mysql学习(redo,undo)
redo跟undo是很多数据库都支持的特性,不同的数据库redo跟undo可能有点细节上的不同,整个方向几乎都起着同样的效果.
undo: 撤销,也就是取消之前的操作.
redo: 重做,重新执行一遍之前的操作.
这里主要以mysql常用的且支持事务特性的innodb存储引擎为例,myisam不在这之列.
redo
redo,从字面上来理解,就是重新执行一次之前做的操作,我们一般叫做前滚(rollforward),是一种事务日志(transaction logs),可分为online和archived,以恢复为目的,保证事务的持久性.
Redo Log记录的是新数据的备份.在事务提交前,只要将Redo Log持久化即可,不需要将数据持久化(当然这需要根据配置而定具体什么时候数据文件持久化).当系统崩溃时,虽然数据没有持久化,但是Redo Log已经持久化.系统可以根据Redo Log的内容,将所有数据恢复到最新的状态.
一般的,redo log 都是会以日志组的形式出现,以顺序的方式写入文件文件,这就是 online redo log(在线重做日志),写满时则回溯到第一个文件,在进行覆盖写之前,有些数据库如Oracle则会把之前的redo log文件打包到特定目录下存档,这种文件就叫做archived redo log(归档重做日志).
redo log 其实由两部分组成,:redo log buffer 跟redo log file.redo log buffer 跟redo log file.buffer pool中把数据修改情况记录到redo log buffer,出现以下情况,再把redo log刷下到redo log file:
- Redo log buffer空间不足
- 事务提交(依赖innodb_flush_log_at_trx_commit参数设置)
- 后台线程
- 做checkpoint
- 实例shutdown
- binlog切换
这里有个重要的参数需要解释一下
innodb_flush_log_at_trx_commit
官方的解释请看这里:
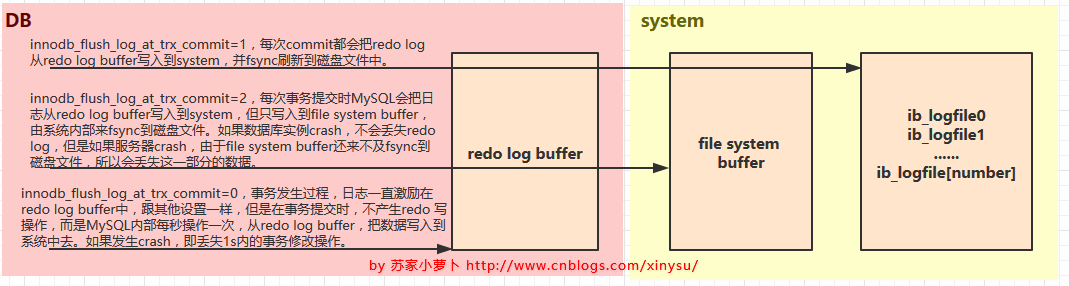
- innodb_flush_log_at_trx_commit=1,每次事务提交时,log buffer 会被写入到日志文件并刷写到磁盘.这也是默认值.这是最安全的配置,但由于每次事务都需要进行磁盘I/O,所以也最慢.
- innodb_flush_log_at_trx_commit=2,每次事务提交会写入日志文件,但并不会立即刷写到磁盘,日志文件会每秒刷写一次到磁盘.这时如果 mysqld 进程崩溃,由于日志已经写入到系统缓存,所以并不会丢失数据;在操作系统崩溃的情况下,通常会导致最后 1s 的日志丢失
- innodb_flush_log_at_trx_commit=0,log buffer 会 每秒写入到日志文件并刷写(flush)到磁盘.但每次事务提交不会有任何影响,也就是 log buffer 的刷写操作和事务提交操作没有关系.在这种情况下,MySQL性能最好,但如果 mysqld 进程崩溃,通常会导致最后 1s 的日志丢失.
- 注意:由于进程调度策略问题,这个“每秒执行一次 flush(刷到磁盘)操作”并不是保证100%的“每秒”.
在官网上还有这么一句话:
InnoDB log flushing frequency is controlled by innodb_flush_log_at_timeout, which allows you to set log flushing frequency to N seconds (where N is 1 ... 2700, with a default value of 1). However, any mysqld process crash can erase up to N seconds of transactions.
innodb log 的从buffer刷新到log的频率还受innodb_flush_log_at_timeout这个参数的控制,这个参数允许你设置1-2700秒中的任何一个秒数,但是当mysql宕机的时候,会损失这N秒内的数据
DDL changes and other internal InnoDB activities flush the InnoDB log independent of the innodb_flush_log_at_trx_commit setting.
对于DDL的改变和一些innodb内部的一些刷新机制不依赖于innodb_flush_log_at_trx_commit 参数
InnoDB crash recovery works regardless of the innodb_flush_log_at_trx_commit setting. Transactions are either applied entirely or erased entirely.
innodb的宕机恢复不受innodb_flush_log_at_trx_commit参数影响,事务要么全部应用要么全部擦除.
借用网上一张图来解释这个日志流向过程:
redo恢复
从上面我们知道的redo 日志的数据流向, 那么redo是如何恢复数据的呢?
- 在设置innodb_flush_log_at_trx_commit=1的情况下,如果只在redo log buffer中写入了日志,还没来的及写到redo log file中,此时mysql数据库宕机,再启动mysql时 redo log buffer内的记录肯定都不复存在,没有关系,也无需恢复,就相当于该事务还没发生一样,因为数据库的datafile并没有改变.
- 在设置innodb_flush_log_at_trx_commit=1的情况下,如果日志已经写进了redo log file中(或者说从redo log file中刷数据到datafile刷到一半),此时mysql数据库宕机,再启动mysql时,mysql会自动的把redo log file中的记录执行一次到宕机的失败点,这样就能保证事务完整执行,这就是所谓的前滚.
undo
undo,从字面上来理解就是撤销这次操作,我们一般叫做回滚(rollback),它也是一种事务日志(transaction logs).它主要是保证事务的原子性及提供读一致性.
Undo Log的原理很简单,为了满足事务的原子性,在操作任何数据之前,首先将数据备份到一个地方(这个存储数据备份的地方称为Undo Log).然后进行数据的修改.如果出现了错误或者用户执行了ROLLBACK语句,系统可以利用Undo Log中的备份将数据恢复到事务开始之前的状态.
回滚
这个就不用说了,就是撤销到事务开始之前的状态.
MVCC
mvcc(Multiversion Concurrency Control,多版本并发控制),mvcc+undo一同为mysql提供一致性非锁定读的机制,提供更高的并发.
我们知道MySQL中的InnoDB存储引擎的默认隔离级别REPEATABLE READ(RR), 行级锁(在不能确定范围的情况下使用表级锁),当有一个事务正在更新某些数据时(写操作),同时另一个事务还能读取这些数据(读操作),确切的说是历史数据据,这就是mvcc与undo的作用,这里涉及到mysql的隔离级别,先不在这篇讨论,会另起一篇.
redo+undo
假设有A、B两个数据,值分别为1,2,开始一个事务,事务的操作内容为:把1修改为3,2修改为4,那么实际的记录如下(简化):
1 | A.事务开始. |
Undo + Redo的设计主要考虑的是提升IO性能,增大数据库吞吐量.可以看出,B D E G H,均是新增操作,但是B D E G 是缓冲到buffer区,只有H是真正的增加了IO操作,为了保证Redo Log能够有比较好的IO性能,InnoDB 的 Redo Log的设计有以下几个特点:
- A.尽量保持Redo Log存储在一段连续的空间上.因此在系统第一次启动时就会将日志文件的空间完全分配. 以顺序追加的方式记录Redo Log,通过顺序IO来改善性能.
- B. 批量写入日志.日志并不是直接写入文件,而是先写入redo log buffer.当需要将日志刷新到磁盘时 (如事务提交),将许多日志一起写入磁盘.
- C. 并发的事务共享Redo Log的存储空间,它们的Redo Log按语句的执行顺序,依次交替的记录在一起,
- D. 因为C的原因,当一个事务将Redo Log写入磁盘时,也会将其他未提交的事务的日志写入磁盘.
- E. Redo Log上只进行顺序追加的操作,当一个事务需要回滚时,它的Redo Log记录也不会从Redo Log中删除掉,对于 回滚事务先执行redo,再从undo中回滚.
1 | 以减少日志占用的空间.例如,Redo Log中的记录内容可能是这样的: |
一次提交IO,会将其它日志一同提交,这样便提高了IO性能.
恢复
有2种不同的恢复策略:
- A.进行恢复时,只重做已经提交了的事务.
- B.进行恢复时,重做所有事务包括未提交的事务和回滚了的事务.然后通过Undo Log回滚那些
MySQL数据库InnoDB存储引擎使用了B策略, InnoDB存储引擎中的恢复机制有几个特点:
- 在重做Redo Log时,并不关心事务性. 恢复时,没有BEGIN,也没有COMMIT,ROLLBACK的行为.也不关心每个日志是哪个事务的.尽管事务ID等事务相关的内容会记入Redo Log,这些内容只是被当作要操作的数据的一部分
- 使用B策略就必须要将Undo Log持久化,而且必须要在写Redo Log之前将对应的Undo Log写入磁盘.Undo和Redo Log的这种关联,使得持久化变得复杂起来.为了降低复杂度,InnoDB将Undo Log看作数据,因此记录Undo Log的操作也会记录到redo log中.这样undo log就可以象数据一样缓存起来,而不用在redo log之前写入磁盘了
- Innodb也会将事务回滚时的操作记录到redo log中.回滚操作本质上也是对数据进行修改,因此回滚时对数据的操作也会记录到Redo Log中
- 一个被回滚了的事务在恢复时的操作就是先redo再undo,因此不会破坏数据的一致性
简言之就是:mysql恢复时会执行所有的redo(包含了回滚的事务), 对于那些被回滚的事务再应用undo操作.
总结
| UNDO | REDO | |
|---|---|---|
| Record of | How to undo a change | How to reproduce a change |
| Used for | Rollback, Read-Consistency | Rolling forward DB Changes |
| Stored in | Undo segments | Redo log files |
| Protect Against | Inconsistent reads in multiuser systems | Data loss |