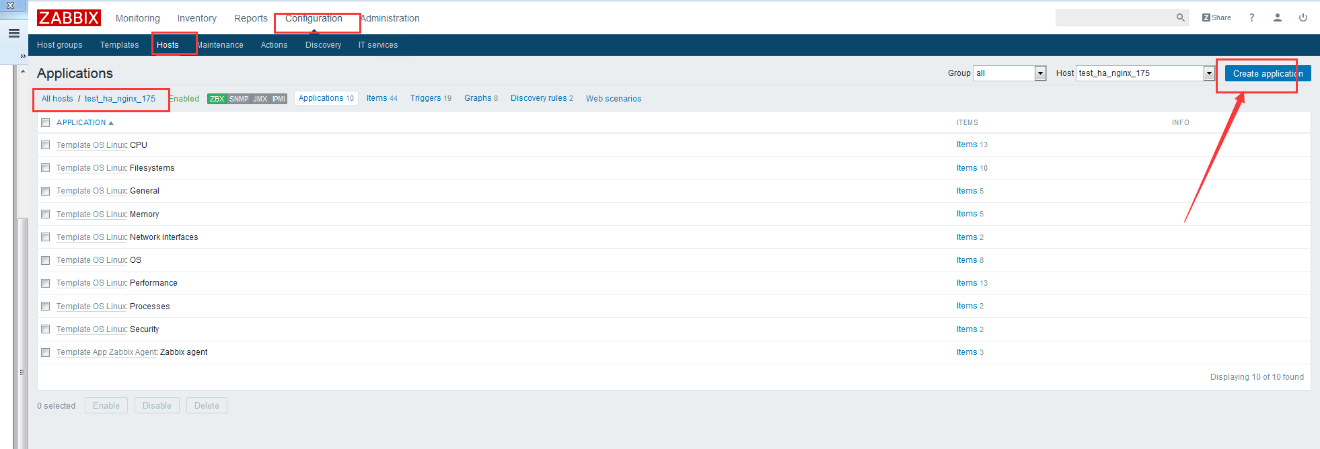
有时需要监控业务系统特定的入口页面及页面的响应速度,节点数少的话还能写个小脚本使用curl处理,数量一多的话就有点力不从心了,而且需要自动报警功能,使用脚本不太容易实现了,特别是处于内网环境,使用zabbix的http模板则很容易解决这类问题,思路也非常简单:脚本(shell/python均可)+zabbix的simple check即能实现
脚本 这里还是使用curl一个网址,得到返回值,一般情况下正常能够访问返回值为200,维护一个WEB.txt,shell脚本从该文件中读取url,需要注意一点的是,这里使用到了zabbix的自动发现功能,所以返回格式严格为json格式 ,shell脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 cat web_site_code_status.sh # !/bin/bash # function :monitor tcp connect status from zabbixsource /etc/bashrc >/dev/null 2>&1 source /etc/profile >/dev/null 2>&1 # /usr/bin/curl -o /dev/null -s -w %{http_code} $1 web_site_discovery () { WEB_SITE=($(cat /usr/local/zabbix/sbin/WEB.txt|grep -v "^#")) printf '{\n' printf '\t"data":[\n' for((i=0;i<${#WEB_SITE[@]};++i)) { num=$(echo $((${#WEB_SITE[@]}-1))) if [ "$i" != ${num} ]; then printf "\t\t{ \n" printf "\t\t\t\"{#SITENAME}\":\"${WEB_SITE[$i]}\"},\n" else printf "\t\t{ \n" printf "\t\t\t\"{#SITENAME}\":\"${WEB_SITE[$num]}\"}]}\n" fi } } web_site_code () { /usr/bin/curl -o /dev/null -s -w %{http_code} $1 } case "$1" in web_site_discovery) web_site_discovery ;; web_site_code) web_site_code $2 ;; *) echo "Usage:$0 {web_site_discovery|web_site_code [URL]}" ;; esac
WEB.txt的格式如下,一个url对应一行:
1 2 3 4 http://127.0.0.1/index.html http://127.0.0.1:7002/ http://baidu.com/ ...
把脚本加入crontab每分钟执行一次
1 */1 * * * * root /usr/local/zabbix/script/web_site_code_status.sh
觉得shell脚本的格式比较费劲的等方面,也可以使用python,脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import osimport sysimport jsondef web_site_discovery (): web_list=[] web_dict={"data" :None } with open ("WEB.txt" ,"r" ) as f: for url in f: url_dict={} url_dict["{#SITENAME}" ]=url.strip() web_list.append(url_dict) web_dict["data" ]=web_list jsonStr = json.dumps(web_dict, sort_keys=True , indent=4 ) return jsonStr def web_site_code (): cmd='curl -o /dev/null -s -w %s %s' %("%{http_code}" ,sys.argv[2 ]) reply_code=os.popen(cmd).readlines()[0 ] return reply_code if __name__ == "__main__" : try : if sys.argv[1 ] == "web_site_discovery" : print web_site_discovery() elif sys.argv[1 ] == "web_site_code" : print web_site_code() else : print "Pls sys.argv[0] web_site_discovery | web_site_code [URL]" except Exception as msg: print msg
修改zabbix_agentd.conf 在客户端的zabbix_agentd.conf中增加自定义的key
1 2 3 UnsafeUserParameters=1 UserParameter=web_site_discovery,/etc/zabbix/scripts/web_site_moniter.py web_site_discovery UserParameter=web_site_code[*],/etc/zabbix/scripts/web_site_moniter.py web_site_code $1
在服务器端测试返回值,返回数据如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 zabbix_get -s 100.12 .255 .160 -p 10050 -k web_site_code[http://baidu.com/] 200 zabbix_get -s 100.12 .255 .160 -p 10050 -k web_site_discovery { "data" : [ { "{#SITENAME}" : "http://127.0.0.1/index.html" }, { "{#SITENAME}" : "http://127.0.0.1:7001/" }, { "{#SITENAME}" : "http://www.baidu.com/" } ] }
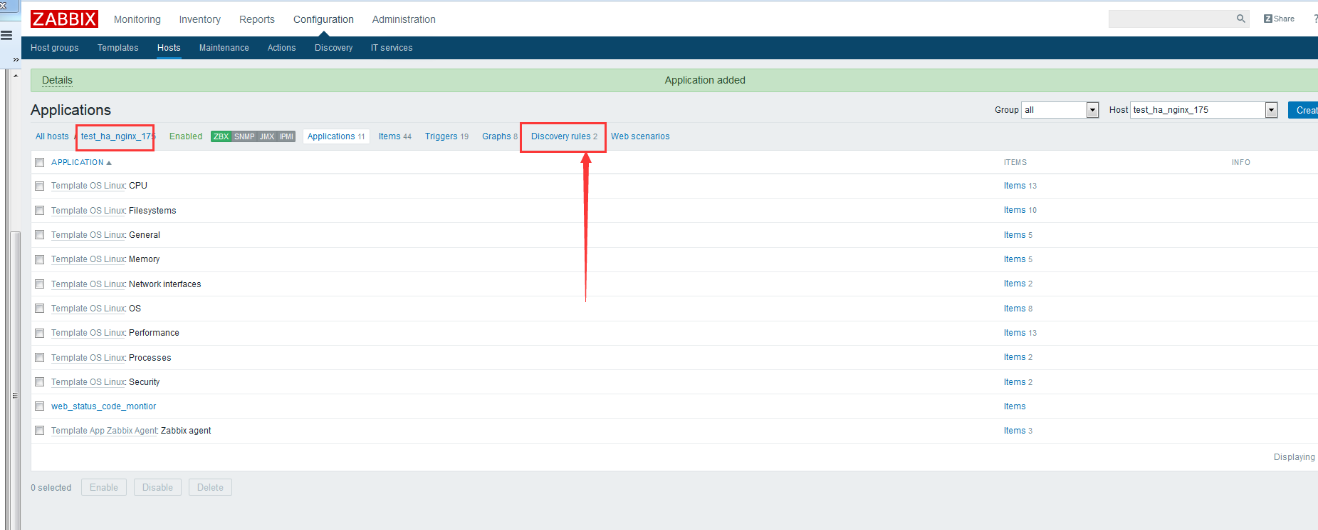
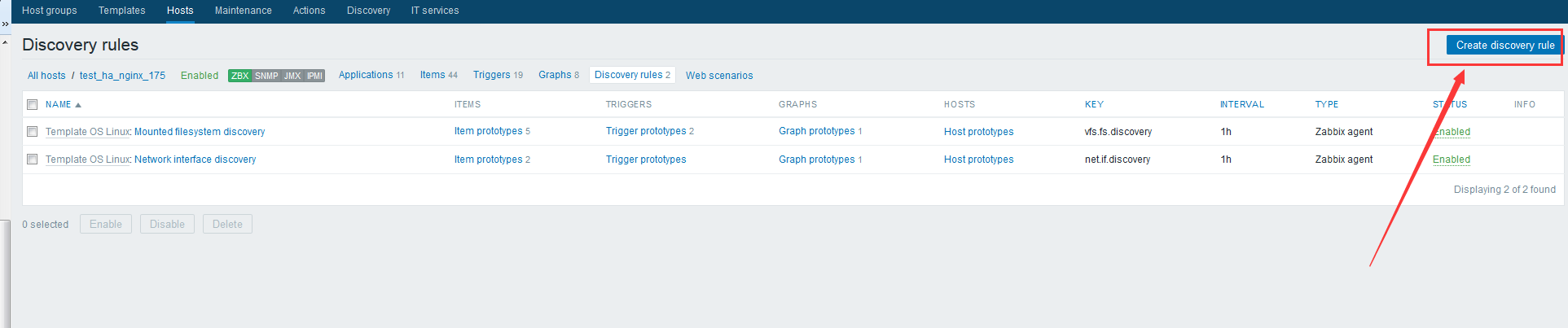
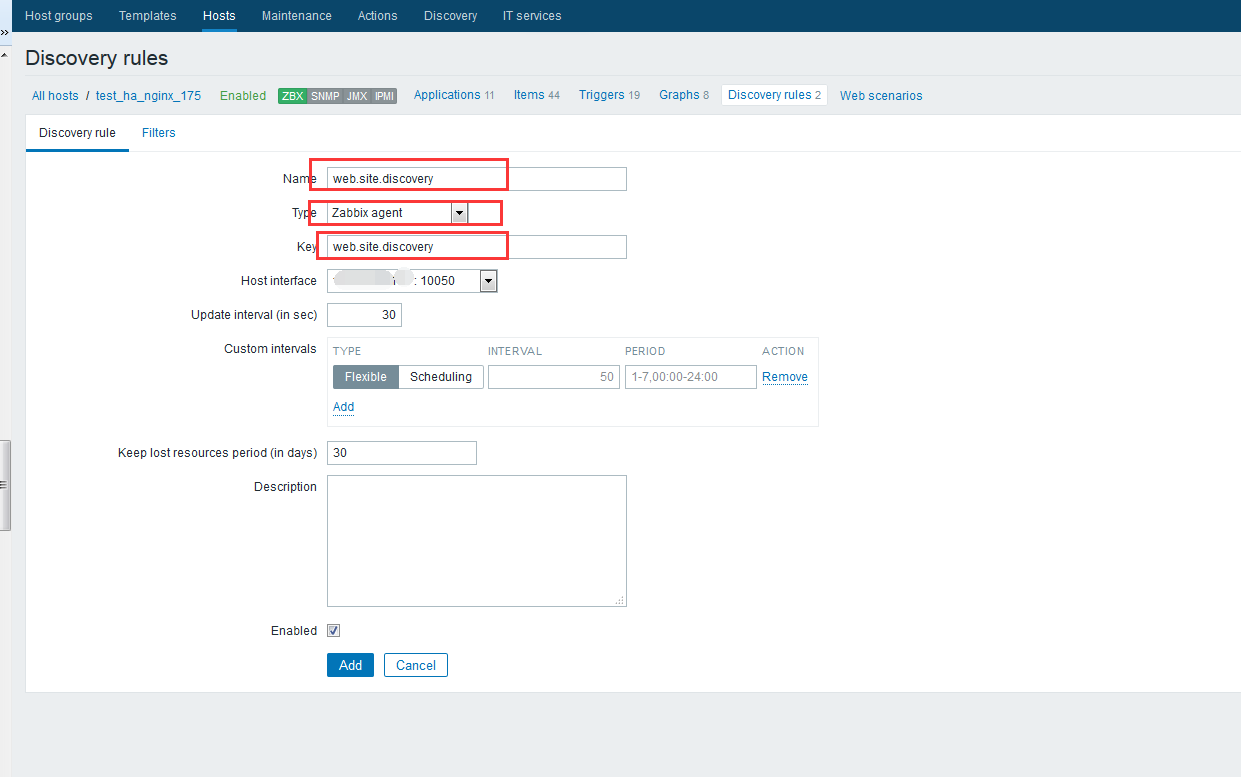
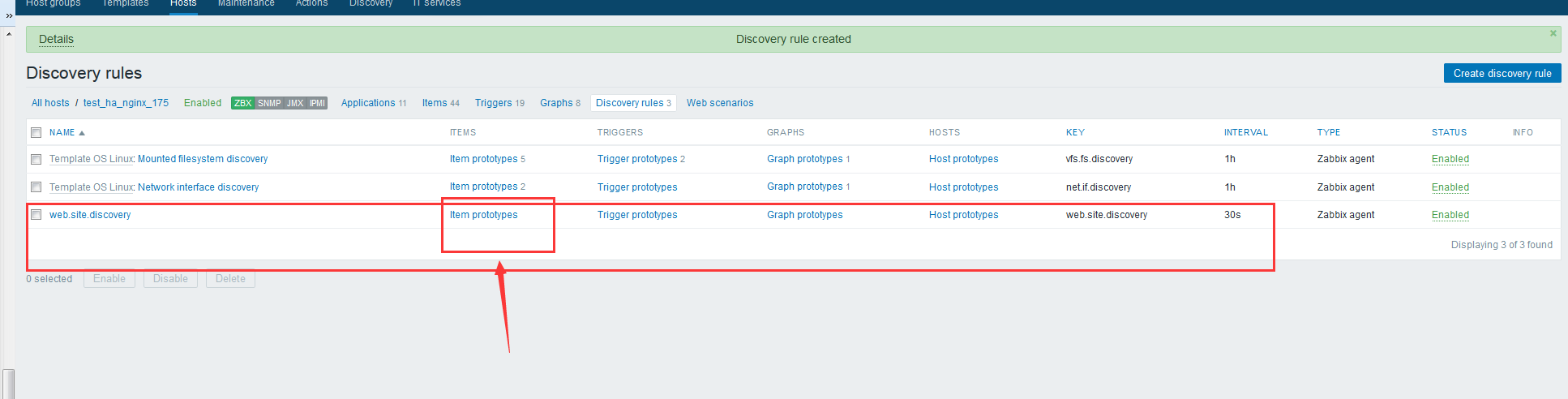
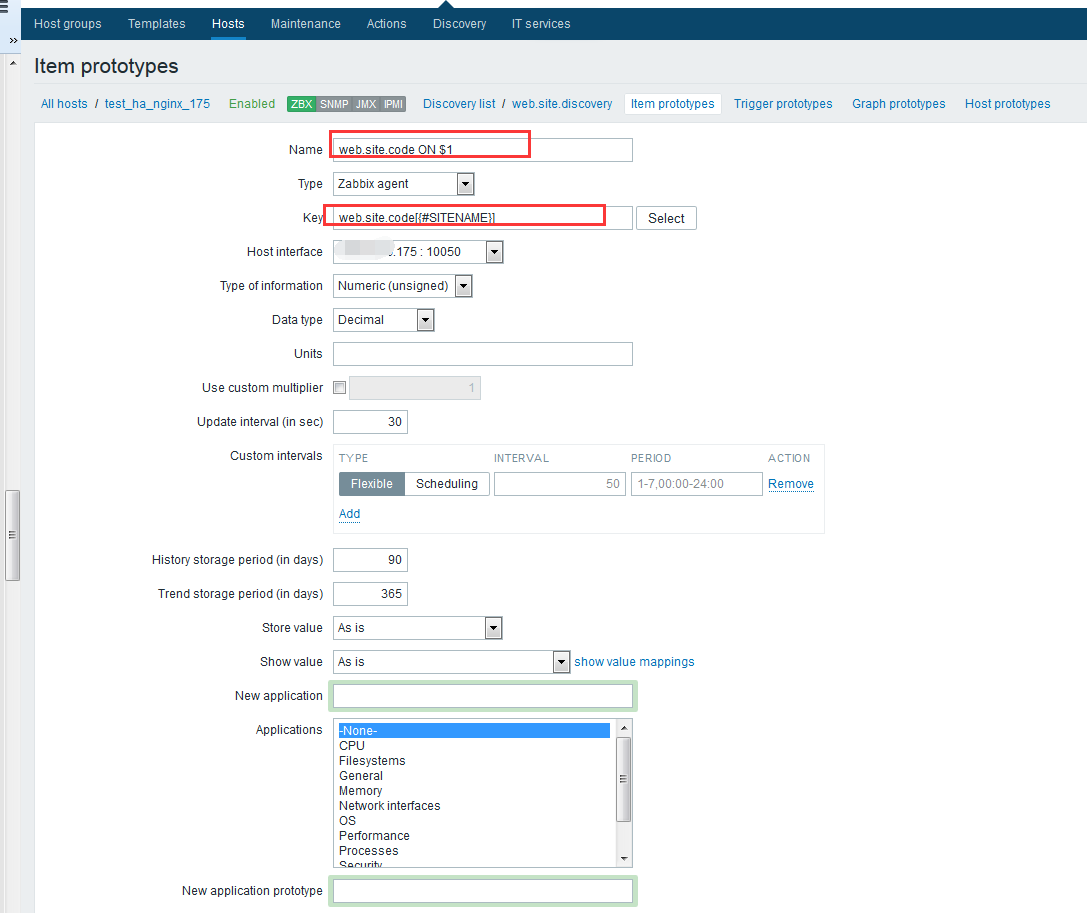
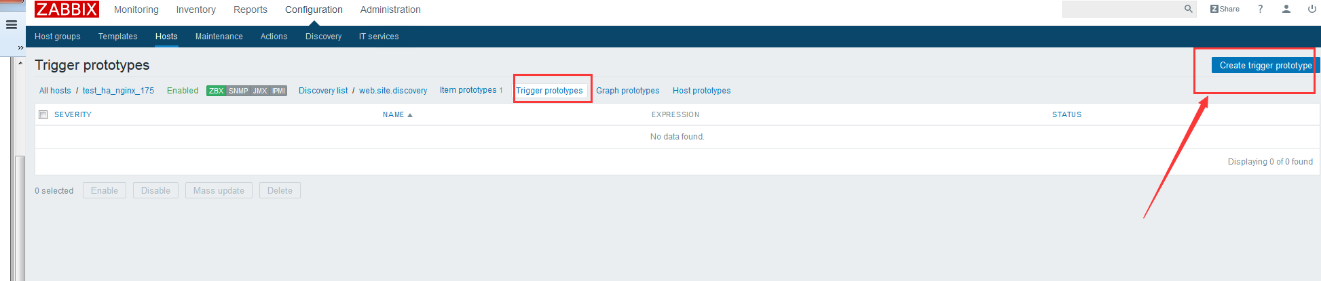
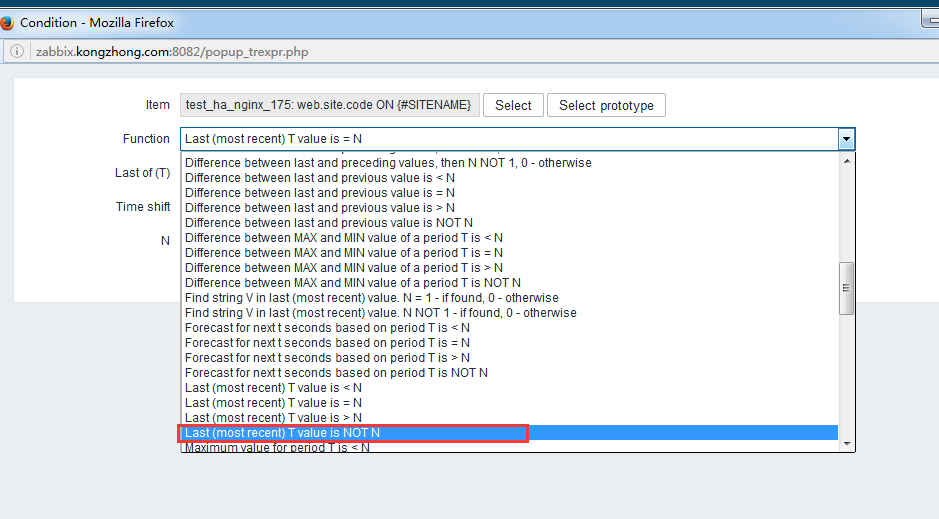
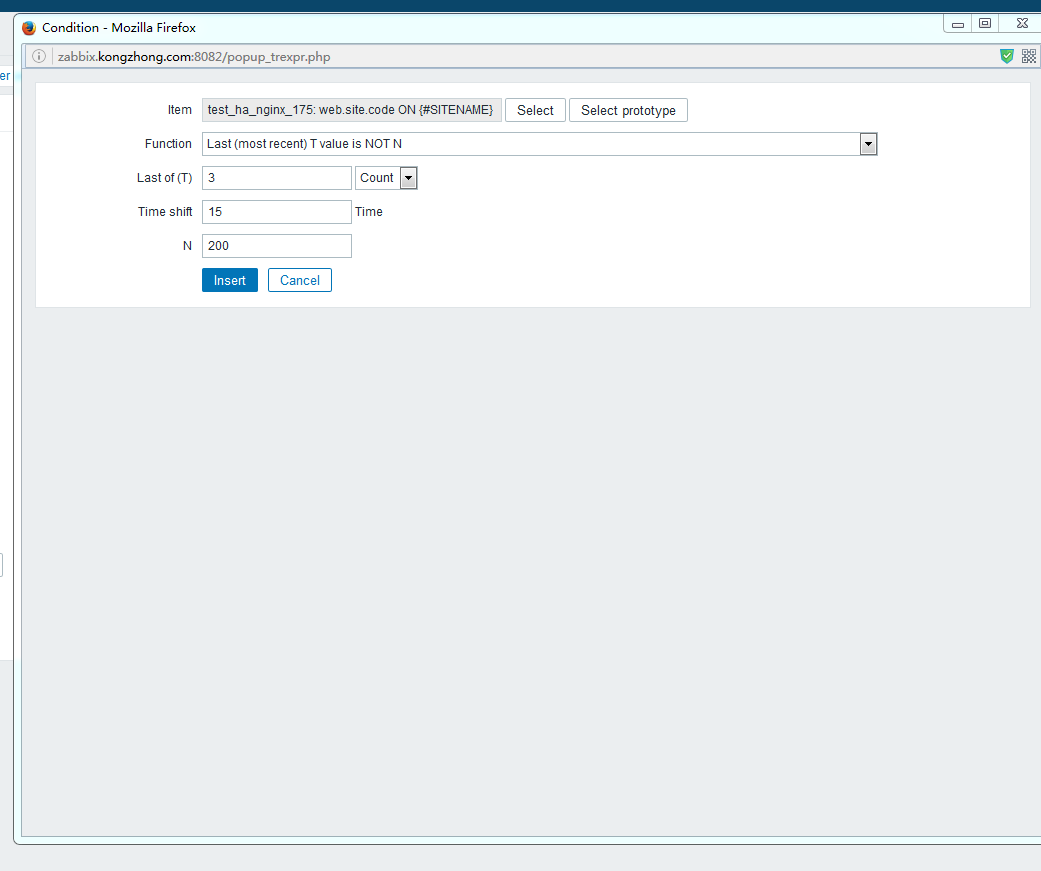
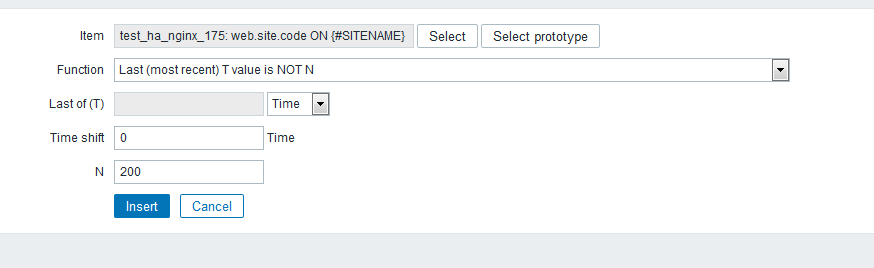
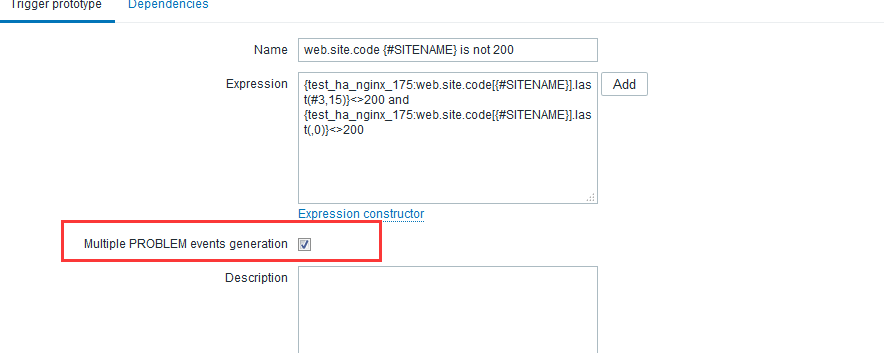
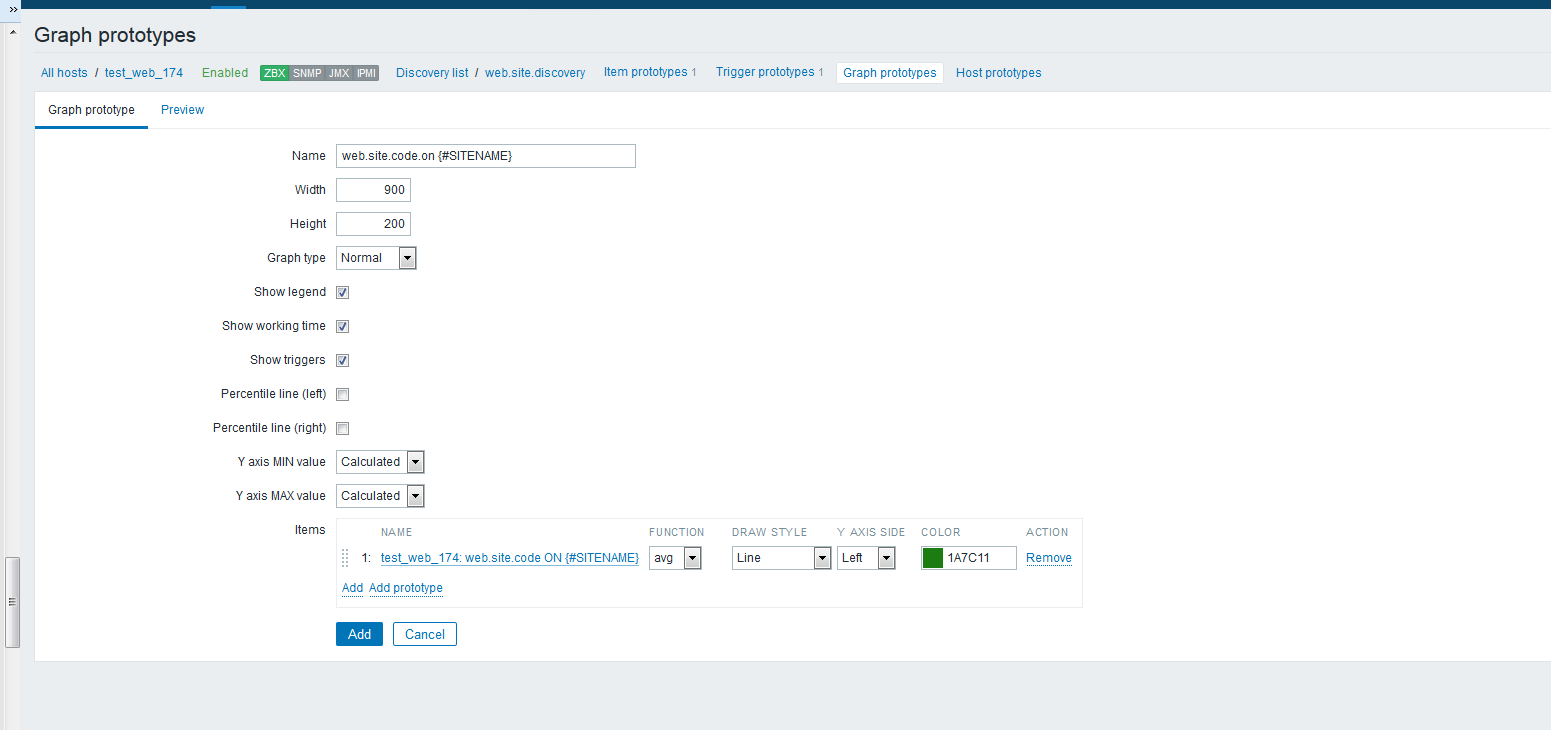
zabbix前端配置 大家直接看图吧
参考文章: