mysql学习(SQL执行过程)
数据库一般都分为服务器端跟客户端两部分,客户端可能有多样的形式,我们使用客户端执行一条sql语句到服务器返回数据这个过程中,整个流程是如何操作的呢? 这里以mysql数据库来说.
这里再借用一条图来看看mysql的基础组件
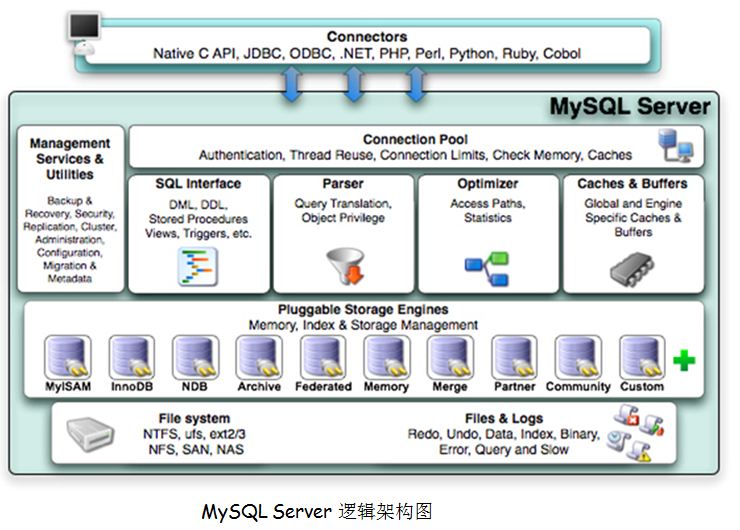
可以看出mysql的连接可以通过多种方式进来,都可以称之为客户端,当我们在客户端执行语句时(比如最简单的select),客户端会把这条 SQL 语句发送给服务器端,让服务器端的进程来处理这语句,这里要注意的是客户端不会对sql语句做任何的工作,只是负责把sql语句发送到服务器端,那服务器跟客户端的通信方式又是如何的呢?
C/S通信机制
关于这部分不过分去深究原理了,大家可以看看这篇文章,对这部分写的不错,这里挑重点:
MySQL客户端和服务器之间的通信协议是“半双工”的,这意味着,在任何一个时刻,要么是由服务器向客户端发送数据,要么是由客户端向服务器发送数据,这两个动作不能同时发生,服务器会使用TCP监听一个本地socket端口或本地socket链接.当一个客户端的连接请求到达,就会执行握手和权限验证.如果验证成功,会话开始.客户端发送消息,服务器会以一个适合该发送命令的数据类型的数据集或一条消息进行回复.当客户端发送完成后,会发送一个特殊的命令,告诉服务器已发送,然后会话结束. 通信的基本单位是应用程序包.多个指令责成一个包.答复可以包含几个包.
所以说c/s通信是分两个阶段:握手认证阶段和命令执行阶段
还有一点就是,通常客户端给服务器发送的数据包很少(其它就是些sql语句),所以基本一个数据包就能够传递给服务器,相反的,一般服务器响应给用户的数据通常很多,由多个数据包组成.当服务器开始响应客户端请求时,客户端必须完整的接受整个返回结果,而不是简单的只收取前面几条结果,然后让服务器停止发送数据
当sql到达服务端之后,服务端会如何处理呢?
服务器处理
服务器会生成一个进程来处理这个客户端的请求,服务器跟客户端是一一对应的关系
我们再来看一张图:
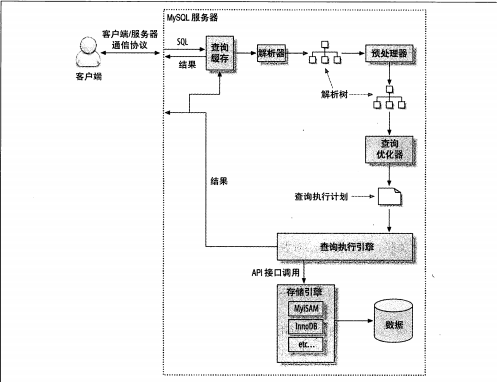
从上面的图可以看出流向大概为:
client发送SQL –> [ 查询缓存 ] –> 解析器 –> 生成解析树 –> 预处理器 –> 再次生成解析器 –> 优化器 –> 生成执行计划 –> 调用存储引擎API –> 返回结果到client
查询缓存
这里要重点提下查询缓存,mysql中的查询缓存类似于Oracle中的软硬解析的机制
在解析一个查询语句之前,如果查询缓存是打开的,那么mysql会优先检查这个查询是否命中查询缓存中的数据.使用查询语句、数据库名称、客户端协议的版本等因素生成一个对大小写敏感的哈希值,查询和缓存中的查询即使只有一个字节不同(或者sql语句相同但是用户权限相关的不同,总之很多的条件来判断是否为同一条sql),那也不会匹配缓存结果,这种情况下查询就会进入下一阶段的处理.
如果当前的查询恰好命中了查询缓存,那么在返回查询结果之前mysql会检查一次用户权限.这仍然是无须解析查询SQL语句的,因为在查询缓存中已经存放了当前 查询需要访问的表信息.如果权限没有问题,mysql会跳过所有其他阶段,直接从缓存中拿到结果并返回给客户端.这种情况下,查询不会被解析,不用生成执行计划,不会被执行,所以查询缓存可以在一定程度上提高查询效率,但是打开查询缓存也有一定的弊端:
如果是写多读少的场景下话,大量的更新/插入操作会使查询缓存的更新频率也变得多,这对性能有很大影响
对于InnoDB而言,事物的一些特性还会限制查询缓存的使用.当在事物A中修改了B表时,因为在事物提交之前,对B表的修改对其他的事物而言是不可见的.为了保证缓存结果的正确性,InnoDB采取的措施让所有涉及到该B表的查询在事物A提交之前是不可缓存的.如果A事物长时间运行,会严重影响查询缓存的命中率
解析器及预处理
其实就是检查sql语句是否正确及权限是否能够访问,首先mysql通过关键字将SQL语句进行解析,并生成一颗对应的“解析树”.mysql解析器将使用mysql语法规则验证和解析查询;预处理器则根据一些mysql规则进一步检查解析数是否合法
优化器
到了这步,优化器会对sql语句进行优化,包括表的连接方式,条件的先后等都会进行优化,而且现在的优化器越来越智能,优化器将语法树转换成执行计划,一条查询可以有很多种执行方式,最后都返回相同的结果.优化器的作用就是找到这其中最好的执行计划,这就是CBO(cost-based optimizer 基于成本的优化器)
执行引擎
mysql简单的根据执行计划给出的指令逐步执行.在根据执行计划逐步执行的过程中,有大量的操作需要通过调用存储引擎实现的接口来完成.为了执行查询,mysql只需要重复执行计划中的各个操作,直到完成所有的数据查询,当然不同的存储引擎实现的API接口是不一样的,内部的机制也有所不同,如myisam跟innodb就有所不同,innodb因为支持事务,所以有更多额外的机制。
返回结果
查询执行的最后一个阶段是将结果返回给客户端.即使查询不需要返回结果给客户端,mysql仍然会返回这个查询的一些信息,如该查询影响到的行数.如果查询可以被缓存,那么mysql在这个阶段也会将结果放到查询缓存中.
mysql将结果集返回客户端是一个增量、逐步返回的过程.这样有两个好处:服务器端无须存储太多的结果,也就不会因为返回太多结果而消耗太多的内存;这样处理也让msyql客户端第一时间获得返回的结果.
结果集中的每一行都会以一个满足mysql客户端/服务器通信协议的包发送,再通过tcp协议进行传输,在tcp传输的过程中,可能对mysql的封包进行缓存然后批量传输