oracle数据导入导出工具sqluldr2/sqlldr
场景概述:
场景:
oracle中有一条大表(物品编码表wpbm),该表中存放了很多种物品信息,大约有4亿条数据,其中最重要的两个字段为wpmc(物品名称),spbm(商品编码),其中某一物品可能对应多个商品编码,如何根据这两个字段对某一物品的各个商品编码计数?
我们都知道,数据库最不擅长的事就是做运算,因为只要涉及到运算,就必然会涉及到在语句中使用某些数学函数,使用函数对于亿级且使用频繁的大表来说必然会影响数据库的效率,执行时间长不说,还可能会出现把数据库拖跨.所以对于这么大的数据量,直接使用count,groupby明显是不可取的,那么就只能使用一些歪方法了,无法在linux环境下用sed,awk等脚本语言对文本进行操作,这又得想办法解决windows下处理文本的效率问题,又一次想感叹Linux的伟大.
思路:
使用离线统计的办法,4亿条数据已经按照某种partition关系建成分区表,按各分区表导出csv文件(最大的一个分区表数据7000万行,2G,需要在使用sqluldr2导出的时候使用size参数分隔成多个小文件,结合第二步需要统计来看size=200M时比较合理),然后结合python做统计,最后把csv再导入库中做分析.
Oracle对于大表的导出使用sqluldr2,数据分析使用python的dataframe库,Oracle导入使用sqlldr
sqluldr导出:
oracle数据的导出大概如下常用方式:
- 界面工具plsql等: 图形界面,傻瓜式,小表的首选
- oracle自带的包ult_file: 需要自己编写业务逻辑
- oracle spool: 没怎么用过
- oracle exp/imp: 导入/导出为dmp包
- sqluldr2: 神器,对于千万级别的大表简直不能更爽
对于亿级的大表,很明显会使用sqluldr2,4亿条数据导出花费了几十分钟,特别酸爽.
最开始的时候想用python的多线程实现了数据的导出,但是由于wpmc字段大部分为中文,且有的记录还包含了各式各样的毫无规律的字符,导致GBK也无法解码,换了各种字符编码都无法解决之后放弃从而转向sqluldr2.
sqluldr2对于大表的优势还是比较明显的,100万条数据也只用了几秒钟的时间,而且还有很多非常有用的参数.
下载地址请移步官网
详细的说明请移步这里
使用方法:
1 | sqluldr264.exe USER=admin/[email protected]:1521/test query="SELECT WP_MC, SPBM FROM TEST PARTITION(SYS_P24)" field=0x-07 file=E:\SYS_P24.csv |
这里只列举几个有用的参数:
- query: 指定查询的语句
- sql: 如果查询语句太长,可写成sql文本里,然后提定sql=test.sql
- field: 可指定字段间的分隔符,默认是,这里最好指定一个字段中不会出现的字符,要不然的话字段分隔就会出现错误,这里也支持用字符的ASCII代码,我一般指0x-07,这个字符基本不会出现在日常打字中,主要的分隔符如下:
- record: 记录分隔符,默认为回车换行,Windows下的换行
- file: 生成的文件,支持csv, txt等常用格式
- size: 如果一个表太大,可按指定大小分隔成多个文件,此时file需使用%b参数,如file=E:\SYS_%b.csv
- batch: 如果指定batch=yes,则100万条记录生成一个文件,此时file需使用%b参数,如file=E:\SYS_%b.csv

4亿条数据用了20来分钟,7000万数据用了5分钟,这个速度已经是比较理想了
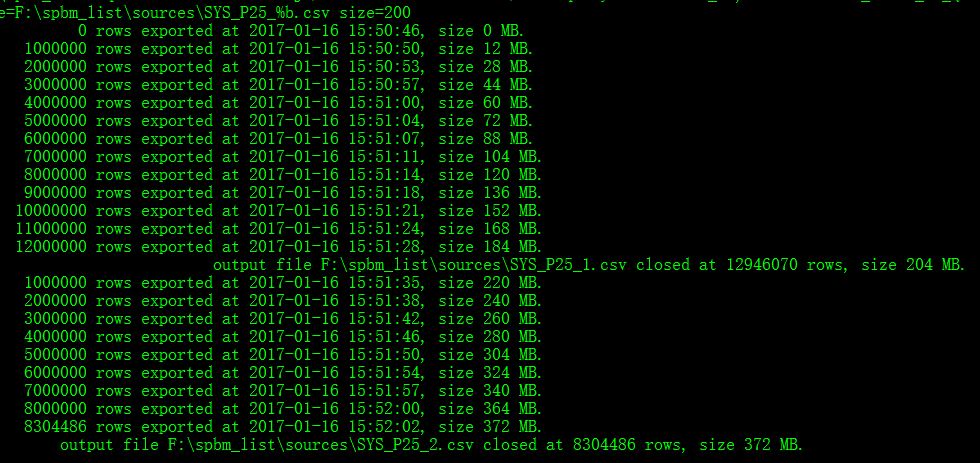
当然sqluldr2还有很多其它好用的参数,比如通过管道连接sqlldr入库、直接指定字符集导出等,感兴趣的可移步这里
数据预处理:
数据已经导出来了,在统计的时候发现有些数据包含空格,这会对统计靠成影响,所以需要先预处理数据,而且通过sqluldr2导出的数据没有经过任何处理,直接统计的时候还是会报gbk无法解码的问题

因此在用python写去除空格的脚本时同时也把不能解码的记录一并处理,因为不需要精确统计,这里选择直接跳过无法解码的记录,毕竟是少数,对于4亿条数据统计来说影响可以忽略不计,因为大的分区表已在sqluldr2中用size参数分隔成了多个文件,python脚本里就直接逐行处理,之前是想用re正则来处理的,但想到每个文件的行数都是千万级,只能一行一行的读取,这种情况下正则的效率是比较低下的,如果能把整个内容放到一个变量中,使用re.sub()的效率还是会比string的快很多.
虽然可以不做这一步,但是后来会发现,这么做是非常有必要的.
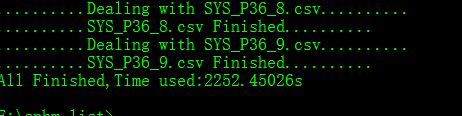
统计完之后,4亿条数据无法解码的行数大致在20000多行.
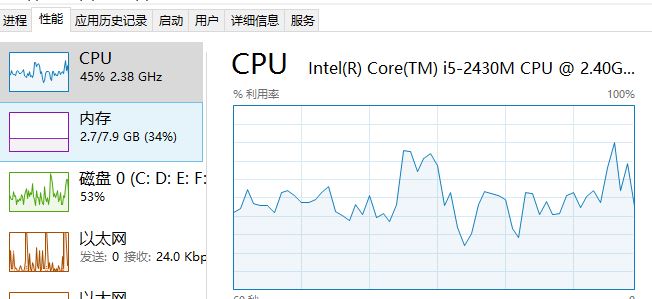
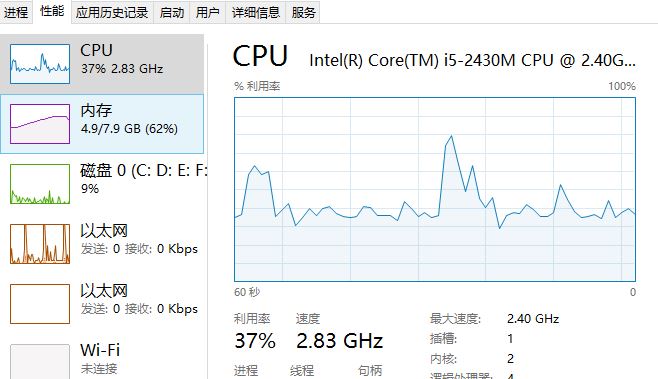
因为是在自己的用了快5年的笔记本上执行的,CPU,内存,IO等性能有限,预处理比较耗磁盘,下图是预处理所花时间及资源使用率:
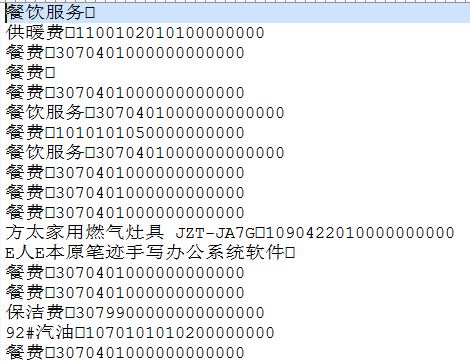
最后生成的CSV文件格式如下:
python之dataframe:
DataFrame是Pandas中的一个表结构的数据结构,包括三部分信息,表头(列的名称),表的内容(二维矩阵),索引(每行一个唯一的标记).
官网文档请移步这里
之前看过一些dataframe的资料,但是没有实际工作用到过它,这次刚好借助这次机会学习下这个python库用于数据统计.
由上图得到了比较纯净的数据之后,开始以(物品[]编码)做为一个整体来统计:
说明:上述代码中to_csv中的sep的分隔符实际为一个[],对应的ASCII代码为0_07(请将_换成x).
通过read_csv指定空格为分隔符,这样就能够保证(物品[]编码)做为一个整体来统计,通过df[col].value_counts()来统计该列出现的次数,使用type可以知道这个方法返回的是一个series,只保存了次数,没有了(商品[]编码),但是我希望得到类似以下结果:
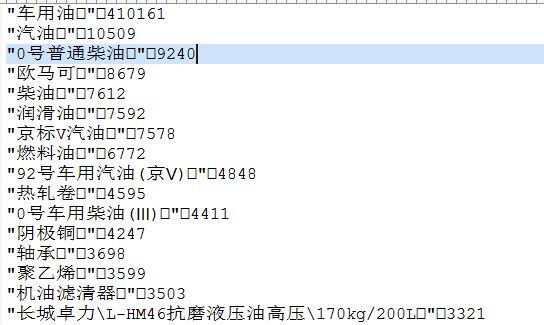
所以必须通过reset_index()重新定义索引,然后指定索引名,这样才能出现如上结果.
应该有更好的办法可以得到如上的结果,通过指定sep=’0x-07’,再使用df.groupby([‘wp’,’bm’].size()直接把两列做为一行进行统计,只不过这里wp为中文,不是数值型,size()方法对非数值型统计直接不显示,所以无法直接用groupby().size()统计.
这个阶段因为要做大量运算,比较消耗内存和CPU,资源使用率及所花时间为:
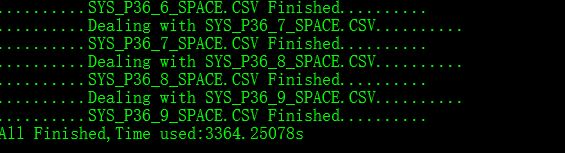
最后得到的是一个CSV文件,再通过sqlldr导入数据库即可.
sqlldr导入:
sqlldr跟sqluldr2是一对利器,速度非常快,使用也很简单.
sqlldr的官方文档请移步这里
启动方法:
1 | sqlldr.exe test/[email protected]:1521/test control=E:\data_to_oracle.ctl log=E:\data_to_oracle.log |
其中控制文件:data_to_oracle.ctl内容如下:
1 | Load DATA |
infile: 导入文件所在路径
badfile: 文件中不能插入数据库的不合法记录
discardfile: 丢弃的数据文件,默认情况不产生,必须指定
append: 插入数据库的模式,主要由以下几种:
- insert –为缺省方式,在数据装载开始时要求表为空
- append –在表中追加新记录
- replace –删除旧记录(用 delete from table 语句),替换成新装载的记录
- truncate –删除旧记录(用 truncate table 语句),替换成新装载的记录
fields: 字段分隔符,默认为,
trailing nullcols: 表的字段没有对应的值时允许为空
使用率及时间为:
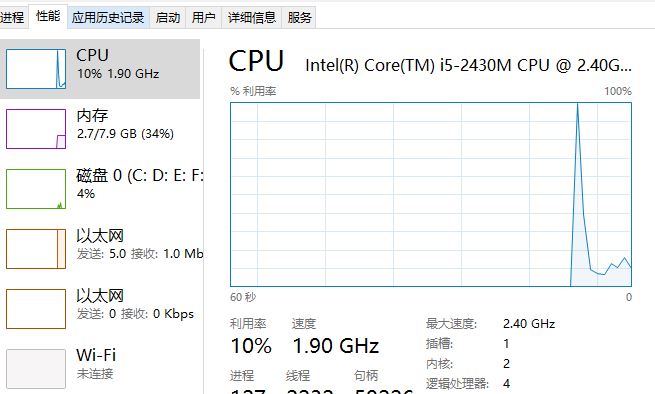
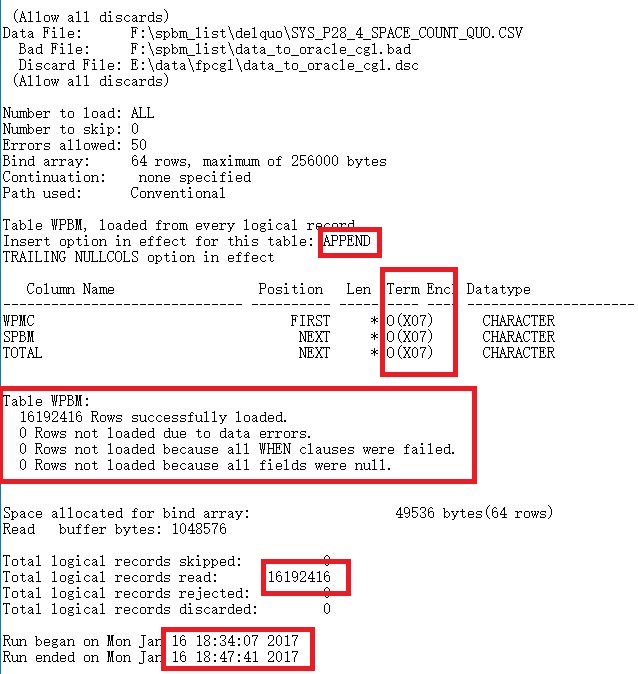
从产生的log可以看到,插入的记录数(这只是数据其中的一部分),时间等信息,这里没有产生错误数据,看来前期数据预处理还是有效果的,虽然多花了点时间,但是很值得.
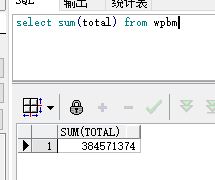
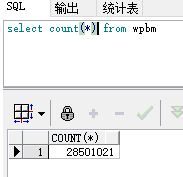
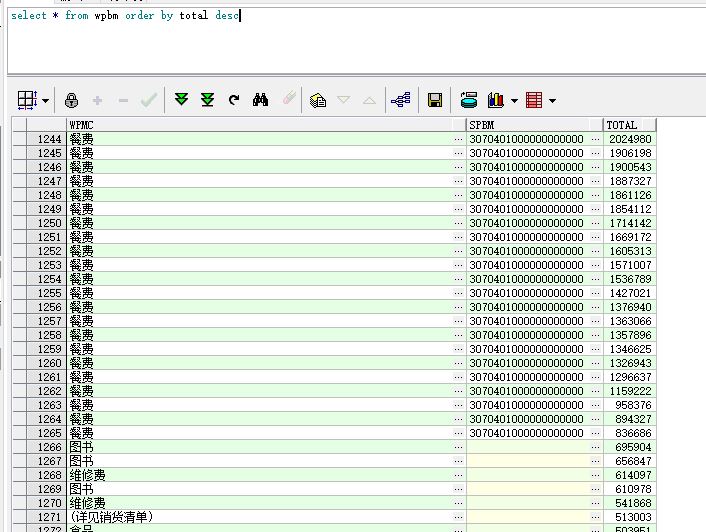
最后到库的数据再做统计就是秒秒钟的事了,Oracle11g添加了几个非常实用的行列互转函数,非常有用
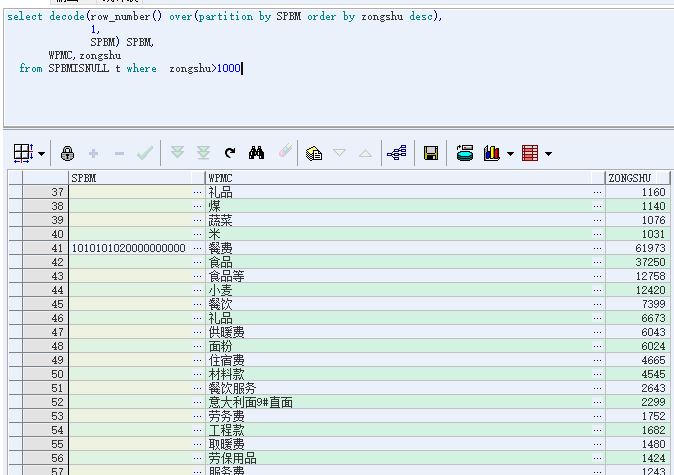
这里按商品编码分类统计物品名称且条数大于1000,sql语句如下:
1 | select decode(row_number() over(partition by SPBM order by zongshu desc), |
番外篇:
Series:
series 可以看做一个定长的有序字典。基本任意的一维数据都可以用来构造 Series 对象:
s = pd.Series(data=[1,2,3,4], index=[‘a’,’b’,’c’,’d’])
如果没有指定index,则会默认生成从0开始递增的索引列
查看信息:
s.values: 查看data信息
s.index: 查看索引的信息
s.sum(): 求data值的和,如果是非数值型,则会把整个data列表组成一个字符串
s.count(): 求data的个数
dataframe
DataFrame 是一个表格型的数据结构,它含有一组有序的列(类似于 index),每列可以是不同的值类型(不像 ndarray 只能有一个 dtype).基本上可以把 DataFrame 看成是共享同一个 index 的 Series 的集合.
DataFrame 的构造方法与 Series 类似,只不过可以同时接受多条一维数据源,每一条都会成为单独的一列:
df = pd.DataFrame([[1,2,3],[4,5,6]],columns=[‘a’,’b’,’c’],index=[0,1])
较完整的 DataFrame 构造器参数为:DataFrame(data=None,index=None,columns=None), columns 即为列名:
查看信息:
df.values: 查看data信息
df.index: 查看索引的信息
df.columns: 查看列名信息
len(df)或len(df.index): 获取数据行数
df.head(5): 显示前5行数据
df.tail(5): 显示后5行数据
选择数据:
取特定的列:
df[‘x’]或得df.x: 那么将会返回columns为x的列,返回的是一个列
取特定的行则通过切片[]来选择:
df[0:3]: 选择的是前3行数
不过须要注意,因为 pandas 对象的 index 不限于整数,所以当使用非整数作为切片索引时,它是末端包含的
通过标签来选择:
df.loc[‘one’]: 则会默认表示选取index为’one’的行,返回一个series
df.loc[:,[‘a’,’b’] ]: 表示选取所有的行以及columns为a,b的列,返回一个dataframe
df.loc[1:3,:]: 对行进行切片,选择的是行
df.loc[:,1:3]: 对列进行切片,选取的是列
df.loc[[‘one’,’two’],[‘a’,’b’]]: 表示选取’one’和’two’这两行以及columns为a,b的列,返回一个dataframe
df.loc[‘one’,’a’]与a.loc[[‘one’],[‘a’]]: 作用是一样的,不过前者只显示对应的值,而后者会显示对应的行和列标签
通过位置来选择数据:
df.iloc[1:2,1:2]: 则会显示第一行第一列的数据(切片后面的值取不到)df.iloc[1:2]: 即后面表示列的值没有时,默认选取行位置为1的数据
df.iloc[[0,2],[1,2]]: 即可以自由选取行位置,和列位置对应的数据
使用条件来选择:
a[a.c>0]: 表示选择c列中大于0的行a[a>0]: 表直接选择a中所有大于0的行
a1[a1[‘one’].isin([‘2’,’3’])]: 表显示满足条件,列one中的值包含’2’,’3’的所有行
缺失值处理:
- df.dropna(axis=0, how=): 去除所有数据中包含空值的行
其中:axis的取值可为0/1来表示不同的维度,0表示按行,1表示按列
how的取值可为any/all: all表示所有的列为空时才会去除,any则表示只要有一列为空即去除
还有一种用法df.dropna(thresh=3): 会在一行中至少有 3 个非 NA 值时将其保留不去除 - df.fillna(value=100): 对缺失的值进行填充
- df.isnull()/df.notnull: 判断是否为空/不为空, 返回一个布尔型数组
- df.drop_duplicates(): 去除重复行
- inplace(): 凡是会对数组作出修改并返回一个新数组的,往往都有一个 replace=False 的可选参数.如果手动设定为 True,那么原数组就可以被替换.
常用方法:
Apply(): 对数据应用函数,如:
a.apply(lambda x:x.max()-x.min()): 表示返回所有列中最大值-最小值的差
sort_index(ascending=False): 按照索引列排序,默认是以升序排序
groupby(‘columns’): 这个方法不会返回数据,必须连同如sum(),mean(),count()等函数一直使用
如:df.groupby([‘a’,’b’]).sum(): 对列a,b进行分组然后再进行求和
df.groupby([‘a’]).size(): 对各个a下的数目进行计数,如果是字符串的话则不显示
is_unique(): 判断值是否唯一
其它常用方法有:
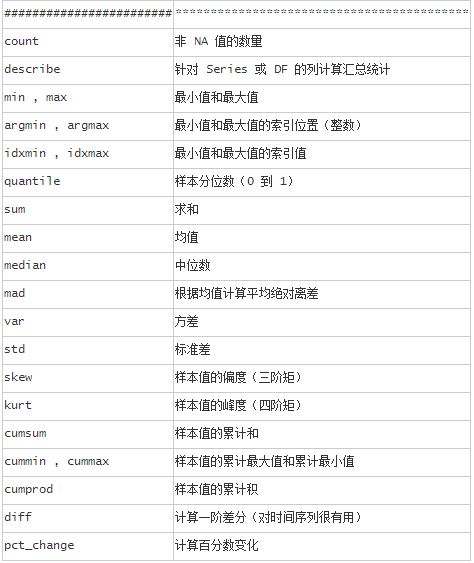
dataframe还有一些其它高级的应用,比如Concat(),join(),append()等,以后有时间再研究下!
read_csv()/to_csv():
read_csv的参数详解请移步这里
中文说明请移步这里
这两个方法比较简单,这里就不展开写了.
收工!