小为1m.
etcd常用命令
1 | etcd集群启动 |
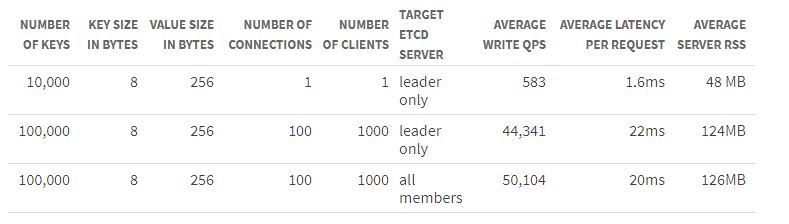
etcd性能
etcd官网上的性能测试数据
google cloud computer engine/3 machine of 8 CPUs+16GB mem+50GB ssd/ubuntu 17.04/etd3.2.0,go1.8.3

etcd VS zookeeper
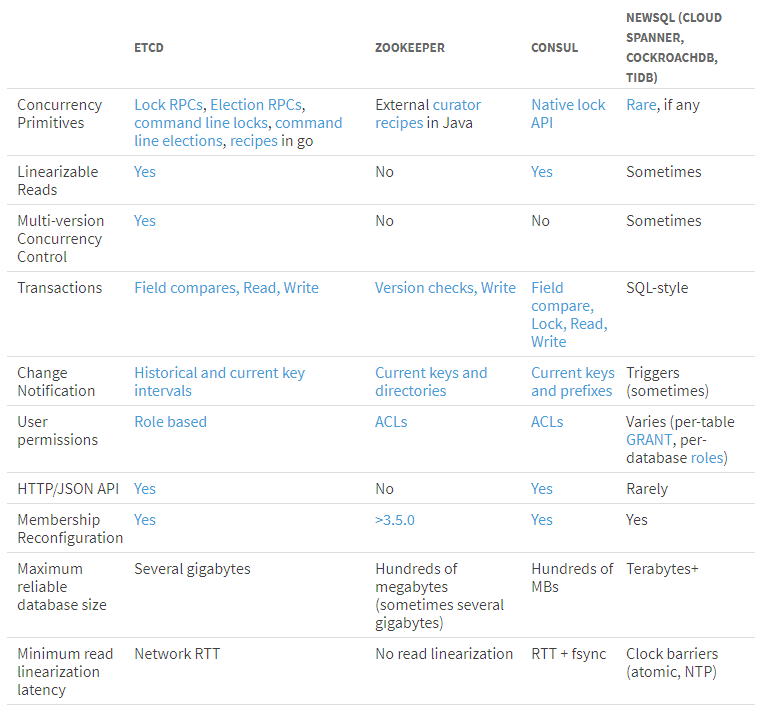
关于zookeeper,下次单独做个分享.